

Phenaki API 价格:探索最新技术与市场趋势

Phenaki 是一款能够从开放域文本描述生成可变长度视频的创新模型。在这篇文章中,我们将深入探讨Phenaki的架构与实现,分析其源码,并提供相关的图片链接以便更好地理解其工作原理。本文将通过多个详细的标题进行展开,并提供常见问题解答(FAQ),以帮助读者更好地理解该模型的核心思想和技术细节。
Phenaki 作为一种新型的视频生成模型,利用了一种创新的编码器-解码器架构,称为C-ViViT。C-ViViT通过时间和空间上的压缩,将视频表示为离散的标记,使得模型能够生成任意长度的视频。这种设计不仅提高了视频生成的效率,还保证了视频的时空一致性。Phenaki的模型架构如图 1 所示,展示了其从文本到视频的生成过程。
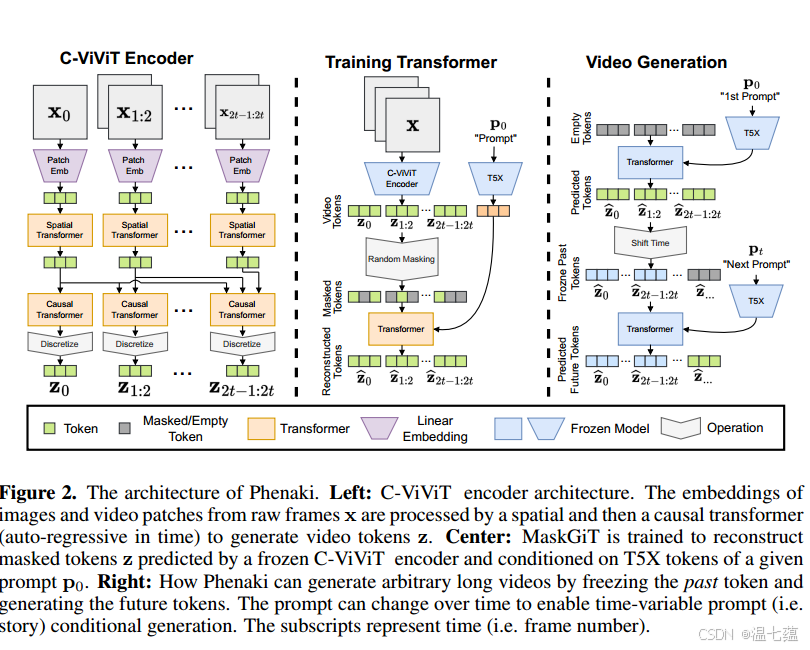
Phenaki 的核心是C-ViViT编码器-解码器,它通过因果变换器处理视频帧,生成视频标记。这种方法大大减少了每个视频所需的标记数量,从而降低了计算成本。编码器通过提取视频帧的特征,将其压缩为离散的标记,以便解码器能够重建视频。
C-ViViT架构充分利用了视频中的时间冗余,提升了每帧的重建质量。这种方法使得模型能够在不增加计算负担的情况下,生成更长的视频。通过因果结构,C-ViViT可以对可变长度的视频进行编码和解码。
Phenaki 使用了一种掩蔽双向变压器(Bidirectional Transformer)来处理文本到视频的生成任务。与传统的自回归变换器不同,双向变换器能够同时预测多个视频标记,从而减少采样时间,提高生成效率。为了优化生成质量,模型在训练中使用了掩蔽视觉标记建模(MVTM)策略,并结合了无分类器的指导进行训练。
双向变压器的主要优势在于其能够并行预测多个视频标记,这大大缩短了采样时间。通过调整掩蔽和采样策略,Phenaki 在长视频生成任务中表现出了优异的性能。
Phenaki 的训练结合了L2损失、图像感知损失和视频感知损失,以及对抗损失。通过这些损失函数,模型能够学习到更为丰富的视觉特征,从而提升视频生成的质量和多样性。
为了验证Phenaki的有效性,研究人员在多个任务上进行了实验,包括文本条件视频生成、图像条件视频生成和视频预测。实验结果显示,Phenaki在生成质量和时空一致性方面均表现出了优异的性能。
在文本条件视频生成任务中,Phenaki能够根据一系列文本提示生成动态变化的视频。实验结果表明,Phenaki在控制视频中演员和背景的动态变化方面具有高度的灵活性。

在图像条件视频生成任务中,Phenaki能够根据给定的图像和文本提示生成连贯的视频。模型通过结合图像和文本提示,生成了具有高度一致性的视频内容。
在视频编码和重建任务中,Phenaki通过C-ViViT编码器实现了高效的视频压缩和重建。实验表明,C-ViViT在视频重建质量和计算效率上均优于传统的逐帧编码器。
Phenaki 模型展示了在开放域文本提示下生成可变长度视频的强大能力。通过创新的C-ViViT架构和双向掩蔽变压器,Phenaki在视频生成的质量、多样性和效率上都取得了显著的进展。未来,随着更多高质量文本视频数据集的出现,Phenaki的性能和应用潜力将进一步提升。
问:Phenaki 如何处理不同长度的视频生成?
问:双向掩蔽变压器的优势是什么?
问:Phenaki 如何在图像和视频任务中进行联合训练?
通过以上的分析和讨论,我们对Phenaki模型的核心技术和实现有了更深入的理解。随着技术的不断发展,Phenaki在视频生成领域的影响力将进一步扩大。






