

AI视频剪辑工具:解锁创作的无限可能

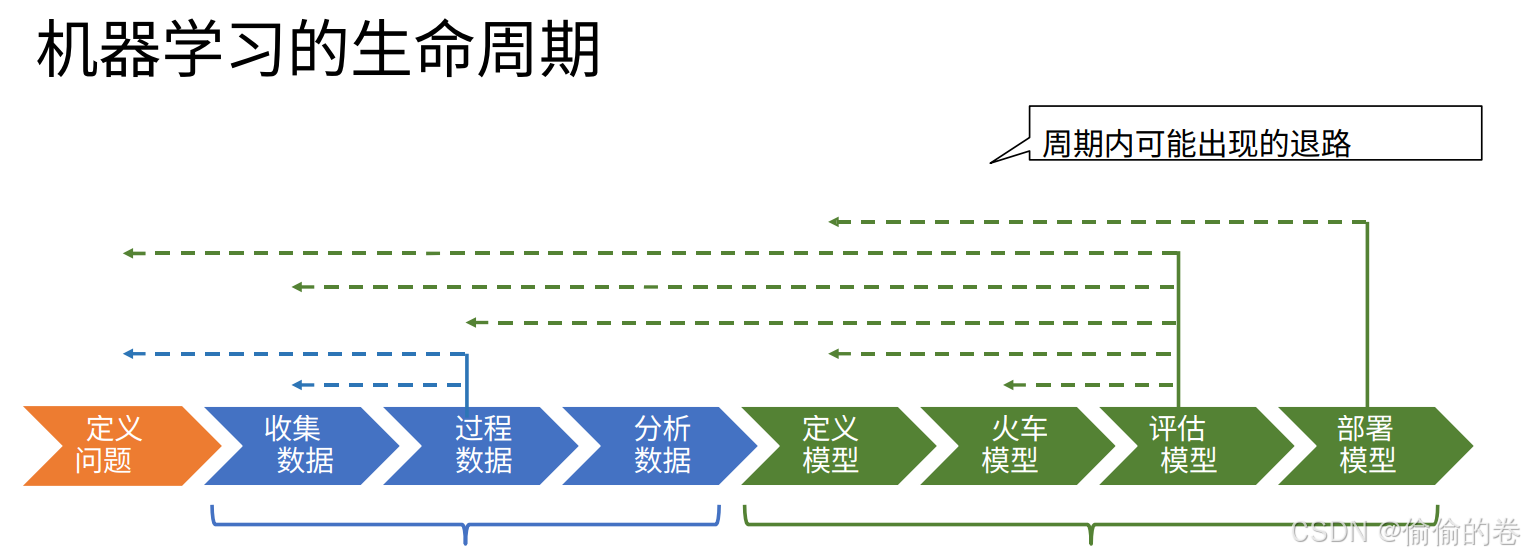
这篇文章是为刚开始接触机器学习的朋友们准备的入门指南。内容从机器学习的基础概念开始,包括其发展历史、分类、数学基础、模型实现以及实际应用领域。通过阅读这篇文章,读者可以对机器学习有一个全面的基础了解,为后续深入学习打下坚实的基础。
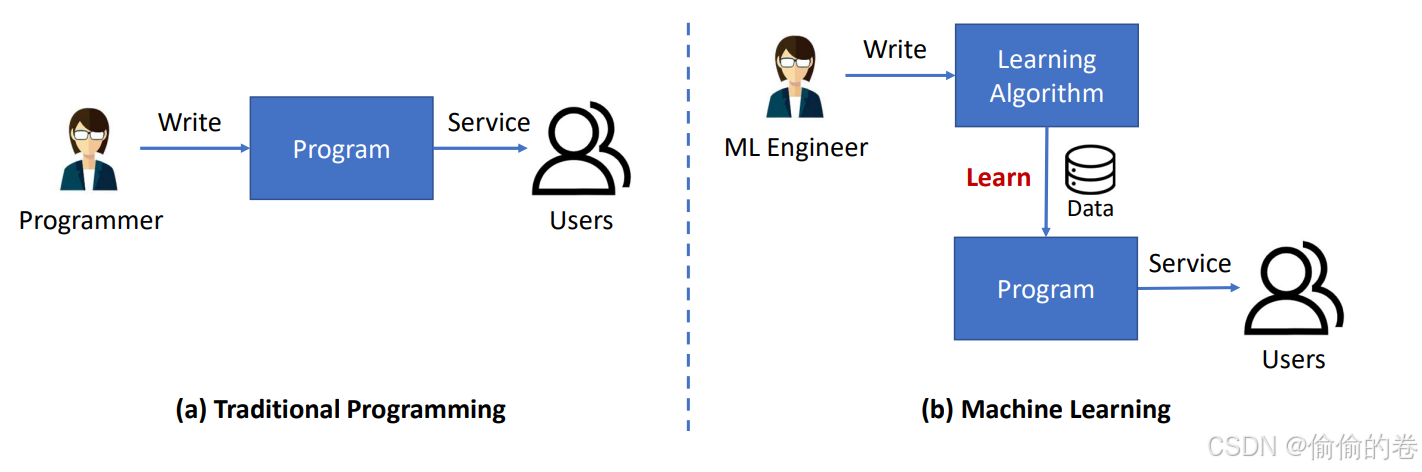
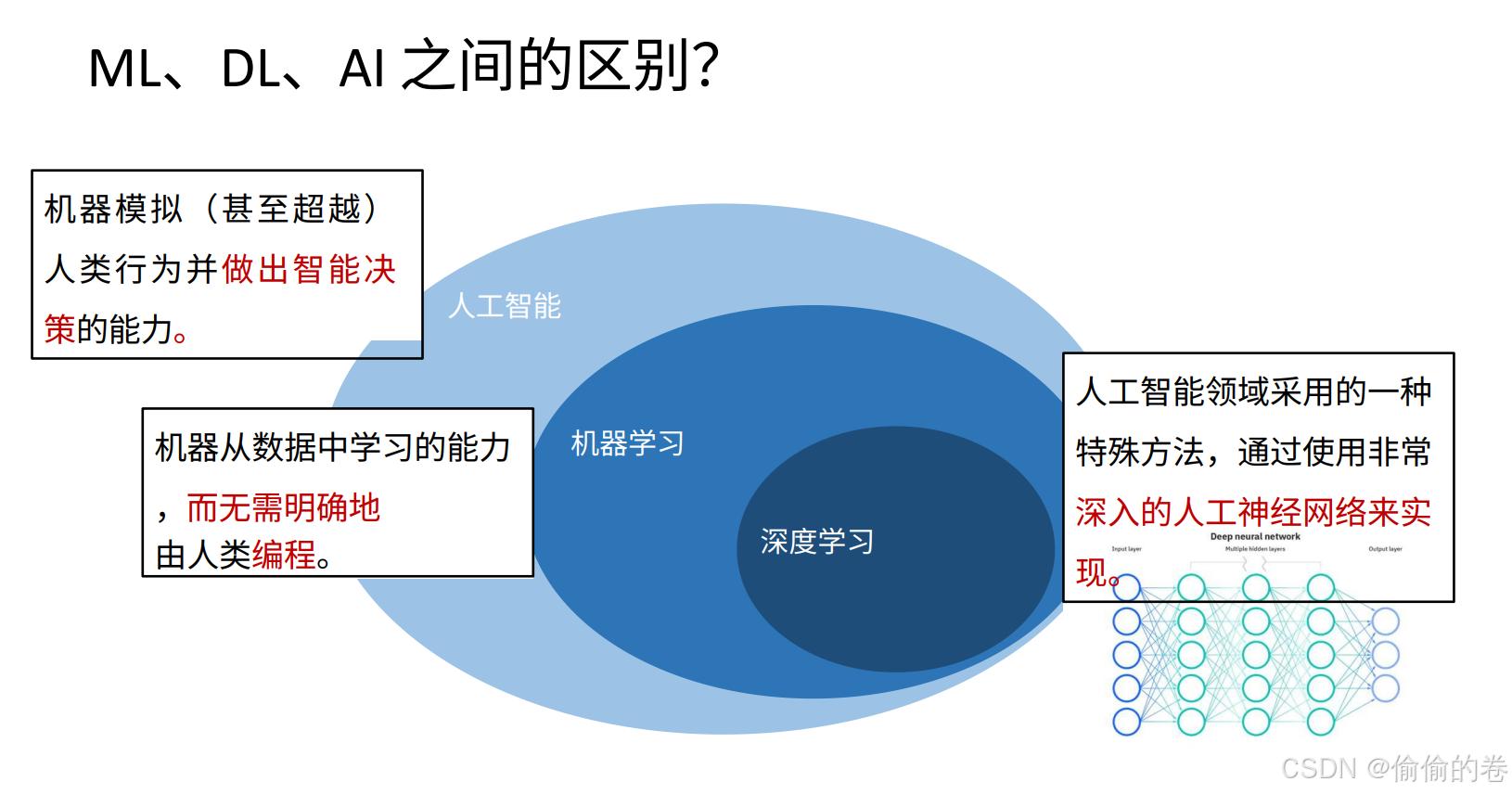
机器学习(Machine Learning)是一种通过数据驱动的方法让计算机自动改进和学习的技术。它是人工智能的一个重要分支,旨在通过构建算法和模型,使计算机能够从数据中提取规律和知识,而无需明确的编程指令。与传统编程不同,机器学习通过观察数据中的模式来进行预测或决策。
机器学习在现代科技中扮演着重要角色。它被广泛应用于推荐系统、图像识别、语音识别等多个领域,为这些领域带来了显著的性能提升。通过机器学习,计算机可以在处理海量数据时,自动发现数据中的隐藏模式,从而提高效率和准确性。
机器学习的核心在于算法、数据和模型。算法是用来从数据中提取信息的关键,数据是机器学习的基础,而模型则是用于预测和决策的工具。三者相辅相成,构成了机器学习的完整体系。
机器学习的起源可以追溯到20世纪中期。1943年,人工神经元模型的建立标志着机器学习的开端。随后,1957年感知器的发明奠定了机器学习的基础,开启了人工智能研究的新篇章。
