

Node.js 后端开发指南:搭建、优化与部署

本文深入探讨了PyTorch是什麼,从其起源到核心特性,再到实际应用场景。通过详尽的解释和实际案例,涵盖了PyTorch的基础知识、动态计算图、GPU加速、神经网络构建、数据加载与处理、模型训练与测试,以及模型保存与加载。无论是初学者还是有经验的深度学习从业者,都能从中获益。
PyTorch 是由 Facebook 的人工智能研究团队(FAIR)开发的开源深度学习框架,于 2016 年正式发布。PyTorch 的前身是 Torch,一个基于 Lua 的科学计算框架。由于 Lua 的小众化,Torch 的流行度受到限制,这促使 PyTorch 采用了更广泛使用的 Python 作为语言基础。PyTorch 的设计哲学与 Python 非常相似,强调易用性和简洁性,使其成为科研人员和开发者的首选工具。

在设计上,PyTorch 引入了动态计算图(Dynamic Computation Graph),与 TensorFlow 的静态计算图形成鲜明对比。这一特性使得研究人员可以在运行时动态调整模型结构,从而更灵活地处理复杂任务。
PyTorch 提供了以下几个核心特性,使其在深度学习领域独树一帜:
PyTorch 被广泛应用于许多深度学习任务,包括但不限于:

Tensor 是 PyTorch 的核心数据结构,与 NumPy 的数组类似,但支持 GPU 加速。以下是一些常见的 Tensor 创建方法:
import torch
# 创建一个未初始化的 5x3 矩阵
x = torch.empty(5, 3)
print(x)
# 创建一个随机初始化的 5x3 矩阵
x = torch.rand(5, 3)
print(x)
