

大模型RAG技术:从入门到实践

千问系列模型是阿里云研发的大语言模型,其基于Transformer架构进行训练,旨在提供卓越的语言理解与生成能力。千问模型不仅涵盖多种语言,还扩展到专业书籍、代码等领域的数据预训练。通过不断的版本迭代,千问模型在多语言能力、数据处理、系统对接等方面展现出强大的适应性和灵活性。
千问2.5是千问系列的最新版本,具备从5亿到720亿不等的参数规模。它在大规模数据集上进行预训练,包含多达18T个Token,知识涵盖面广泛,尤其在编码和数学能力上有了显著提升。其中,Qwen2.5-Coder和Qwen2.5-Math等专业领域的专家模型,在其各自的领域内表现出媲美大型语言模型的竞争力。例如,Qwen2.5-Math在数学基准测试中取得了优秀的成绩,甚至在复杂问题解决上表现出色。
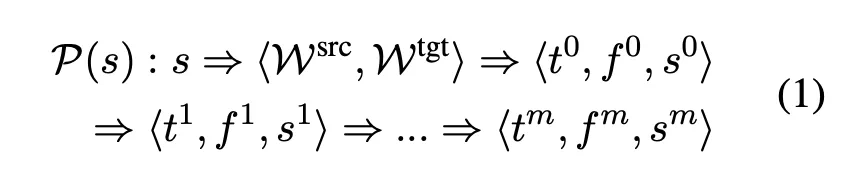
千问1.5大幅提升了与人类偏好的一致性,并增强了多语言能力和外部系统链接能力。其在英文MT-Bench上表现优异,这得益于其对话能力的改进。千问1.5的API服务为开发者提供了便捷的接入方式,使得多语言处理更为高效。
CodeQwen1.5是千问1.5的代码专用版本,它在大量代码数据上进行训练,支持多达92种编程语言,能够处理长达64K的上下文信息。在SQL生成和Bug修复等方面,CodeQwen1.5显示出卓越的能力,成为开发者的有力助手。
长思维链(Chain of Thought, CoT)是语言模型在推理任务中的一种新兴技术。其通过模拟人类思维过程,逐步展开推理步骤,以达到更准确的结果。在数学和编码等任务中,CoT的有效性已被验证。
微信AI研究团队将CoT引入到神经机器翻译中,开发出DRT-o1模型。该模型通过翻译者、顾问和评估者三个智能体的协作,模拟长思考过程,从而提升翻译质量。尤其是在涉及明喻和隐喻的文学翻译中,DRT-o1表现出色。
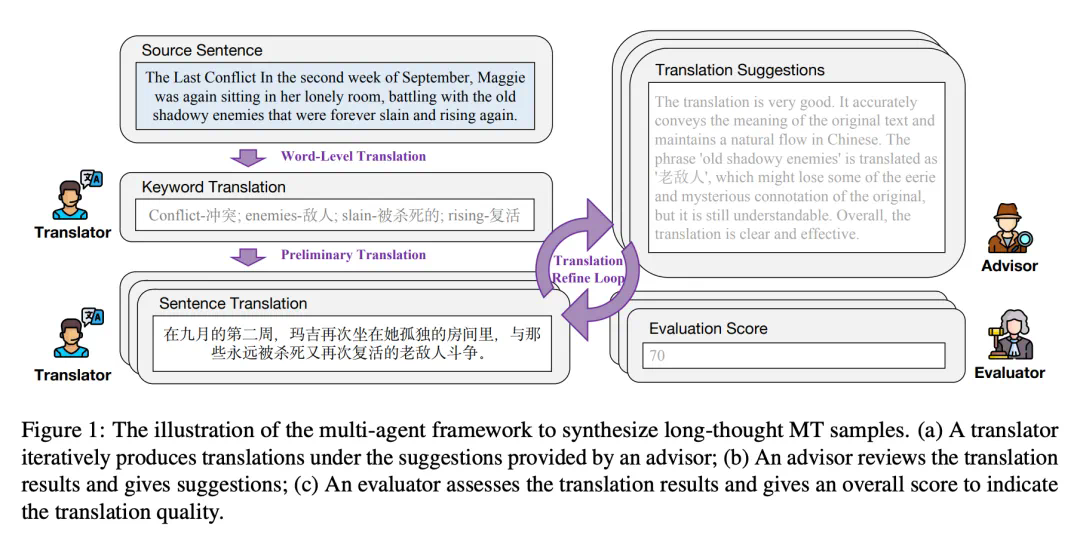
多智能体框架由翻译者、顾问和评估者组成。翻译者负责生成初步翻译,顾问提供改进建议,评估者根据预定义标准评估翻译质量。通过多次迭代,模型在翻译过程中逐步优化结果。
千问COT模型结合了多种推理技术,包括Chain-of-Thought、Program of Thought和Tool-Integrated Reasoning。这些技术使模型在处理复杂任务时,能够更好地模拟人类的思维过程。
TIR(Tool-Integrated Reasoning)技术通过工具的集成和使用,帮助模型在推理过程中获取更多信息。这种方式提升了模型在数学和编码任务中的表现。
在DRT-o1的研究中,研究者从文学书籍中提取含有比喻或隐喻的句子,并设计了多智能体框架进行长思考过程的合成。最终得到22264个长思考机器翻译样本,为模型的训练提供了丰富的数据支持。
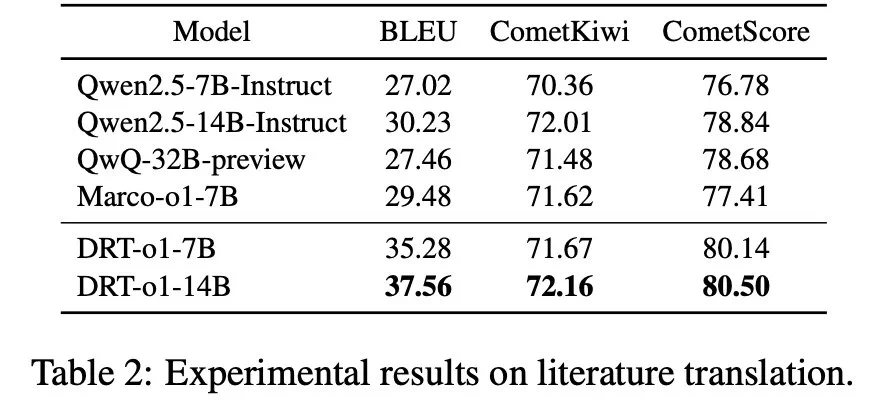
通过实验,研究者验证了DRT-o1在机器翻译中的有效性。与Qwen2.5-7B-Instruct和Qwen2.5-14B-Instruct相比,DRT-o1在BLEU、CometKiwi和CometScore等指标上均有显著提升。
实验中使用的模型包括Qwen2.5-7B-Instruct和Qwen2.5-14B-Instruct,结果表明,DRT-o1在多项指标上优于其他模型,尤其是在长思考过程的模拟上,表现出色。
随着千问COT的不断发展,未来的应用场景将更加广泛。从教育到科研,甚至是需要复杂问题解决的领域,千问COT都将发挥重要作用。通过进一步的技术创新,千问COT有望在全球人工智能领域继续引领潮流。
问:什么是千问COT模型?
问:千问COT如何在翻译中应用?
问:千问2.5与千问1.5有何不同?
问:如何使用千问COT模型进行开发?
问:千问COT的未来发展方向是什么?







