

ChatGPT API 申请与使用全攻略

在现代生成模型的研究中,了解模型的参数设置及其影响是至关重要的。本文将重点讨论LLAMA模型中的 model.generate 参数,阐述其在实际应用中的重要性和具体实现方式。
Temperature 是生成模型中的一个重要超参数,用于控制生成文本的随机性和创造性。通过调整 softmax 函数的输出概率,Temperature 会影响文本生成的多样性。其公式为:
p ( x_i ) = frac{e^{x_i/T}}{sum_{j=1}^V e^{x_j/T}}当 Temperature 值增大时,生成文本的随机性增加,可能产生更多样的文本。当值减小时,生成结果更为保守。
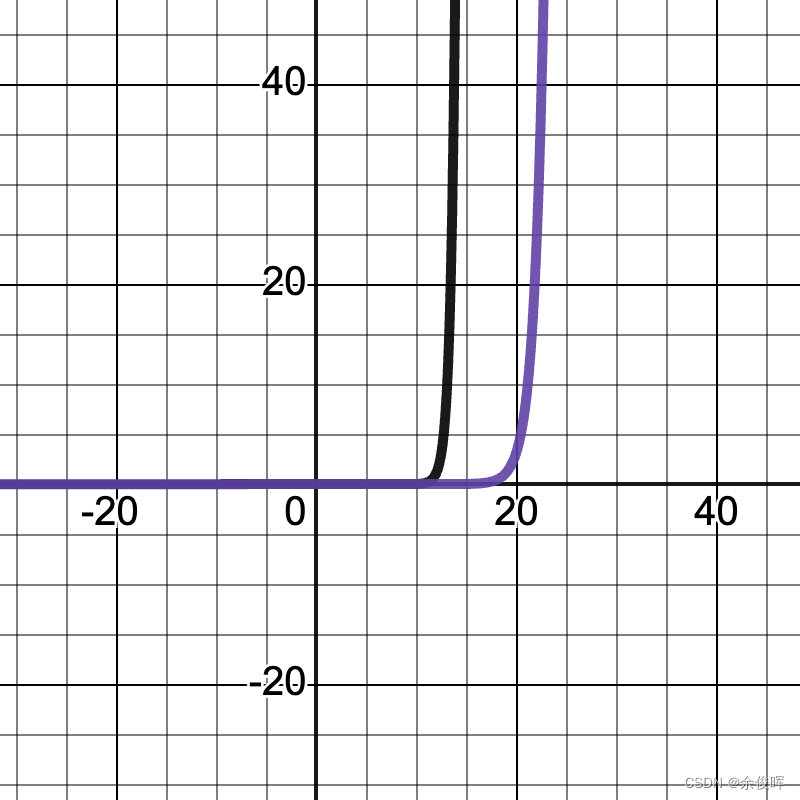
在文本生成任务中,选择合适的 Temperature 值尤为重要。例如,在自动诗歌生成时,可以选择较高的 Temperature 来增加创意,而在法律文档生成时,则需要较低的 Temperature 保持严谨性。
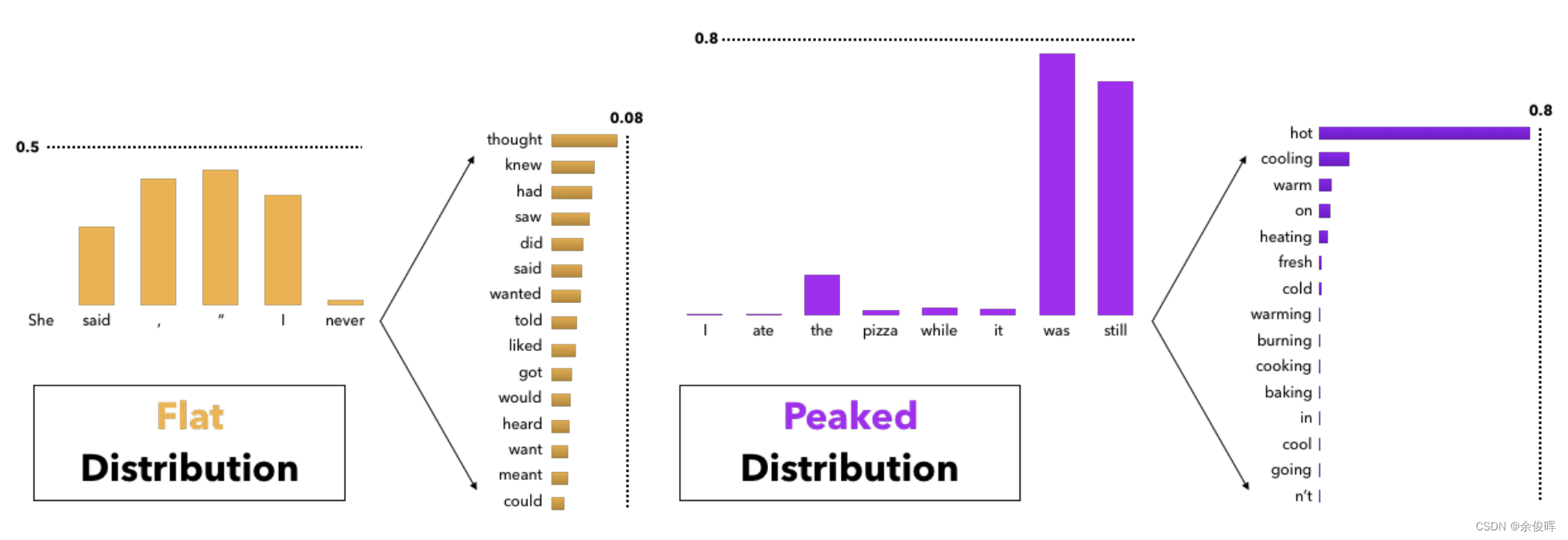
sample_top_p 是另一种控制生成随机性的算法,又称为核采样。它通过选取概率和超过某一阈值的词来生成文本。
def sample_top_p(probs, p):
probs_sort, probs_idx = torch.sort(probs, dim=-1, descending=True)
probs_sum = torch.cumsum(probs_sort, dim=-1)
mask = probs_sum - probs_sort > p
probs_sort[mask] = 0.0
probs_sort.div_(probs_sort.sum(dim=-1, keepdim=True))
next_token = torch.multinomial(probs_sort, num_samples=1)
next_token = torch.gather(probs_idx, -1, next_token)
return next_token在实际应用中,sample_top_p 可以有效减少生成结果的重复性,增加文本的多样性。例如,在对话生成中,可以通过设置合适的 top_p 值来确保对话的自然流畅。
LLAMA 模型的核心生成函数 generate() 结合了多种参数调控机制,为文本生成提供了强大的灵活性。
def generate(
self,
prompt_tokens: List[List[int]],
max_gen_len: int,
temperature: float = 0.6,
top_p: float = 0.9,
logprobs: bool = False,
echo: bool = False,
) -> Tuple[List[List[int]], Optional[List[List[float]]]]:
params = self.model.params
bsz = len(prompt_tokens)
assert bsz <= params.max_batch_size, (bsz, params.max_batch_size)
min_prompt_len = min(len(t) for t in prompt_tokens)
max_prompt_len = max(len(t) for t in prompt_tokens)
assert max_prompt_len 0:
probs = torch.softmax(logits[:, -1] / temperature, dim=-1)
next_token = sample_top_p(probs, top_p)
else:
next_token = torch.argmax(logits[:, -1], dim=-1)
