

文心一言写代码:代码生成力的探索

Mistral-Large-Instruct-2407 是一款由 Mistral AI 推出的新一代旗舰 AI 模型。它具有 123B 个参数,支持 128k 的上下文窗口,涵盖包括中文在内的数十种语言,以及 80 多种编程语言如 Python、Java、C、C++、JavaScript 和 Bash 等。与前代产品相比,该模型在多语言能力、数学、推理、代码编写等方面均有显著提升。在 MMLU 的评估中,其准确度达到了 84.0%。

为了有效利用 Mistral-Large-Instruct-2407 模型,用户需要配置几项关键参数。经过实测,使用四张 A800 GPU 可以成功运行该模型。以下是具体的配置方法:
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m vllm.entrypoints.openai.api_server
--model /data/models/Mistral-Large-Instruct-2407/
--served-model-name aaa
--trust-remote-code
--tensor-parallel-size 4
--port 8000部署后,可通过标准 OpenAI 接口访问该模型,实现便捷的调用与集成。
在 AI 任务测试中,Mistral-Large-Instruct-2407 展现了卓越的性能。以“9.11 和 9.9 哪个大”为例,该模型提供了正确的答案,并通过了多个数学基准测试,显示出其推理与解决问题的能力显著增强。
9.11 比 9.9 大。
原因如下:
1. 首先比较整数部分:9.11 和 9.9 的整数部分都是 9,所以它们相等。
2. 接下来比较小数部分:
- 9.11 的小数部分是 0.11。
- 9.9 的小数部分是 0.9。
显然,9.11(即 9 + 0.11)比 9.9(即 9 + 0.9)大,因为 9.11 比 9.9 多了 0.01。尽管结果正确,但推理过程中的某些细节可以进一步优化,以提高输出的严谨性。
