

大模型RAG技术:从入门到实践

模型蒸馏(Model Distillation)在深度学习领域中是一种重要的模型压缩技术。通过将复杂且庞大的教师模型中的知识提炼并传递给更小的学生模型,模型蒸馏实现了模型的轻量化和高效化。本文将详细探讨模型蒸馏的流程、作用、实现过程及其在实际应用中的表现。
模型蒸馏技术的实现通常包括以下几个步骤:
在模型蒸馏过程中,首先需要一个已经训练好的教师模型和一个待训练的学生模型。教师模型通常具有高性能但复杂度较高,而学生模型则是一个较为简单的模型,用于学习教师模型的知识。
接下来,使用教师模型对数据集进行预测,得到每个样本的预测概率分布,即软目标。这些概率分布不仅包含了模型对每个类别的置信度,还提供了更多的细节信息。
损失函数是模型蒸馏的关键步骤之一。常用的损失函数是结合软标签损失和硬标签损失的混合损失函数。软标签损失通常使用KL散度来度量,鼓励学生模型模仿教师模型的输出概率分布,而硬标签损失则用于确保学生模型能够正确预测真实标签。
在训练过程中,将教师模型的输出作为监督信号,通过优化损失函数来更新学生模型的参数。温度参数在此过程中起到了关键作用,通过调整软目标的分布,温度较高时分布更平滑,而逐渐降低温度可以提高蒸馏效果。
最后,在蒸馏过程完成后,可以对学生模型进行进一步的微调,以提高其性能表现。
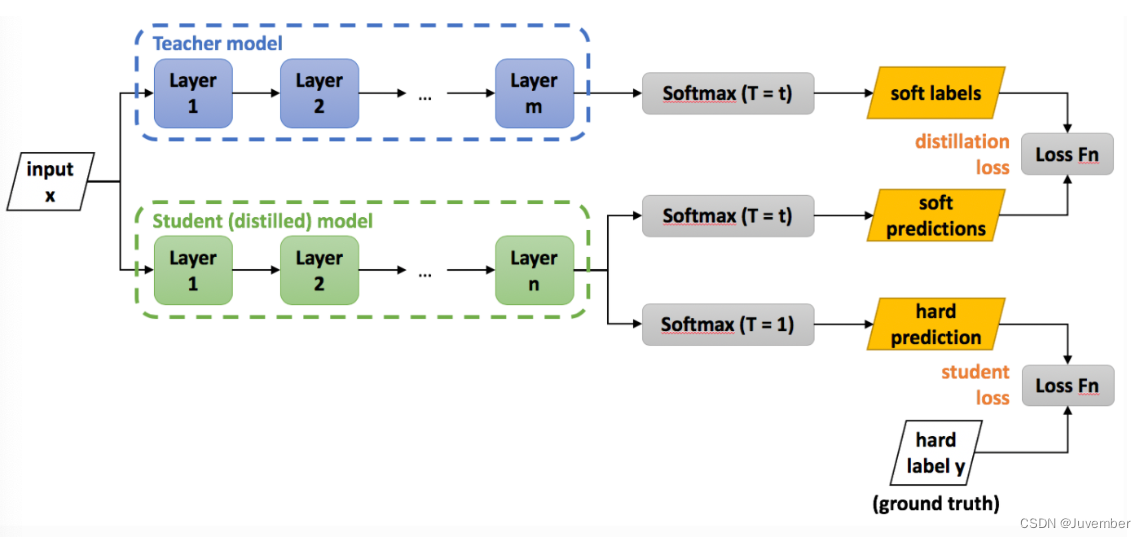
通过将大型模型的知识传递到小型模型中,模型蒸馏可以显著降低模型的复杂度和计算量,从而提高模型的运行效率。
蒸馏后的模型因其简化的结构,在推理时速度更快,从而显著降低计算成本和能耗,并减少对硬件资源的需求。
研究表明,模型蒸馏能帮助学生模型学习到教师模型中蕴含的泛化模式,从而提高其在未见过的数据上的表现。
模型蒸馏技术可以作为一种迁移学习的方法,将在一个任务上训练好的模型知识迁移到另一个任务上。
轻量化的模型通常更加简洁明了,有助于理解和分析模型的决策过程,同时也更容易进行部署和应用。
以下是一个使用PyTorch框架实现的简单模型蒸馏代码示例,其中使用一个预训练的ResNet-18模型作为教师模型,并使用一个简单的CNN模型作为学生模型。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, models, transforms
teacher_model = models.resnet18(pretrained=True)
student_model = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(128 * 7 * 7, 10)
)
criterion = nn.CrossEntropyLoss()
optimizer_teacher = optim.SGD(teacher_model.parameters(), lr=0.01, momentum=0.9)
optimizer_student = optim.Adam(student_model.parameters(), lr=0.001)
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
trainset = datasets.MNIST('../data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
for epoch in range(10):
running_loss_teacher = 0.0
