大模型综述:探索大型语言模型的关键技术与应用
语言理解和生成能力,成为自然语言处理领域的热点话题。本文将对大模型进行全面综述,探讨其关键技术、应用领域以及未来发展方向。
LLMs 的基本概念与技术
大型Transformer架构的神经网络模型,其参数规模通常达到数百亿到数千亿。通过在大规模无标注语料库上进行预训练,LLMs能够捕捉语言结构和规律。
预训练技术
LLMs的预训练通常涉及自回归或双向预测的语言建模任务。这些任务帮助模型学习语言的内在结构和语境关系。例如,GPT-3通过自回归方式进行预训练,从而在生成任务中表现优异。
分布式训练算法
由于LLMs的参数规模巨大,分布式训练成为必要。工具如DeepSpeed和Megatron-LM能够有效分配计算资源,确保训练的快速和稳定性。这些工具通过优化并行计算和内存使用,大幅提升了训练效率。
一致性和控制
确保LLMs的输出符合人类价值观和伦理规范至关重要。为此,研究人员通过一致性微调、强化学习以及人工反馈等方式,来提高模型输出质量,降低生成有害内容的风险。
缩放定律与涌现能力
LLMs的性能与模型大小、数据量及计算资源之间存在密切关系,这种关系被称为缩放定律。研究发现,随着参数规模的增加,模型性能显著提升,这一现象被称为规模效应。
缩放定律(Scaling Laws)
缩放定律说明LLMs的性能提升与模型参数数量成幂律关系。例如,GPT-3和PaLM通过大幅增加参数量(分别达到1750亿和5400亿),其在多项任务中的表现显著优于前代模型。研究者还探讨在有限预算下的资源分配策略,如Chinchilla模型通过增加训练数据量来优化性能。
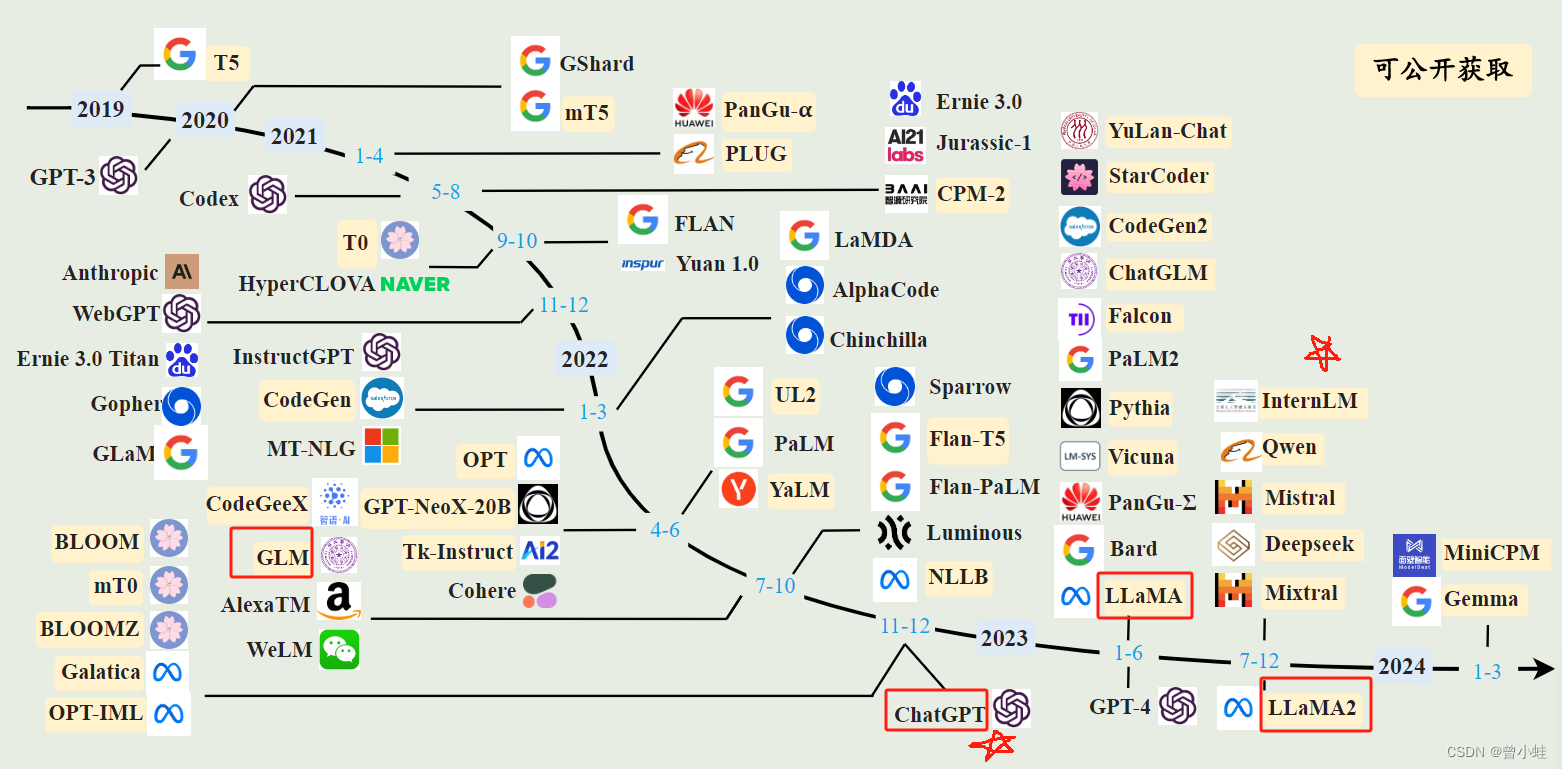
涌现能力(Emergent Abilities)
当LLMs达到一定规模后,展示出小型模型不具备的能力。这些涌现能力包括上下文学习、指令跟随和多步推理。
上下文学习