next_token = next_token.reshape(-1)
next_token = torch.where(
input_text_mask[:, cur_pos], tokens[:, cur_pos], next_token
)
tokens[:, cur_pos] = next_token
eos_reached |= (~input_text_mask[:, cur_pos]) & (
next_token == self.tokenizer.eos_id
)
prev_pos = cur_pos
if all(eos_reached):
break
if logprobs:
token_logprobs = token_logprobs.tolist()
out_tokens, out_logprobs = [], []
for i, toks in enumerate(tokens.tolist()):
start = 0 if echo else len(prompt_tokens[i])
toks = toks[start: len(prompt_tokens[i]) + max_gen_len]
probs = None
if logprobs:
probs = token_logprobs[i][start: len(prompt_tokens[i]) + max_gen_len]
if self.tokenizer.eos_id in toks:
eos_idx = toks.index(self.tokenizer.eos_id)
toks = toks[:eos_idx]
probs = probs[:eos_idx] if logprobs else None
out_tokens.append(toks)
out_logprobs.append(probs)
return (out_tokens, out_logprobs if logprobs else None)这一函数不仅支持多样的参数调整,还能通过不同的策略组合实现最优的文本生成效果。无论是在创意文本还是结构化文档生成中,都能提供强有力的支持。
LLAMA 模型在多个领域展现了其强大的生成能力。以下是一些具体的应用案例:
以下是一个简单的代码补全示例,展示了如何利用LLAMA模型进行代码生成:
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
import torch
model_id = "codellama/CodeLlama-34b-hf"
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=quantization_config,
device_map="auto",
)
prompt = 'def remove_non_ascii(s: str) -> str:n """ '
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
output = model.generate(
inputs["input_ids"],
max_new_tokens=200,
do_sample=True,
top_p=0.9,
temperature=0.1,
)
output = output[0].to("cpu")
print(tokenizer.decode(output))通过对 model.generate 参数的深入探讨,我们可以更好地理解和应用 LLAMA 模型的强大功能。在未来,随着模型能力的提升和应用领域的扩展,这些参数设置将起到更加关键的作用。
问:什么是 Temperature 超参数?
问:如何应用 sample_top_p 采样?
问:LLAMA 模型可以应用于哪些领域?
问:如何选择合适的 generate 参数设置?
问:generate 函数支持哪些设备?