# 创建一个 5x3 的零矩阵
x = torch.zeros(5, 3, dtype=torch.long)
print(x)Tensor 支持的操作包括索引、切片、矩阵运算等,用户可以方便地在 CPU 和 GPU 之间切换。
PyTorch 的自动求导机制通过 torch.autograd 模块实现。下面是一个简单的示例:
# 创建一个 Tensor 并启用梯度计算
x = torch.ones(2, 2, requires_grad=True)
y = x + 2
z = y * y * 3
out = z.mean()
# 反向传播
out.backward()
print(x.grad) # 输出梯度此机制使得用户无需手动计算复杂的梯度,极大地简化了深度学习的实现。
PyTorch 提供了丰富的 Tensor 运算,包括矩阵乘法、转置、求逆等。例如:
# 矩阵乘法
x = torch.randn(3, 3)
y = torch.randn(3, 3)
z = torch.mm(x, y)
print(z)这些操作对于构建复杂的神经网络模型至关重要。
在使用 GPU 加速时,首先需要检查系统是否支持 GPU:
import torch
if torch.cuda.is_available():
print("GPU 可用")
else:
print("GPU 不可用")将 Tensor 和模型移动到 GPU 上的操作非常简单:
# 将 Tensor 移动到 GPU
x = torch.randn(3, 3)
x = x.to('cuda')
# 将模型移动到 GPU
model = torch.nn.Linear(10, 1)