上下文学习指的是模型在未经过特定任务微调的情况下能够理解并响应复杂指令。例如,GPT-3在提供自然语言指令和多个任务示例后,能够生成预期的输出。
指令跟随
通过多任务数据集和自然语言描述进行微调,LLMs能够在新任务中遵循给出的指令执行任务。LaMDA-PT经过指令调优后,其在未见过的任务上的性能显著优于未经调优的版本。
分步推理
小型语言模型通常难以处理复杂任务,而LLMs通过链式思维提示策略,利用中间推理步骤有效解决此类任务。这一策略在超过60B参数的大模型中尤其有效。
语言模型的发展历程
语言模型的发展经历了从统计模型到神经网络模型的演进,特别是Transformer架构的引入,使得大规模模型的预训练成为可能。
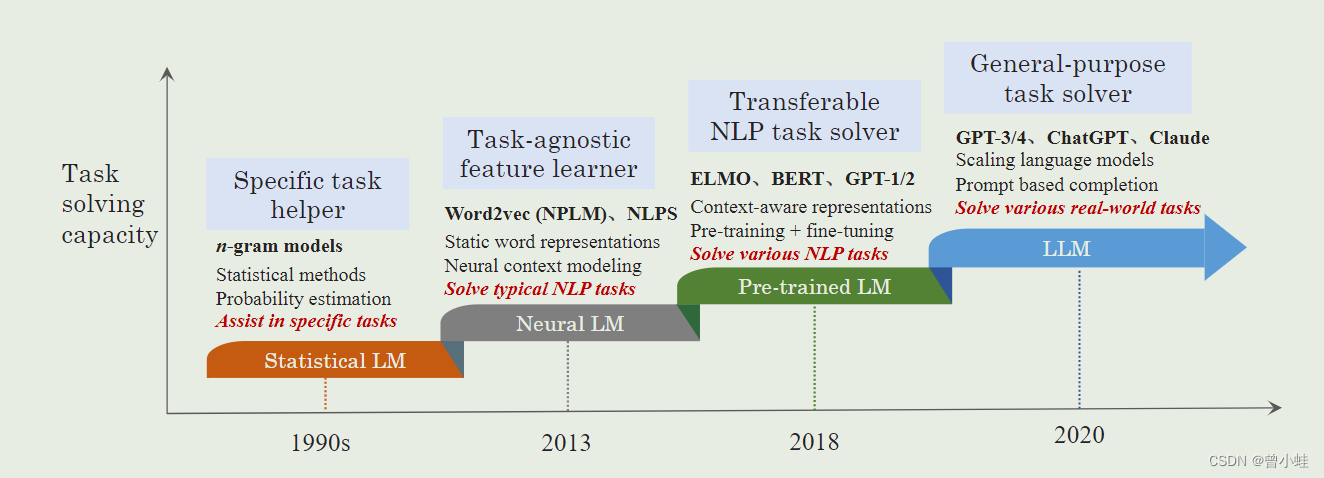
早期预训练神经网络
1999年,Bengio等人开发了早期的神经语言模型。随后,循环神经网络(RNNs)及其变种,如长短期记忆(LSTM)和门控循环单元(GRU)被广泛应用于自然语言处理。
Transformer 的出现
Transformer架构的发明标志着自然语言模型发展中的重要里程碑。与RNNs相比,Transformers具备更好的并行能力,使得在GPU上高效预训练超大规模语言模型成为可能。
大模型家族
LLMs包括多个知名的模型系列,如GPT、LLaMA和PaLM。每个系列在架构和应用上都有独特的特点和优势。
如何构建一个大模型
构建LLMs涉及多个步骤,包括架构选择、数据清洗、模型预训练、微调和解码策略。
架构选择
目前最广泛使用的LLM架构包括encoder-only、decoder-only和encoder-decoder架构。选择合适的架构是构建LLMs的首要步骤。
数据清洗
数据质量对模型性能至关重要。数据清洗技术如过滤、去重和预处理等,对模型的训练效果有显著影响。
数据过滤
数据过滤旨在提高训练数据质量。常用方法包括数据去噪、处理异常值、平衡类别以及文本预处理等。
数据去重
去重是指删除重复的数据实例,这有助于提高模型的泛化能力。