running_loss_student = 0.0
for inputs, labels in trainloader:
# 教师模型的前向传播
outputs_teacher = teacher_model(inputs)
loss_teacher = criterion(outputs_teacher, labels)
running_loss_teacher += loss_teacher.item()
# 学生模型的前向传播
outputs_student = student_model(inputs)
loss_student = criterion(outputs_student, labels) + 0.1 * torch.sum((outputs_teacher - outputs_student) ** 2)
running_loss_student += loss_student.item()
# 反向传播和参数更新
optimizer_teacher.zero_grad()
optimizer_student.zero_grad()
loss_teacher.backward()
optimizer_teacher.step()
loss_student.backward()
optimizer_student.step()
print(f'Epoch {epoch+1}/10 t Loss Teacher: {running_loss_teacher / len(trainloader)} t Loss Student: {running_loss_student / len(trainloader)}')除了模型蒸馏技术,还有一些其他的技术可以用于实现模型的压缩和加速,例如:
通过删除神经网络中冗余的权重,可以减少模型的复杂度和计算量。具体来说,可以通过设定一个阈值来判断权重的重要性,然后将不重要的权重设置为零或删除。
将神经网络中的权重和激活值从浮点数转换为低精度的整数表示,从而减少模型的存储空间和计算量。
选择性地从教师模型中抽取部分子结构用于构建学生模型。
通过删除神经网络中冗余的神经元或连接来减少模型的复杂度和计算量。可以通过设定一个阈值来判断神经元或连接的重要性,然后将不重要的神经元或连接删除。
将神经网络中的权重矩阵分解为两个低秩矩阵的乘积,从而减少模型的存储空间和计算量。这种方法可以应用于卷积层和全连接层等不同类型的神经网络层。
模型蒸馏技术在实际应用中表现出色,尤其是在计算机视觉、自然语言处理和语音识别等领域。通过使用模型蒸馏技术,企业可以在资源受限的环境下部署高效的深度学习模型,提升产品性能和用户体验。
在自然语言处理领域,模型蒸馏被广泛应用于情感分析、文本分类等任务。例如,通过将大型预训练语言模型(如BERT)的知识蒸馏到一个小型模型中,可以在不显著牺牲性能的情况下,显著提高模型推理的速度和部署的灵活性。
尽管模型蒸馏技术在许多领域取得了成功,但在某些情况下,如何选择合适的温度参数、如何设计合适的损失函数,仍然是技术难点。此外,未来的发展方向还包括探索新的知识迁移方式、提高模型蒸馏的自动化程度等。
问:模型蒸馏的核心思想是什么?
问:模型蒸馏有哪些优势?
问:模型蒸馏在NLP中的应用如何?
问:模型蒸馏面临哪些挑战?
问:模型蒸馏与其他模型压缩技术的区别是什么?
通过以上内容,我们对模型蒸馏的基本概念、实现流程、作用、代码实现及其在工业界的应用有了全面的了解。未来,随着技术的不断进步,模型蒸馏将在更多领域展现其潜力和优势。







