

如何调用 Minimax 的 API
谷歌和Meta等科技巨头正在探索文本转视频的前沿技术,其最新进展之一是Phenaki视频压缩模型。通过将文本转视频和文本转图像数据联合训练,Phenaki在开放域条件下生成时间上连贯的多样化视频,展示了强大的生成能力。该模型不仅能生成长达几分钟的视频,还能根据一系列prompt生成连贯的故事情节,推动了视频生成领域的创新应用。
Meta最近推出了一个名为Make-A-Video的工具,可以生成高质量的短视频。这款工具的亮点在于其生成的视频非常具有想象力和创造性,能够从文本生成具有视觉吸引力的内容。
该工具利用先进的生成式建模技术,将文本描述转化为动态视频。这种技术的核心在于扩散模型的应用,能够在视频生成中实现高分辨率和连贯性的结合。
随着科技的进步,文本转视频的应用将更为广泛。Make-A-Video作为Meta的创新工具,将在广告、教育、娱乐等领域发掘更多的可能性。
谷歌推出的Imagen Video是一种基于级联视频扩散模型的系统,能够从文本提示生成高清视频。它的系统架构由frozen T5文本编码器和基础视频生成模型组成。
Phenaki则关注于长视频的生成,特别是从复杂的文本提示转化为连贯的视频序列。Phenaki通过其独特的架构实现了对长prompt的出色解析能力。
谷歌通过推出这两款工具,分别在视频品质和长度方面展开竞争,意图在这两方面同时取得优势。
Imagen Video利用级联视频扩散模型,通过逐步提高视频的时空分辨率,实现了从文本到高清视频的转换。这种方法借鉴了图像生成领域的成功经验。
Imagen Video的架构由多个子模型组成,包括空间超分辨率和时间超分辨率模型,这些模型通过级联操作共同生成高清晰度的视频。
在实验中,Imagen Video展示了其生成高清视频的能力,能够生成具有艺术风格和3D对象理解的视频。
在视频生成中,生成长视频的挑战在于数据的稀缺性和计算的复杂性。Phenaki通过引入故事驱动的生成方式,克服了这些障碍。
Phenaki通过一系列文本prompt生成视频,能够根据时间点的变化调整视频帧。这使得生成的视频更加连贯和有意义。
这种基于故事的生成方法为艺术和设计领域的创作提供了无限可能,开启了新的创意应用之路。
C-ViViT是一种新型的编码器-解码器架构,专为视频生成设计。它在时间和空间维度上压缩视频,优化了视频的重构质量。
C-ViViT通过利用视频中的时间冗余,压缩了视频token的数量,提高了生成效率。这一改进使得长视频生成成为可能。
得益于其因果结构,C-ViViT能够处理可变长度的视频生成,这在现有的编码器中是难以实现的。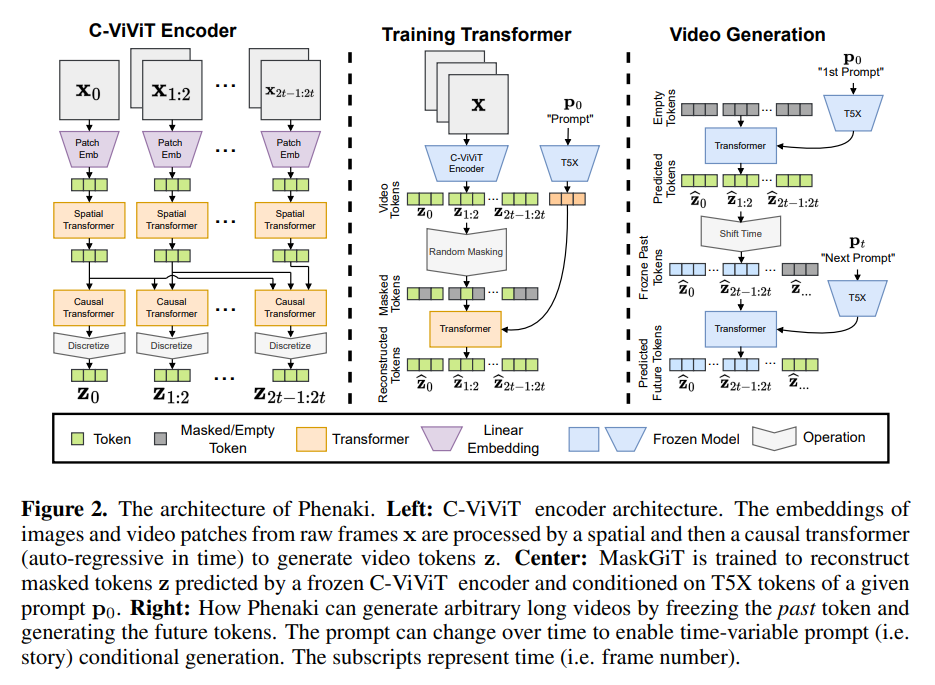
Phenaki采用了文本转视频和文本转图像数据的联合训练方法,这使得其在多样化视频生成上具备了独特的能力。即使训练视频很短,它也能生成长达几分钟的视频。
Phenaki能够根据一系列文本prompt生成完整的视频故事,展示了其在连贯性和多样性上的出色表现。
在实验中,Phenaki展示了其生成长视频的能力,即便在有限的数据集上进行了训练。
Phenaki的出现为创意产业带来了新的契机,特别是在艺术和设计领域,它提供了一种新的内容生成方式。
随着技术的进步,Phenaki有望在视频生成的多个领域发挥更大的作用,尤其是在需要高质量长视频的场合。
Phenaki的创新性为谷歌在视频生成市场中占据一席之地提供了支持,未来或将引领这一领域的技术潮流。





