

AI视频剪辑工具:解锁创作的无限可能

本文旨在为读者提供一个全面的Milvus开发文档详解和实战指南,帮助理解Milvus的核心概念、功能和应用场景,并通过具体的代码示例和图片链接,展示如何在实际项目中应用Milvus。文章将涵盖Milvus的基本概念、安装部署、数据导入、搜索查询等多个方面,并提供相关的FAQ,解答用户可能的疑问。
Milvus是一个开源的向量数据库,专门设计用于处理大规模向量数据的存储、索引和管理。与传统的关系型数据库不同,Milvus专注于处理非结构化数据,如图像、视频、音频等,通过将这些数据转换为向量,实现高效的相似性搜索。
Milvus的主要目标是存储、索引和管理由深度神经网络和其他机器学习模型生成的大规模嵌入向量。这些向量可以表示非结构化数据的特征,通过计算向量之间的相似性距离,Milvus能够分析两个向量之间的相关性。
在深入了解Milvus之前,有几个关键概念需要了解:
非结构化数据包括图像、视频、音频和自然语言等,这些数据不遵循预定义的模型或组织方式。Milvus可以将这些数据转换为向量,实现向量化存储和搜索。
嵌入向量是非结构化数据的特征抽象,通过现代嵌入技术,如深度学习和神经网络,将非结构化数据转换为向量。
向量相似性搜索是将一个向量与数据库中的向量进行比较,以找到与查询向量最相似的向量的过程。Milvus通过近似最近邻(ANN)搜索算法加速搜索过程。
Milvus具有以下几个优点:
在Milvus中,索引是数据的组织单元。在搜索或查询插入的实体之前,必须声明索引类型和相似性度量标准。Milvus支持多种索引类型和度量标准,以适应不同的搜索需求。
Milvus支持的索引类型包括HNSW、FLAT、IVF_FLAT、IVF_SQ8、IVF_PQ、SCANN和DiskANN等,这些索引类型使用近似最近邻搜索(ANNS)来加速搜索过程。
Milvus支持多种相似性度量标准,包括余弦相似度、欧氏距离(L2)、内积(IP)、汉明距离和Jaccard相似度等,这些度量标准用于衡量向量之间的相似性。
Milvus可以应用于多种场景,包括图像相似性搜索、视频相似性搜索、音频相似性搜索、推荐系统、问答系统、DNA序列分类和文本搜索引擎等。
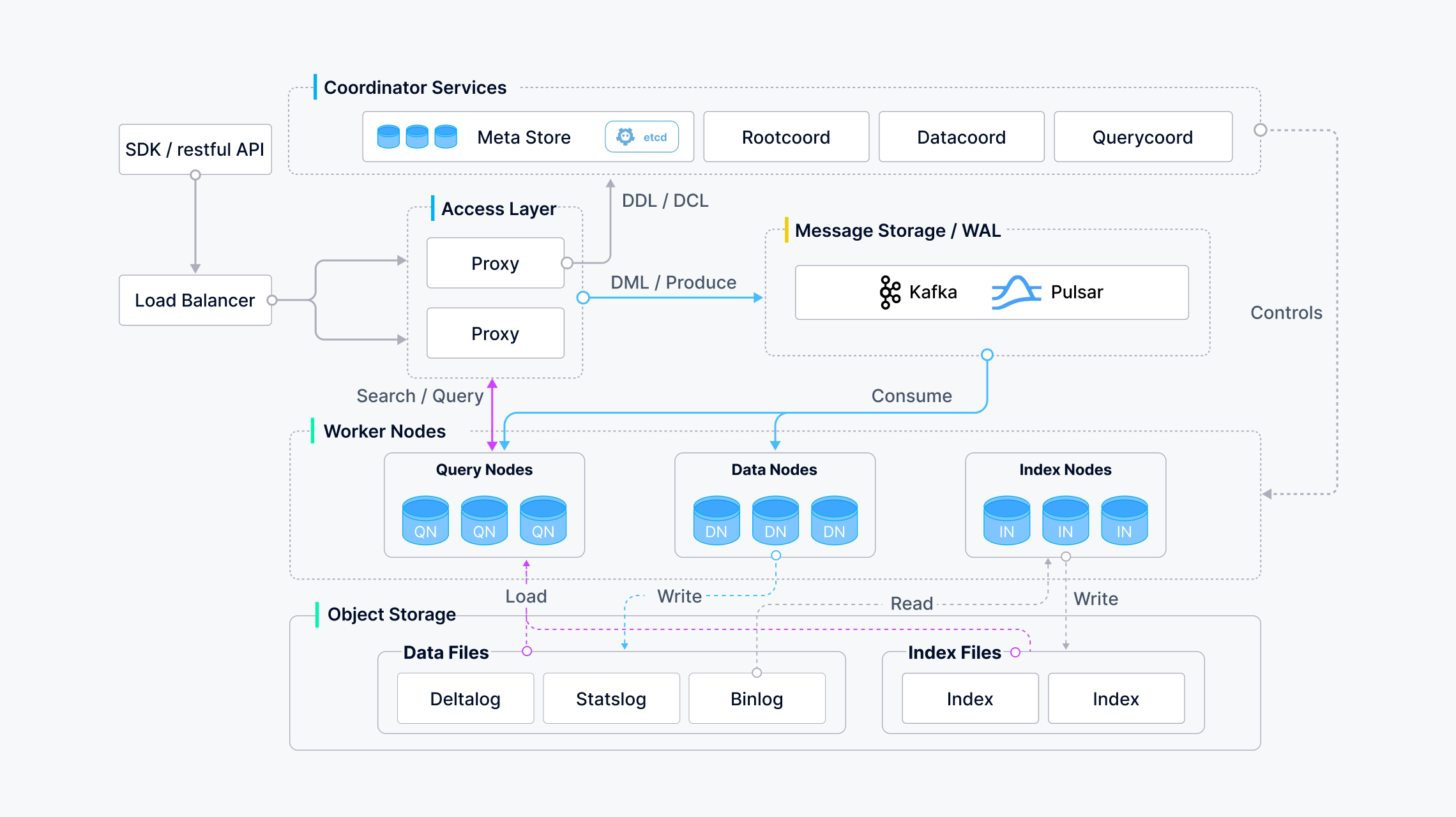
Milvus作为一个云原生向量数据库,通过设计将存储和计算分离,增强了系统的弹性和灵活性。Milvus的系统分为访问层、协调器服务、工作节点和存储四个层级,所有组件都是无状态的。
在探索各种向量数据库选项时,Milvus以其独特的功能和优势脱颖而出。Milvus不仅支持基本的向量相似度搜索,还支持高级功能,如稀疏向量、批量向量、过滤搜索和多向量搜索功能。Milvus支持多种部署模式和多个SDK,在一个强大的集成生态系统中实现。
Milvus的主要亮点包括:
本章节将介绍如何在本地运行Milvus Lite,以及如何使用Docker Compose运行Milvus。
Milvus Lite是Milvus的轻量级版本,可以被导入到Python应用程序中,提供Milvus的核心向量搜索功能。