模型预训练
预训练是LLM训练流程的第一步。通常采用自监督的方式在大规模未标记文本上进行训练。常见的预训练任务包括next token prediction和masked language modeling。
LLMs 的应用与挑战
LLMs在多个领域展现出强大能力,但同时也面临诸多挑战。
应用领域
LLMs广泛应用于自然语言处理、信息检索、推荐系统和多模态处理等领域。
自然语言处理
在自然语言处理任务中,LLMs能够处理复杂的文本生成、理解和推理任务,甚至超越传统的小模型。
信息检索
LLMs可以作为信息检索模型,通过重新排序候选文档提高检索质量。
推荐系统
LLMs能够通过指令微调实现个性化推荐,提升用户体验。
挑战与未来发展
尽管LLMs在许多方面取得了进展,但仍面临准确性、偏见、安全性和隐私等挑战。未来需要开发更有效的技术,以提高LLMs的能力并确保其安全可靠地应用于现实世界。
更小更高效的模型
研究趋势是提出小型语言模型(SLMs)作为对LLMs的经济替代,尤其在不需要如此大模型的任务中。
注意力机制后的新架构范式
状态空间模型(SSMs)和专家混合(MoE)等新架构正在崭露头角,为LLMs的发展提供了新的方向。
多模态LLMs
多模态LLMs能够融合文本、图像等多种数据,拓展了模型的应用范围。
结论
大型语言模型在自然语言处理领域的应用前景广阔,但也面临诸多技术和伦理挑战。未来的发展需要在模型架构、训练方法、应用安全性等方面持续探索与改进。
FAQ
-
问:LLMs的涌现能力是什么?
- 答:LLMs的涌现能力指的是在参数规模达到某一阈值时,模型展现出的新能力,如上下文学习、指令跟随和分步推理。
-
问:如何提高LLMs的训练效率?
- 答:可以通过使用分布式训练工具如DeepSpeed和Megatron-LM,以及优化数据清洗和预处理流程来提高训练效率。
-
问:LLMs存在哪些安全性问题?
- 答:LLMs可能生成有害或偏见内容,需通过一致性微调、RLHF等方法来改进模型输出质量。