1986年,反向传播算法的提出使得神经网络得以复兴。2012年,卷积神经网络在ImageNet竞赛中获胜,标志着深度学习的突破。2016年,AlphaGo的成功展示了机器学习在强化学习领域的潜力。
未来,机器学习的发展将会更加注重自动化与分布式学习。自动化机器学习(AutoML)和联邦学习(Federated Learning)是其中的两个重要方向,它们将进一步提升机器学习的效率和安全性。
监督学习是一种依赖于标记数据进行训练的机器学习方法。在这种学习方法中,每个输入数据都有一个已知的输出,模型通过学习这些映射关系来进行预测。常见的应用包括分类和回归任务。
无监督学习则在没有标记数据的情况下进行训练。模型通过识别数据中的模式和结构来进行任务,例如聚类和降维。无监督学习在发现数据的潜在结构方面具有重要作用。
强化学习通过与环境的交互来学习策略,以最大化某种累积奖励。它广泛应用于游戏AI、机器人控制等领域。强化学习的特点是通过试错法来改进策略,以达到最佳的执行效果。
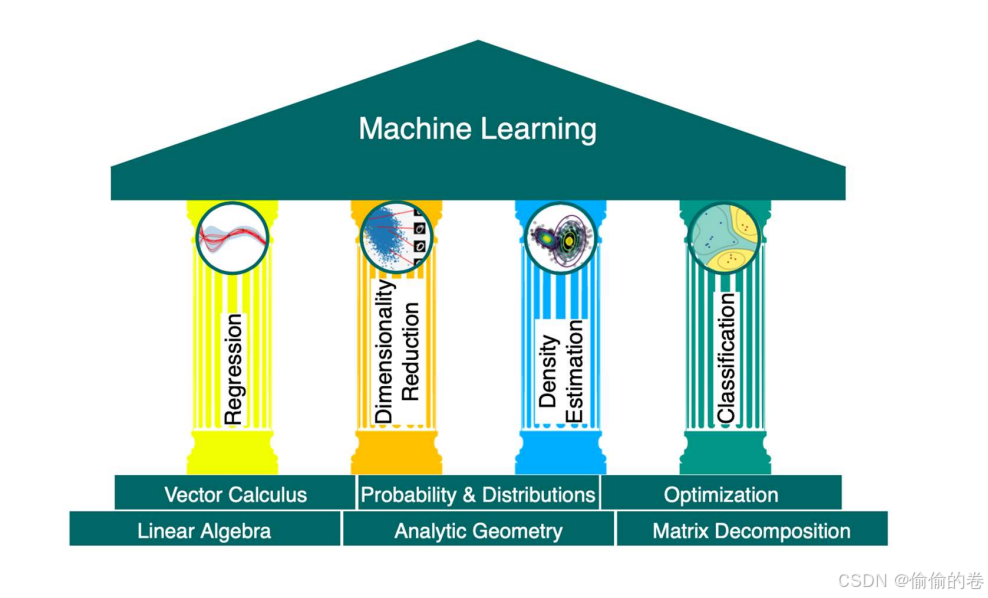
线性代数在机器学习中占据重要地位。许多机器学习算法依赖于矩阵运算和向量操作。矩阵的乘法、转置、求逆等操作在数据处理和模型训练中广泛应用。
微积分是优化算法的基础。在机器学习中,梯度下降法是一种常用的优化算法,通过计算损失函数的导数来更新模型参数,以达到最小化误差的目的。
概率与统计为机器学习提供了理论支持。它们用于建模数据的不确定性,描述模型的性能,并在某些算法中,例如朴素贝叶斯分类器中,发挥关键作用。
模型的实现离不开算法和代码的支持。在机器学习中,Python是一种常用的编程语言,借助其丰富的库,如Numpy、pandas、Scikit-learn、PyTorch,开发者可以快速实现各种机器学习模型。
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.datasets import make_regression
# 生成数据
X, y = make_regression(n_samples=100, n_features=1, noise=0.1)
# 分割数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 创建模型并训练
model = LinearRegression()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)机器学习在图像和视频处理中的应用非常广泛。通过卷积神经网络(CNN),计算机可以实现图像分类、目标检测等任务。这些技术在自动驾驶、医疗影像分析中都有重要作用。
在自然语言处理领域,机器学习用于文本分类、情感分析、机器翻译等。通过序列到序列模型(Seq2Seq),计算机可以将一种语言翻译成另一种语言,极大地提升了翻译服务的效率。
自动驾驶汽车中,机器学习用于识别道路、车辆、行人等。通过传感器数据的实时分析,车辆可以规划行驶路径,实现安全高效的自动驾驶。
目前,机器学习已经在多个领域取得了显著进展。但其发展仍然面临挑战,包括数据隐私问题、算法的解释性等。
未来,机器学习将更加注重自动化与协作学习。特别是在数据隐私日益重要的今天,联邦学习等技术将会有更广泛的应用。
机器学习作为一门迅速发展的技术,不断推动着各个行业的变革。通过不断的探索和创新,机器学习将为人类创造更多的可能性。