model = model.to('cuda')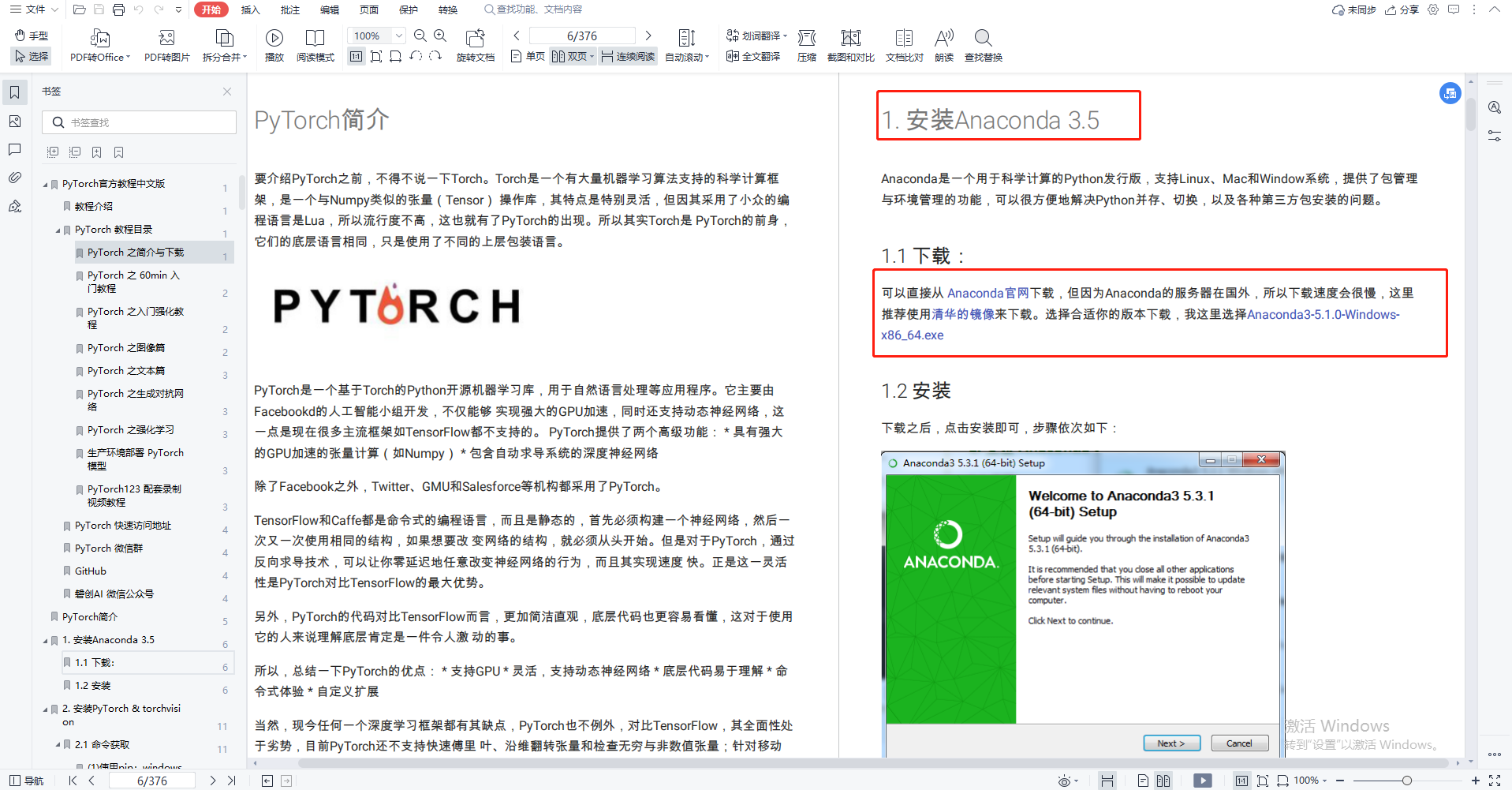
使用 GPU 进行深度学习训练可以显著缩短训练时间。例如,在 CIFAR10 数据集上训练 ResNet 模型时,GPU 的训练速度远远快于 CPU。以下是一个对比示例:
# 在 GPU 上训练模型
for epoch in range(10):
inputs, labels = inputs.to('cuda'), labels.to('cuda')
outputs = model(inputs)通过合理利用 GPU 资源,可以极大地提高模型训练的效率。
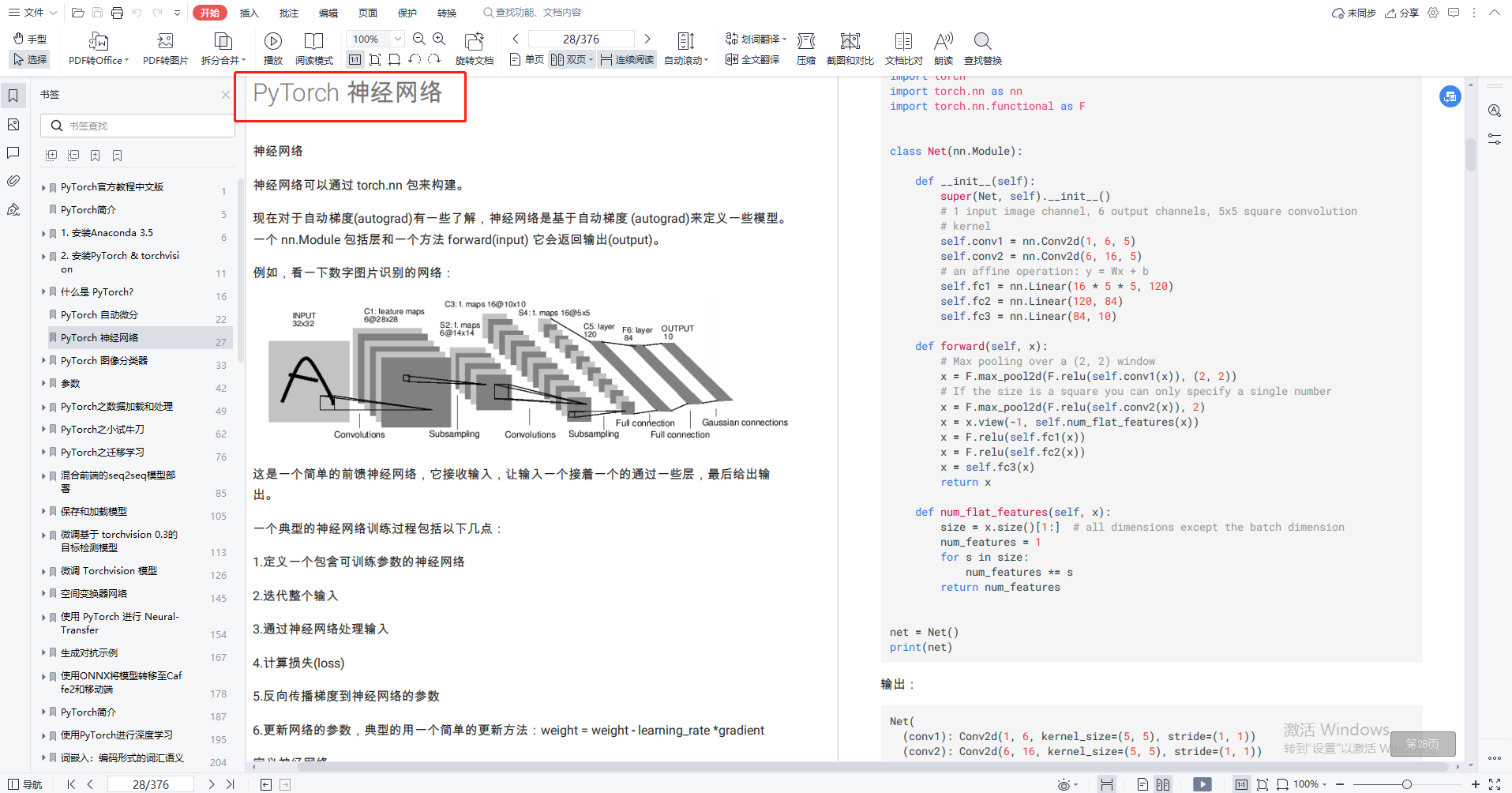
PyTorch 提供了 torch.nn 模块,用于构建神经网络。以下是一个简单的神经网络示例:
import torch.nn as nn
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(6 * 14 * 14, 120)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = x.view(-1, 6 * 14 * 14)
x = F.relu(self.fc1(x))
return x
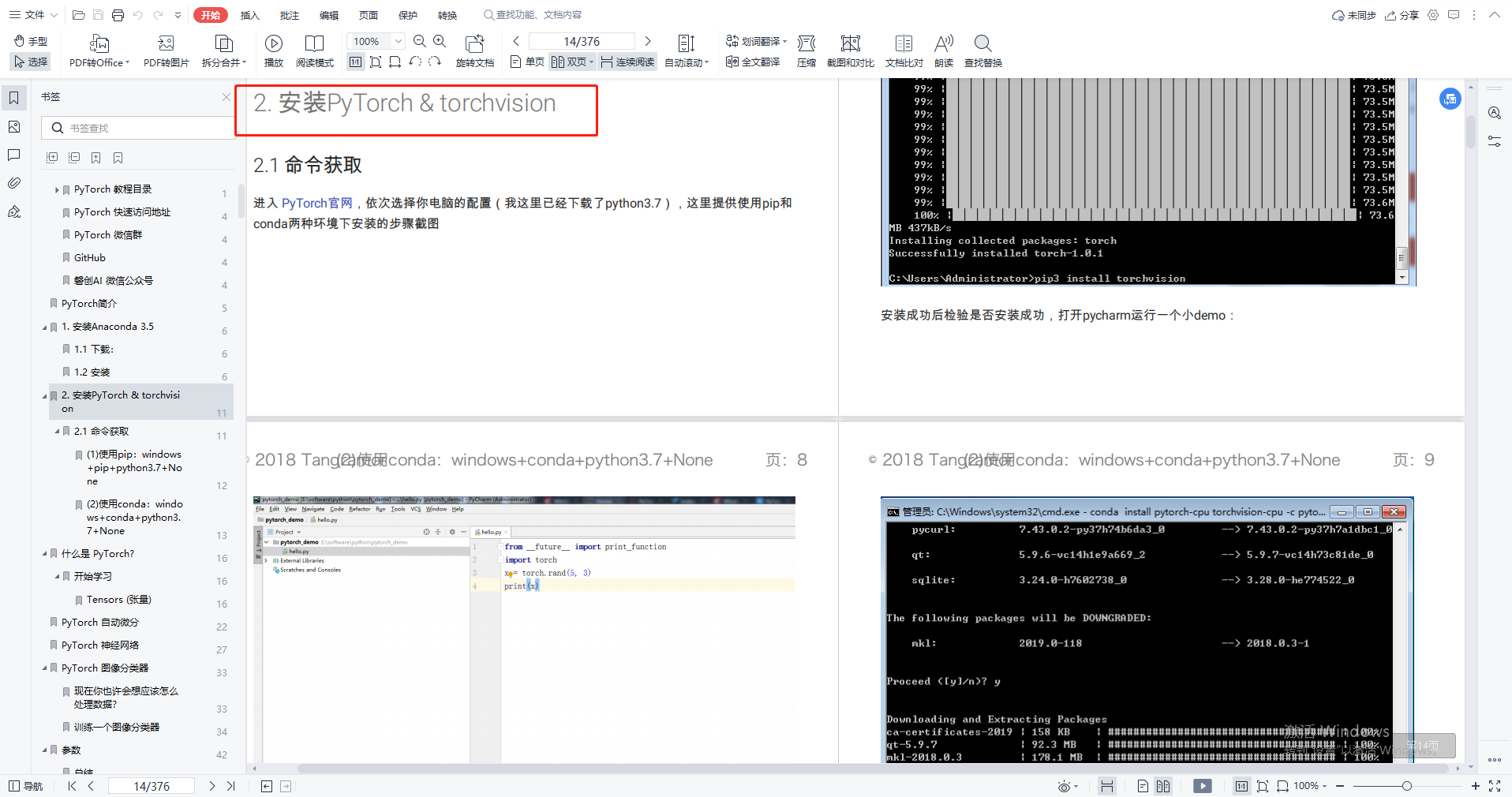
net = Net()PyTorch 提供了 torch.utils.data 模块,用于高效地加载和处理数据。例如:
from torchvision import datasets, transforms