Milvus Lite与Milvus共享相同的API,并覆盖了大部分Milvus的功能。使用相同的客户端代码,可以在Milvus Lite中快速演示少于百万个向量,或者在单台机器上托管Milvus Docker容器的小规模应用程序,最终在Kubernetes上进行大规模生产部署。
Milvus Lite支持Ubuntu和MacOS操作系统。
要设置Milvus Lite,请在终端中运行以下命令:
pip install "pymilvus>=2.4.2"您可以按照以下方式连接到Milvus Lite:
from pymilvus import MilvusClient
client = MilvusClient("milvus_demo.db")本页面介绍如何使用Docker Compose在Docker中启动Milvus实例。
需要安装Docker,并查看硬件和软件要求。
Milvus在其存储库中提供了一个Docker Compose配置文件。要使用Docker Compose安装Milvus,只需运行以下命令:
$ wget https://github.com/milvus-io/milvus/releases/download/v{{var.milvus_release_version}}/milvus-standalone-docker-compose.yml -O docker-compose.yml
$ sudo docker compose up -d本主题描述了如何通过批量加载在Milvus中导入数据。
您可以按行或列准备数据文件。
将数据导入到集合中。
在插入数据后,下一步是在Milvus集合中执行相似性搜索。
有各种搜索类型可满足不同需求,包括基本搜索、过滤搜索、范围搜索和分组搜索。
在发送search请求时,您可以提供一个或多个向量值,表示您的查询嵌入,以及一个limit值,指示要返回的结果数量。
单向量搜索是Milvus中最简单的search操作形式,旨在找到与给定查询向量最相似的向量。
过滤搜索对向量搜索应用标量过滤器,允许您根据特定条件细化搜索结果。
like运算符通过评估包括前缀、中缀和后缀在内的模式来增强字符串搜索。
范围搜索允许您查找与查询向量在指定距离范围内的向量。
在Milvus中,通过特定字段进行分组搜索可以避免结果中相同字段项的冗余。
问:Milvus支持哪些编程语言?
答:Milvus支持Python、Java、NodeJS、Go、Restful API、C#和Rust等多种编程语言。
问:Milvus如何处理大规模数据集?
答:Milvus通过其定制的分布式架构轻松扩展,可容纳从小型数据集到超过100亿向量的集合。
问:Milvus如何实现向量相似性搜索?
答:Milvus通过近似最近邻(ANN)搜索算法加速搜索过程,支持多种相似性度量标准,包括余弦相似度、欧氏距离(L2)、内积(IP)、汉明距离和Jaccard相似度等。
问:Milvus有哪些应用场景?
答:Milvus可以应用于图像相似性搜索、视频相似性搜索、音频相似性搜索、推荐系统、问答系统、DNA序列分类和文本搜索引擎等多种场景。
问:如何在本地运行Milvus?
答:可以在本地运行Milvus Lite,或者使用Docker Compose在Docker中启动Milvus实例。






