

PixverseAI互动功能(HUG)在AI拥抱视频生成中的应用

Qwen2.5-Max 是当前人工智能领域一项重要的技术进展。其在多项基准测试中表现出色,超越了许多现有的模型。这些测试涵盖了包括 MMLU-Pro、LiveCodeBench、LiveBench 和 Arena-Hard 等在内的多个领域。通过这些测试,我们可以看到 Qwen2.5-Max 在知识水平、编程能力和综合能力方面的卓越表现。
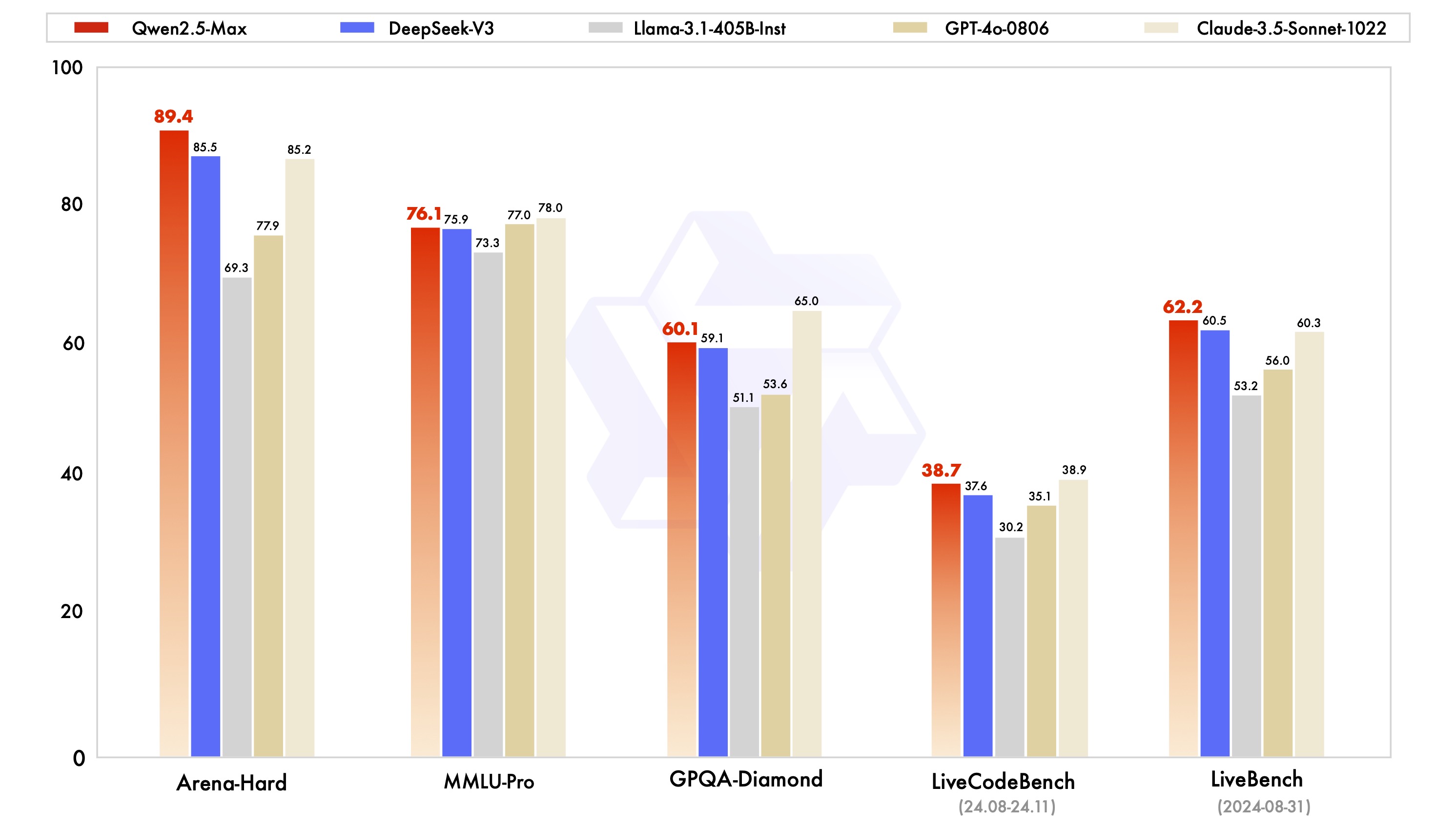
在与其他模型的比较中,Qwen2.5-Max 展现了其在指令模型和基座模型中的领先优势。特别是在 Arena-Hard 和 LiveBench 等挑战性基准中,其表现甚至超越了一些闭源的知名模型,如 GPT-4o 和 Claude-3.5-Sonnet。这显示了 Qwen2.5-Max 在复杂任务处理上的强大能力。
Qwen2.5-Max 提供了多种访问方式,用户可以通过 Qwen Chat 直接与模型对话,也可以通过 API 进行集成。其 API 与 OpenAI API 兼容,使得开发者可以轻松地将其嵌入到现有应用中。以下是使用 Python 调用 Qwen2.5-Max 的示例代码:
from openai import OpenAI
import os