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
data_loader = torch.utils.data.DataLoader(dataset, batch_size=64, shuffle=True)数据增强可以提高模型的泛化能力。常用的方法包括随机裁剪、翻转等:
transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor()
])
训练模型的过程包括前向传播、损失计算、反向传播和参数更新:
for epoch in range(2):
for data in data_loader:
inputs, labels = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()在测试集中评估模型性能:
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Accuracy: {100 * correct / total}%')
PyTorch 支持保存模型参数或整个模型结构:
# 保存模型参数
torch.save(model.state_dict(), 'model.pth')
# 保存整个模型
torch.save(model, 'entire_model.pth')加载模型时,需要使用与保存时一致的模型结构:
# 加载模型参数
model.load_state_dict(torch.load('model.pth'))
# 加载整个模型
model = torch.load('entire_model.pth')加载模型后,切换到评估模式:
model.eval()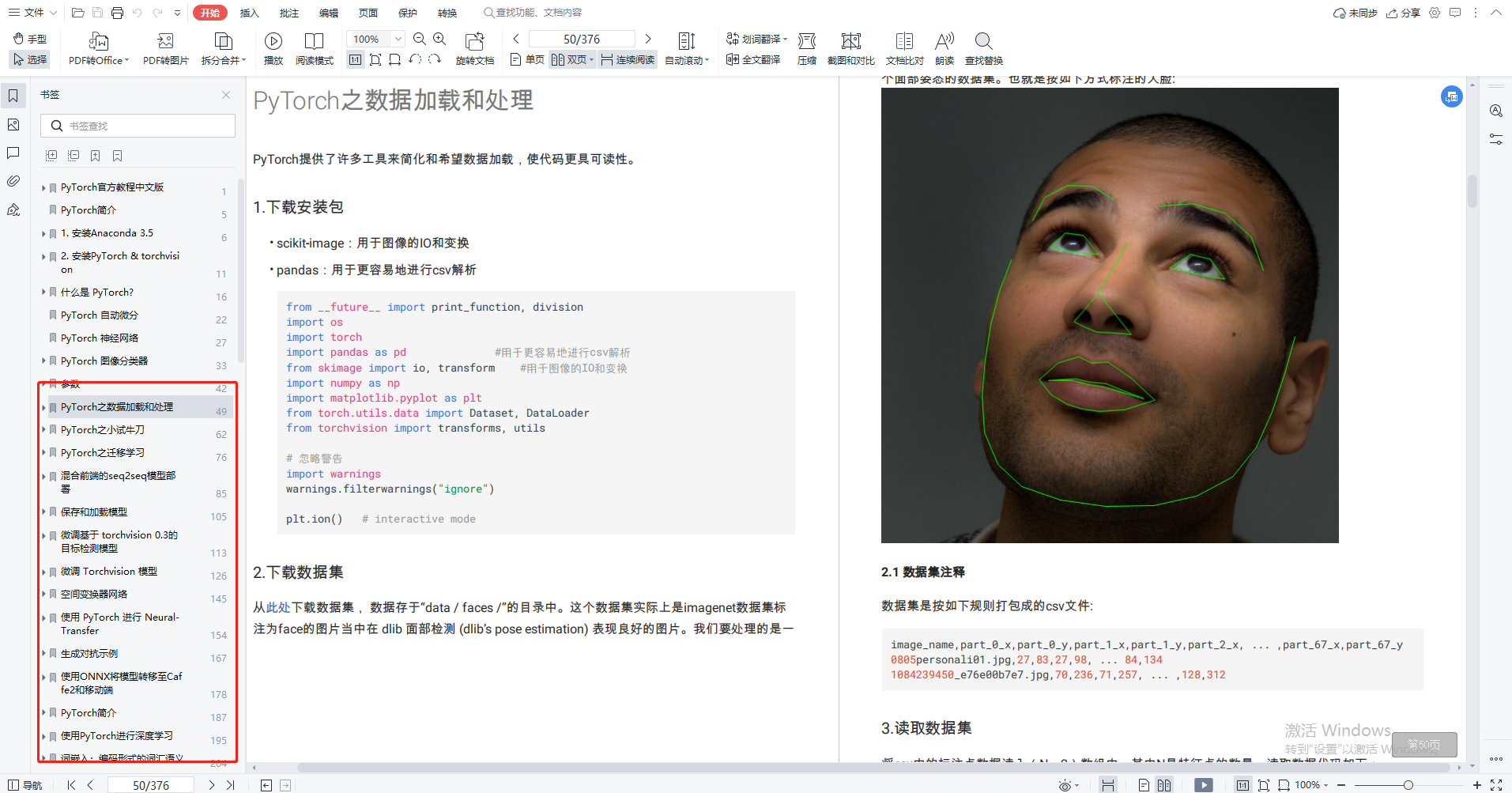
from torchvision import datasets, transforms
transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
train_set = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=64, shuffle=True)class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.fc1 = nn.Linear(64 * 8 * 8, 512)
self.fc2 = nn.Linear(512, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2)
x = x.view(-1, 64 * 8 * 8)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
model = SimpleCNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
for epoch in range(10):
for inputs, labels in train_loader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()torch.cuda.is_available() 来检测 GPU 的可用性,并使用 to('cuda') 方法将 Tensor 和模型移动到 GPU。