Mistral-Large-Instruct-2407 在代码生成与推理领域表现出色。通过大量代码示例的训练,该模型能够生成准确且高效的代码段,并在多个基准测试中表现优异。
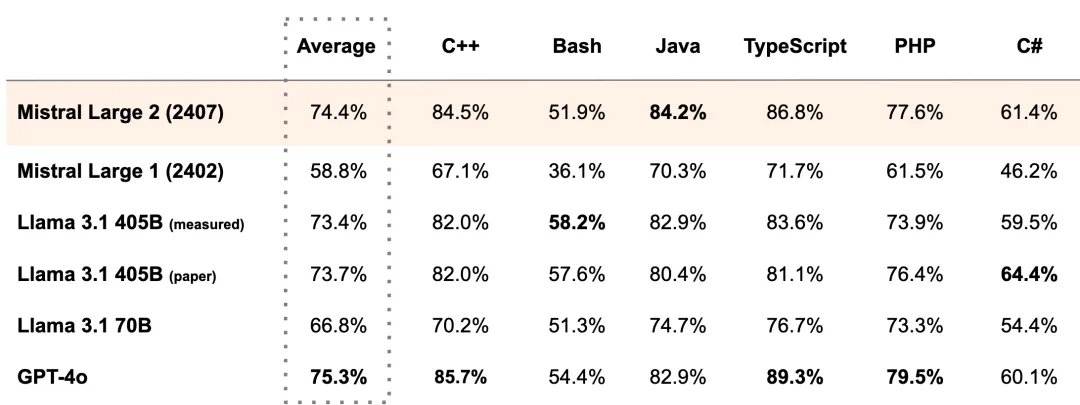
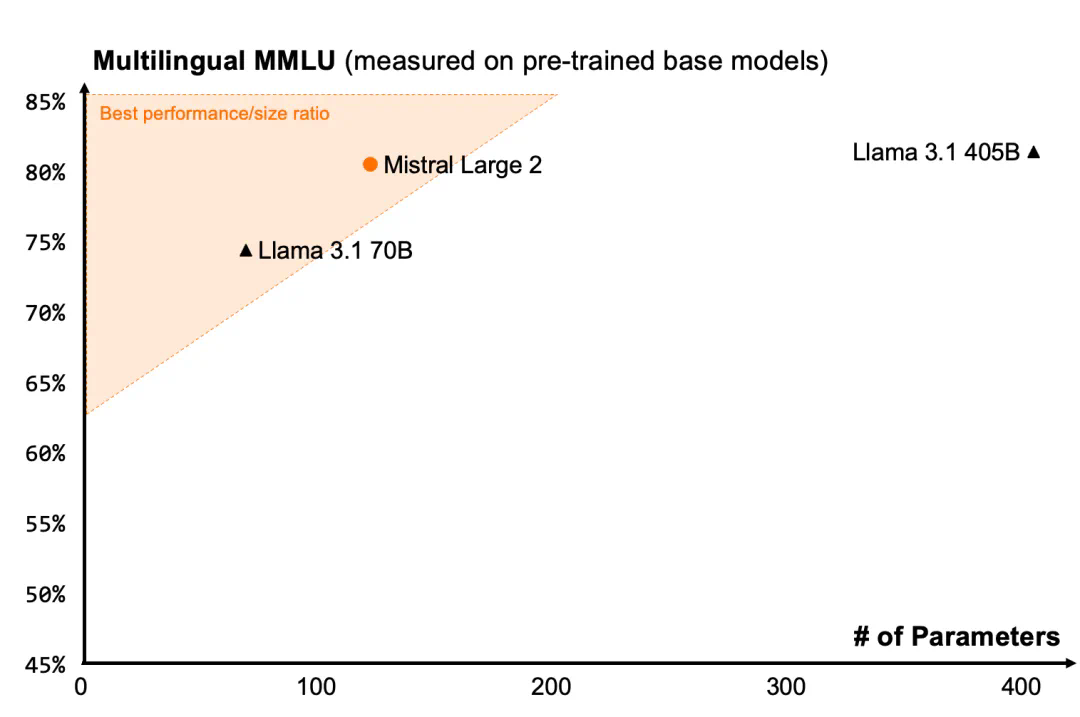
支持数十种语言的 Mistral-Large-Instruct-2407,尤其擅长处理多语言文档,适用于全球化业务场景。在多语言 MMLU 基准测试中,其表现优于先前的模型版本。
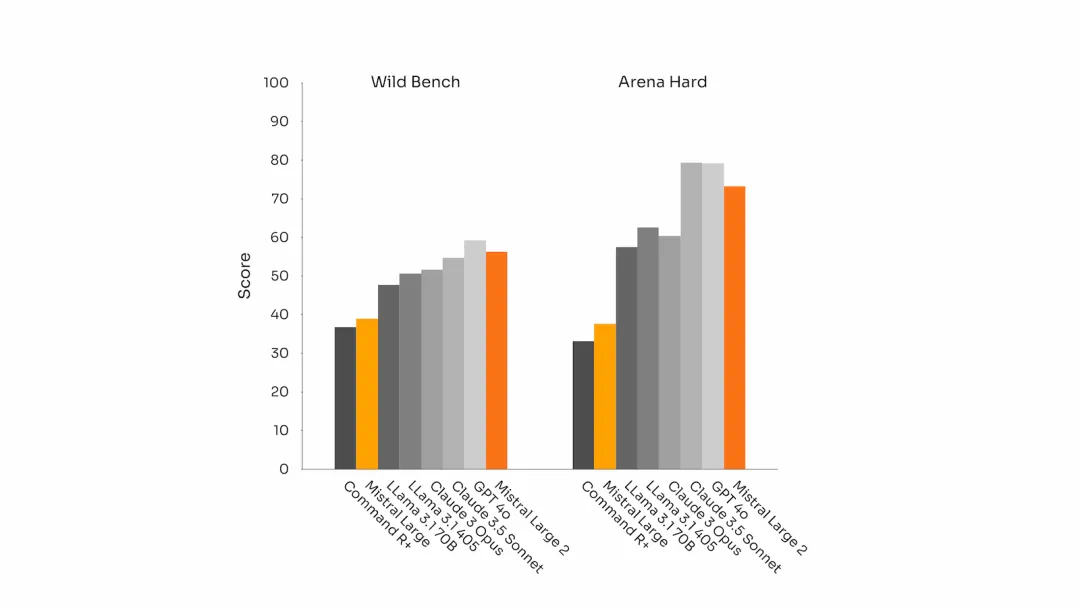
Mistral-Large-Instruct-2407 在指令遵循和对话能力上有了显著提升。尤其在长时间多轮对话中,能够保持上下文一致性和逻辑性。
尽管官方声称支持最大 128k 的 token,但实际测试中,模型仅支持 32k 的 token 上下文长度。用户在发送请求时,需注意消息长度,避免超出此限制。
目前,vllm 并不支持 Mistral-Large-Instruct-2407 的函数调用功能,但其潜在能力在官方测评中已被证明出色。
Mistral-Large-Instruct-2407 的开放使用仅限于研究和非商业用途。对于商业部署,用户需提前获得 Mistral AI 的商业许可证。同时,模型的开放权重允许第三方根据需求进行微调,进一步优化模型性能。
Mistral-Large-Instruct-2407 凭借其强大的通用能力、卓越的代码与推理能力,已成为接近 GPT4 的顶尖 AI 模型之一。尽管存在某些技术限制,该模型依旧是人工智能领域中一颗璀璨的明珠。
问:Mistral-Large-Instruct-2407 是否支持商业用途?
问:如何部署 Mistral-Large-Instruct-2407?
问:Mistral-Large-Instruct-2407 支持哪些语言?
问:最大 Token 限制对使用有什么影响?
问:Mistral-Large-Instruct-2407 的函数调用能力如何?






