

DeepSeek Janus-Pro 应用代码与图片链接实践

RAG(Retrieval-Augmented Generation)是一种结合了检索和生成的方法,旨在提高自然语言处理任务的性能。与传统的预训练和微调方法相比,RAG的优势在于能够利用外部知识源,如知识图谱或文档数据库,以增强模型的理解和生成能力。通过检索相关信息,RAG能够减少对大规模预训练数据的依赖,从而降低计算成本。这种方法在处理实时性和专业性较强的任务时,表现尤为出色。
RAG系统的第一步是检索阶段。在这个阶段,系统会根据用户输入的查询或者问题,从外部知识源中检索相关信息。这些知识源可以是各种格式的文档库、知识图谱或者结构化数据库。通过高效的检索算法,RAG能够迅速找到与查询相关的内容,从而为后续的生成阶段提供必要的上下文支持。
在检索到相关信息后,RAG将这些信息与原始输入结合,形成一个更丰富的上下文。这一过程被称为增强阶段。通过增强上下文,模型可以更好地理解输入内容的背景和细节,这对于生成准确回答至关重要。增强阶段的核心在于如何有效地将检索到的信息与输入问题进行整合,以便为生成阶段提供最相关的上下文。
在生成阶段,模型基于增强后的上下文生成回答或文本。这一阶段依赖于自然语言生成技术,其目标是生成符合上下文逻辑且准确的回答。通过RAG,生成的回答不仅依赖于模型的内在知识,还包括从外部获取的最新信息,从而提高回答的准确性和时效性。
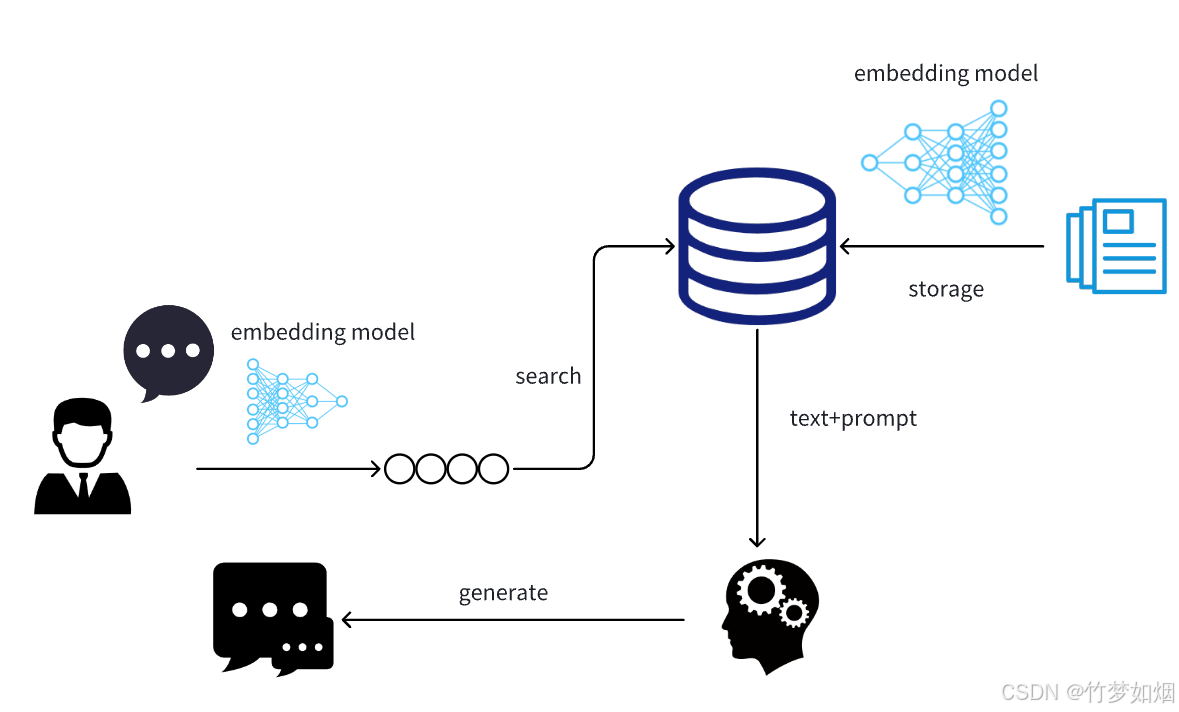
RAG系统在多个自然语言处理任务中得到了广泛应用。以下是一些典型的应用场景:
RAG系统可以用于构建高效的问答系统。通过检索相关文档中的信息,RAG能够回答用户提出的各种问题,尤其是涉及实时信息的问题。借助外部知识库,RAG能提供更为详尽和准确的答案。
在内容生成和摘要任务中,RAG通过检索相关背景信息,帮助模型生成更为连贯和信息丰富的内容。这对于需要生成长文本或复杂文本任务尤为重要。
RAG系统还可以用于知识图谱问答,通过结合知识图谱中的信息,RAG能生成基于结构化数据的精确答案,支持更复杂的查询。
阿里通义 ModelScope 提供了实现 RAG 系统的基础架构。在 ModelScope 中,用户可以通过预定义的接口和模块,快速构建属于自己的 RAG 系统。
在 Windows 系统下,用户需要配置基本的 Python 环境,以支持 RAG 系统的部署。可以参考以下命令进行环境配置:
pip install torch==1.13.0 torchvision==0.14.0 torchaudio==0.13.0 -f https://download.pytorch.org/whl/cu117/torch_stable.html通过 ModelScope,用户可以轻松下载和加载各种预训练模型,例如用于向量化的 BERT 模型和用于文本生成的大模型。以下是下载和加载模型的示例代码:
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_dir = snapshot_download('qwen/Qwen1.5-0.5B')
model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_dir)在 RAG 系统中,向量化是一个关键步骤。使用向量化模型,可以将文本数据转换为数值向量,以便于后续的检索和匹配。以下是一个使用 HuggingFace 提供的 SentenceTransformer 进行向量化的示例:
from sentence_transformers import SentenceTransformer
hug_path="jina-embeddings-v3"
hug_model=SentenceTransformer(hug_path,trust_remote_code=True)
texts=["今天的天气非常好,适合外出","今天有什么新鲜事吗?"]
embeddings=hug_model.encode(sentences=texts)通过将检索到的上下文信息与用户查询结合,RAG 系统可以生成更为准确的回答。以下是一个基于 LangChain 和 ModelScope 的实现示例:
from langchain.schema.runnable import RunnablePassthrough
from langchain_community.chat_models.tongyi import ChatTongyi
chatLLM = ChatTongyi(streaming=False)
retriever = vectordb.as_retriever()
rag_chain = ({"context": retriever, "question": RunnablePassthrough()} | prompt | chatLLM)
query = "介绍一下RAG系统"
rag_chain.invoke(query)随着技术的发展,RAG 系统将不断优化其检索和生成能力。未来,RAG 有望在更多领域中发挥作用,包括医疗、法律和教育等行业。借助更为强大的知识库和检索算法,RAG 系统将能够提供更为智能和高效的解决方案。
问:RAG 系统与传统 NLP 方法的主要区别是什么?
问:如何在 ModelScope 中部署 RAG 系统?
问:RAG 系统的应用领域有哪些?






