

PixverseAI互动功能(HUG)在AI拥抱视频生成中的应用

Qwen2.5-Max 是阿里巴巴推出的尖端人工智能模型,以其庞大的参数量和卓越的性能在全球范围内引起了广泛关注。在本文中,我们将深入分析 Qwen2.5-Max 的参数量及其在人工智能领域的意义,探索其工作原理、训练方法、基准测试成果,以及如何访问和使用这个强大的工具。
Qwen2.5-Max 模型的参数量达到了惊人的 20 万亿个代币,这一庞大的数字为其提供了强大的学习和推理能力。它采用了专家混合(MoE)架构,这种架构允许模型在处理不同任务时,仅激活最相关的部分,从而最大化计算效率和资源利用率。这种架构类似于一个拥有多位专家的团队,每位专家专注于特定领域的知识,从而在需要时提供最优质的答案。
在传统的人工智能模型中,所有参数在每个任务中都会被激活,这通常导致不必要的计算开销。而 Qwen2.5-Max 通过 MoE 架构,仅在需要时激活相关参数。这种选择性激活不仅提高了计算效率,还显著降低了资源消耗,使得 Qwen2.5-Max 能够在保持强大性能的同时更具可扩展性。
MoE 架构的另一个显著优势在于其扩展性。通过选择性激活,Qwen2.5-Max 能够在不显著增加计算成本的情况下扩展参数量,从而在与其他密集模型(如 GPT-4o 和 Claude 3.5 Sonnet)的竞争中占据优势。
Qwen2.5-Max 的训练涵盖了 20 万亿个代币,等同于大约 15 万亿个单词。这一庞大的数据集允许模型在广泛的主题和语境中汲取知识。然而,仅依靠原始数据并不足以打造高质量的人工智能模型,因此阿里巴巴对训练数据进行了微调。
在 SFT 过程中,人工标注员为模型提供高质量的回复示例,指导模型生成更加准确和有用的输出。这一过程帮助 Qwen2.5-Max 提高了对复杂问题的理解和解决能力。
RLHF 方法则通过人类反馈进一步优化模型,使其回答更加自然且符合人类偏好。这种方法确保了 Qwen2.5-Max 在不同情境下都能提供贴近人类思维的答案。
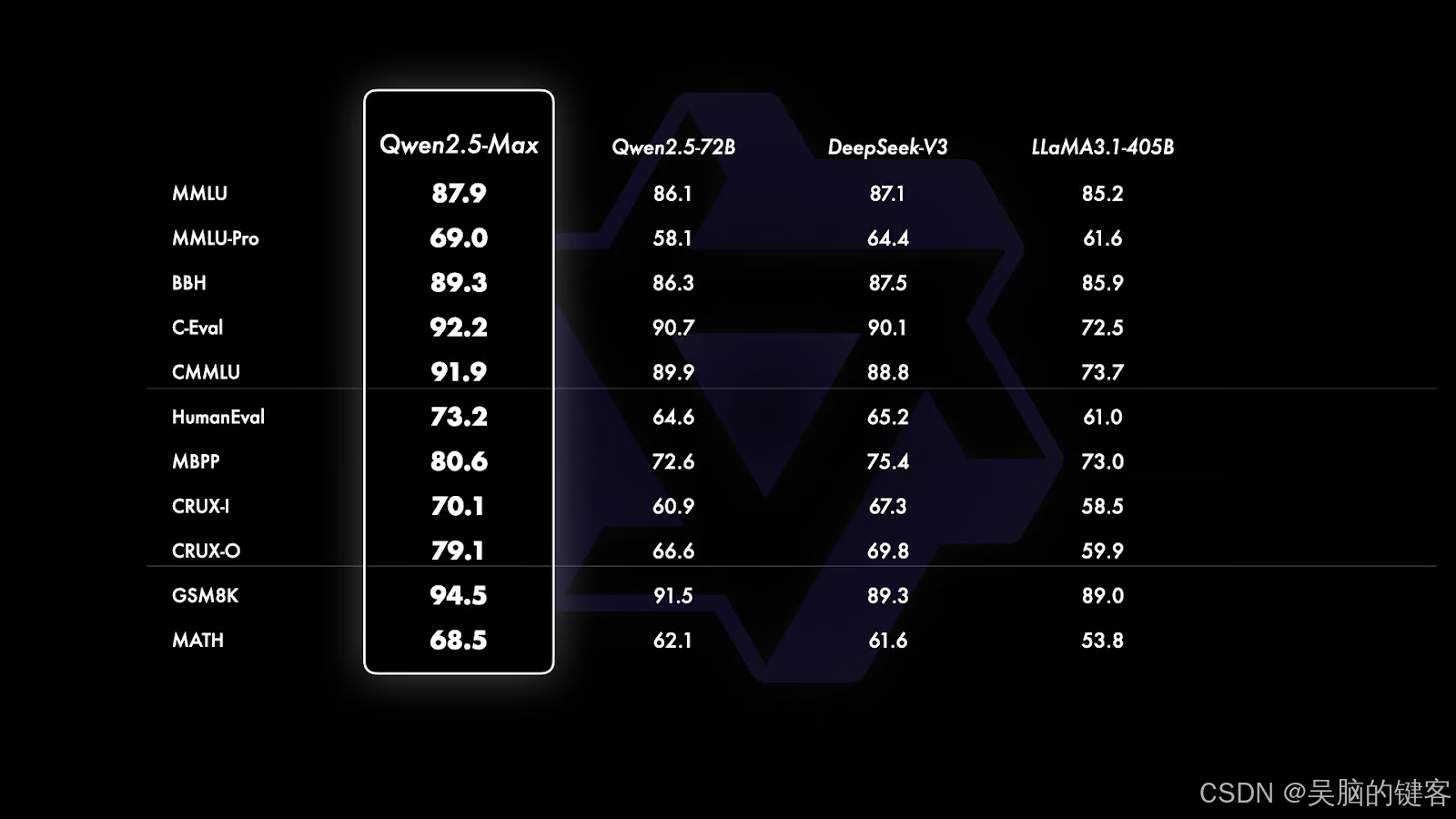
Qwen2.5-Max 在多个国际基准测试中表现卓越,甚至超越了一些国际知名模型。
在指令模型基准中,Qwen2.5-Max 针对对话、编码和常识任务进行了微调,与 GPT-4o、Claude 3.5 Sonnet 等模型相比,Qwen2.5-Max 在 Arena-Hard 和 LiveBench 等测试中取得了显著的领先地位。