client = OpenAI(
api_key=os.getenv("API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen-max-2025-01-25",
messages=[
{'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'user', 'content': 'Which number is larger, 9.11 or 9.8?'}
]
)
print(completion.choices[0].message)Qwen2.5-Max 的发展并未止步于此。团队计划继续扩大数据规模和模型参数,以提升模型的智能水平。此外,强化学习的应用也是未来发展的重要方向。通过这些努力,Qwen2.5-Max 希望能在不久的将来实现超越人类智能的目标。
Qwen2.5-Max 的成功离不开开源社区的支持。通过 GitHub,用户可以获取到 Qwen2.5-Max 的代码并进行深度学习模型的构建和改进。以下是 Qwen2.5 的主要开源模型及其版本:
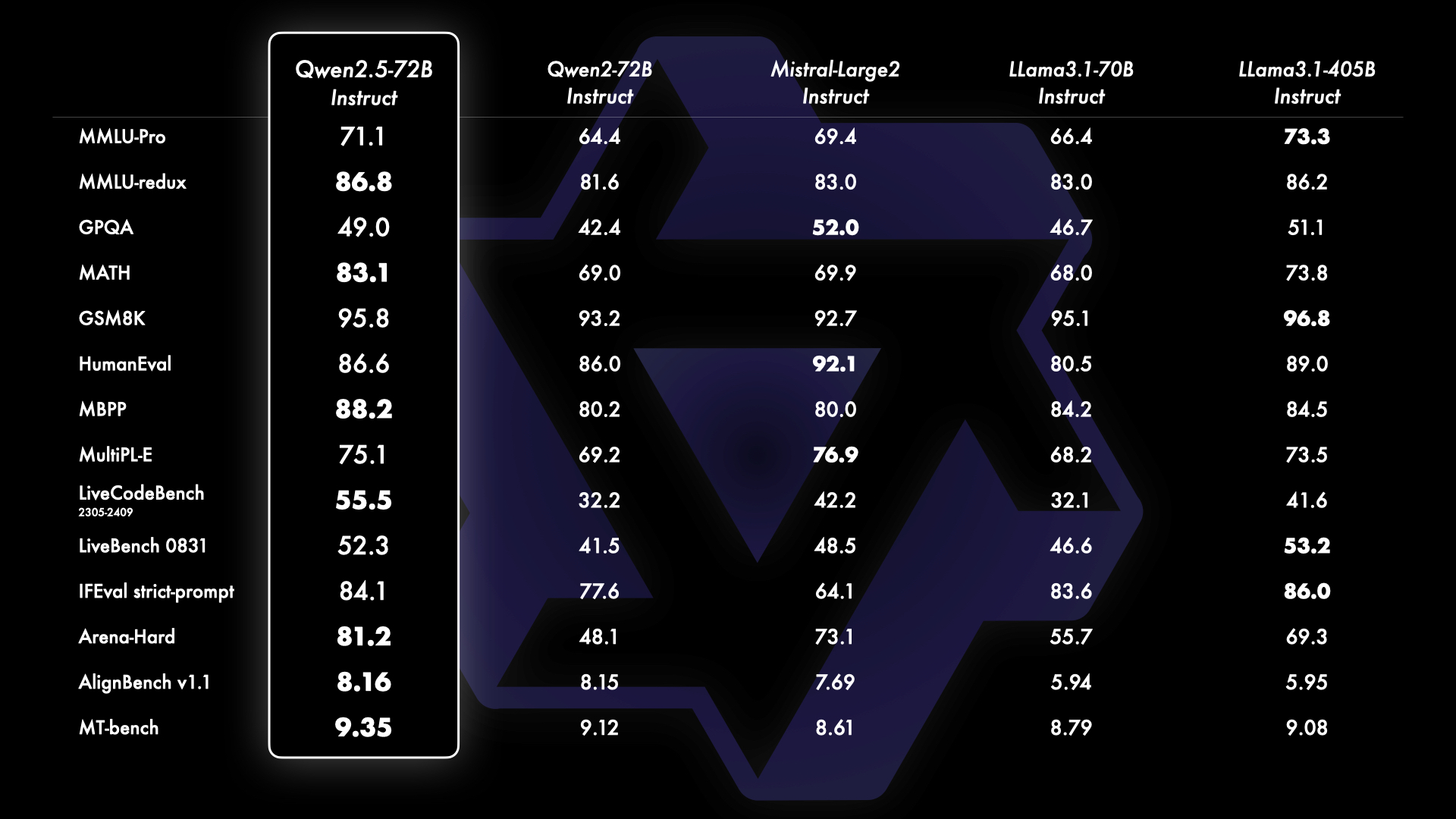
