

Node.js 后端开发指南:搭建、优化与部署

在人工智能领域,RAG(Retrieval-Augmented Generation)技术通过结合检索和生成两个环节,为处理复杂的语言任务提供了强大的支持。本文将深入探讨RAG技术的四种直接检索结构:线性、条件、分支和循环模式,并分析其在实际应用中的优势与挑战。同时,我们将讨论如何通过这些结构优化数据检索流程,并结合实际代码示例和图片链接,为读者提供直观的技术理解。
线性模式是RAG直接检索中最直接、最简单的结构。在这种模式下,系统按照预设的顺序执行一系列操作,从查询转换到检索,再到生成答案。这种模式适用于简单的查询,其中查询的意图明确,且数据结构单一。
线性模式的特点是操作的顺序性和确定性。每个步骤都是基于前一个步骤的结果进行的,没有额外的条件判断或循环操作。这种模式的优势在于其简单性和可预测性,但在处理复杂查询时可能会受到限制。
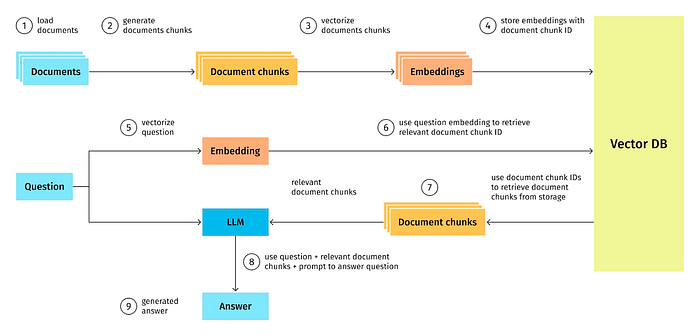
线性模式适用于那些查询意图明确、数据结构简单的情况。例如,在简单的问答系统中,用户提出一个问题,系统直接检索知识库中的答案并返回给用户。
条件模式在RAG直接检索中引入了条件判断,使得检索过程可以根据不同的条件动态选择不同的检索路径。这种模式适用于查询意图不明确或数据结构复杂的情况。
条件模式的特点是灵活性和动态性。系统可以根据用户的查询内容和上下文信息,动态选择最佳的检索路径。这种模式的优势在于其能够处理更复杂的查询,但同时也增加了系统的复杂性。
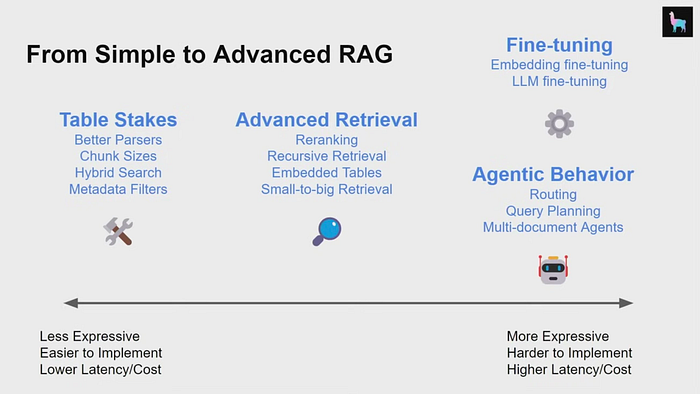
条件模式适用于那些需要根据用户查询的上下文信息动态调整检索策略的场景。例如,在复杂的问答系统中,系统可能需要根据用户的问题类型(如事实查询、解释查询等)选择不同的检索策略。
分支模式在RAG直接检索中允许系统同时沿着多个路径进行检索,以增加检索结果的多样性和覆盖度。这种模式适用于需要从多个数据源中检索信息的情况。
分支模式的特点是并行性和多样性。系统可以同时从多个数据源中检索信息,然后将检索结果合并以生成最终答案。这种模式的优势在于其能够提供更全面的信息,但也增加了系统的计算负担。
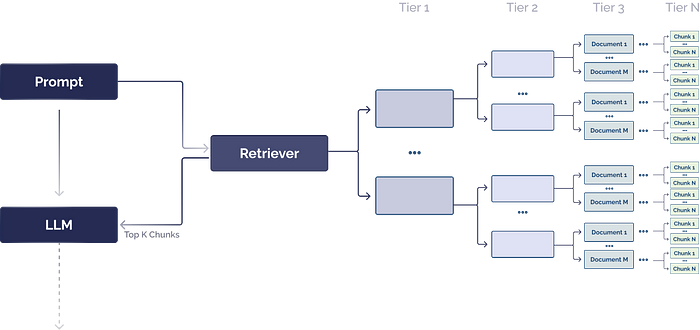
分支模式适用于那些需要从多个数据源中检索信息以提供全面答案的场景。例如,在推荐系统中,系统可能需要从用户行为数据、商品属性数据等多个数据源中检索信息,以生成个性化的推荐结果。
循环模式在RAG直接检索中引入了迭代机制,允许系统在生成过程中多次检索和生成,以优化答案的质量。这种模式适用于需要多次迭代以精练答案的情况。
循环模式的特点是迭代性和优化性。系统可以在生成过程中多次检索和生成,以优化答案的质量。这种模式的优势在于其能够提供更精确的答案,但也增加了系统的计算负担和响应时间。
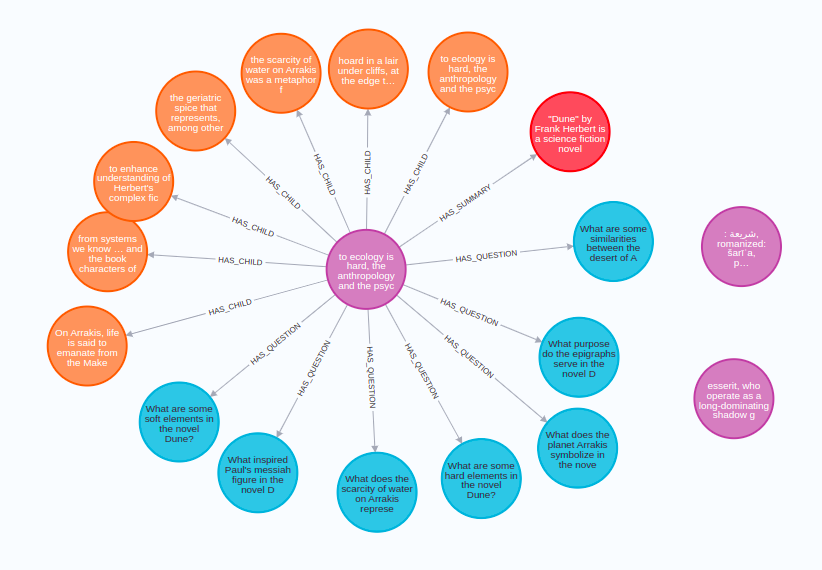
循环模式适用于那些需要多次迭代以精练答案的场景。例如,在自动摘要系统中,系统可能需要多次迭代以生成更精确的摘要。