在开放模型的比较中,Qwen2.5-Max 在常识和语言理解、编码问题解决、数学问题解决等多个基准测试中处于领先地位,尤其在数学推理能力方面表现突出。
访问 Qwen2.5-Max 非常简单,无需复杂设置即可免费试用。
用户可以通过 Qwen Chat 平台直接在浏览器中与模型互动。只需选择 Qwen2.5-Max 模型,即可开始体验。
对于开发者,Qwen2.5-Max 可通过阿里云 Model Studio API 访问。需要注册阿里云账户,激活 Model Studio 服务,并生成 API 密钥。由于 API 格式与 OpenAI 类似,整合过程相对简单。
Qwen2.5-Max 是阿里巴巴的最新人工智能强者,其庞大的参数量和先进的架构使其在国际舞台上占据一席之地。虽然它没有开源,但用户可以通过 Qwen Chat 和阿里云 API 进行体验和测试。未来,随着阿里巴巴在 AI 领域的持续投入,Qwen2.5-Max 的潜力和应用场景将更加广泛。
Qwen2.5-Max 是开源的吗?
如何通过阿里云访问 Qwen2.5-Max?
Qwen2.5-Max 的参数量有多大?
Qwen2.5-Max 的 MoE 架构有何优势?
Qwen2.5-Max 在哪些基准测试中表现优异?