为了展示 Qwen2.5 的能力,我们用最大的开源模型 Qwen2.5-72B 进行了基准测试。结果显示,其在多个测试中均表现优异,尤其是在指令微调后的版本中,Qwen2.5-72B 展现了强大的综合能力和人类偏好的适应性。
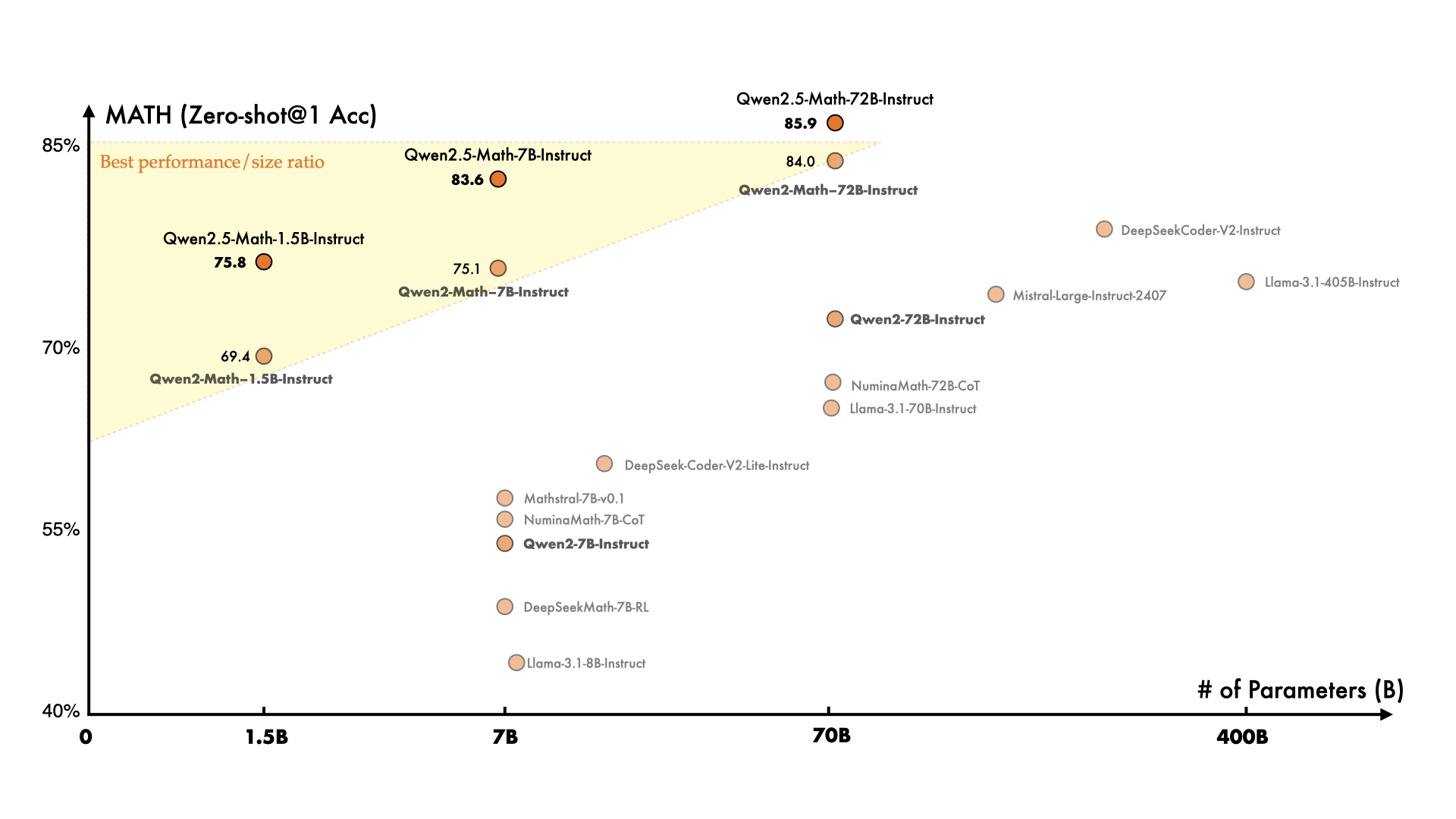
Qwen2.5 还推出了专用于编程和数学领域的模型,分别为 Qwen2.5-Coder 和 Qwen2.5-Math。与其前身相比,这些模型在相关领域的数据上进行了更大规模的训练,并在推理能力上得到了显著提升。
用户可以通过阿里云百炼平台便捷地使用 Qwen2.5 的 API。以下是通过 Hugging Face Transformers 库来使用 Qwen2.5 的示例代码:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen2.5-7B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]Qwen 系列的成功离不开开源社区的支持。许多开发者通过 GitHub 和其他平台对 Qwen2.5 进行了贡献和改进。我们要向所有为 Qwen 做出贡献的团队和个人表示衷心的感谢。
问:Qwen2.5-Max 与其他模型相比有什么优势?
问:如何通过 API 访问 Qwen2.5-Max?
问:Qwen2.5 的开源版本有哪些?






