原理:理解RAG(检索增强生成)的核心机制
原理:理解RAG(检索增强生成)的核心机制
RAG(Retrieval Augmented Generation)是一种结合了信息检索和大型语言模型(LLM)提示的技术。通过从特定数据源获取信息,RAG为LLM提供上下文,以生成更准确的答案。它的工作流程涉及将信息检索到的上下文注入到LLM的提示中,帮助模型更好地理解和回答用户的查询。

工作流程
RAG的核心流程包括文本分割、向量化、索引创建及上下文提示生成。首先,将文本分割成块,然后使用基于Transformer的Decoder模型将这些块嵌入为向量,并存入索引。随后,LLM使用这些索引中的上下文来回答查询。
文本切分与向量化
文本切分是RAG的基础步骤之一。由于Transformer模型有固定的输入序列长度,文本切分可以确保每个块能够被模型有效处理。选择合适的模型进行向量化,如bge-large或E5等搜索优化模型,是向量化过程的关键。
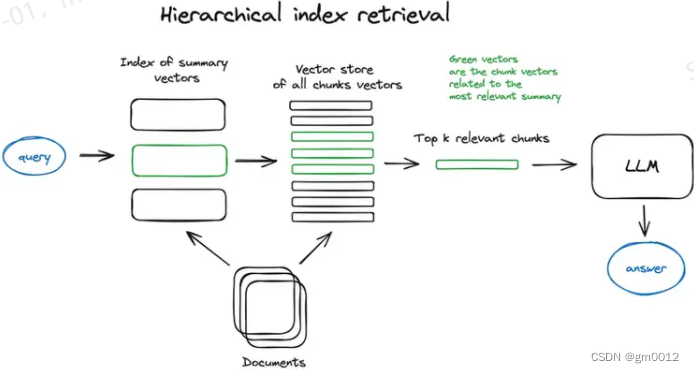
向量存储与索引
RAG中的索引存储来自向量化步骤的内容。最简单的方法是使用平面索引计算查询向量与所有块向量之间的距离。对于大型数据库,分层索引通过创建摘要和文档块两个索引,实现高效的信息检索。
上下文丰富化
为了提升搜索质量,RAG使用上下文丰富化技术。通过扩展检索到的句子前后的上下文窗口,或将文档递归地分割为多个子块,LLM能够进行更深入的推理。
句子窗口检索与自动合并检索器
句子窗口检索通过分别嵌入每个句子,实现了高精度的查询与上下文余弦距离搜索。自动合并检索器(父文档检索器)在找到与查询最相关的块后,会自动将这些子块与更大的父块结合,为LLM提供更丰富的上下文。

代码块描述与实现
RAG的实现通常涉及复杂的代码逻辑。以下是一个简单的Python代码示例,用于展示如何使用Transformer模型进行文本块的嵌入:
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("model_name")
model = AutoModel.from_pretrained("model_name")
text = "这是一个示例文本块。"
inputs = tokenizer(text, return_tensors="pt")
outputs = model(**inputs)
vector = outputs.last_hidden_state.mean(dim=1)结论
RAG技术通过结合检索和生成,极大地提升了模型在复杂查询下的应答能力。其核心在于如何高效地管理和利用上下文信息,以提供更精准的答案。
FAQ
-
问:RAG能处理多模态数据吗?
- 答:目前,RAG主要处理文本数据,但可以通过扩展和结合其他技术处理多模态数据。
-
问:RAG的优势是什么?
- 答:RAG的优势在于其结合检索和生成,使得模型能够在上下文丰富的环境中提供更准确的答案。
-
问:如何选择合适的嵌入模型进行向量化?
- 答:选择嵌入模型时应考虑模型的搜索优化能力、处理文本长度的能力,以及与具体应用场景的适配性。
通过对RAG技术的深入理解,可以帮助我们更好地应用这一技术,并为复杂的查询提供有效的解决方案。