

Node.js 后端开发指南:搭建、优化与部署

语言建模的研究始于20世纪90年代,最初采用了统计学习方法,通过前面的词汇来预测下一个词汇。这种方法在理解复杂语言规则方面存在一定局限性。随后,研究人员不断尝试改进,2003年,深度学习先驱Bengio在他的经典论文《A Neural Probabilistic Language Model》中,首次将深度学习的思想融入到语言模型中,使用了更强大的神经网络模型,为计算机提供了更强大的“大脑”来理解语言。
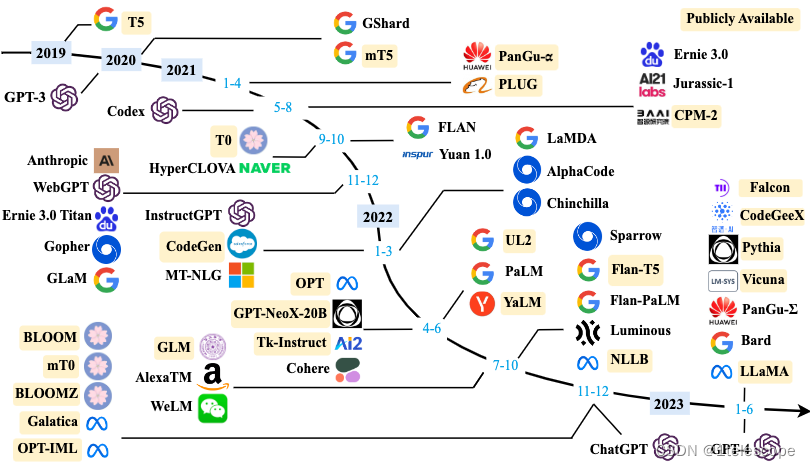
大约在2018年左右,研究人员引入了Transformer架构的神经网络模型,通过大量文本数据训练这些模型,使它们能够通过阅读大量文本来深入理解语言规则和模式。这种方法在很多任务上表现得非常好。
大语言模型(LLM),也称大型语言模型,是一种人工智能模型,旨在理解和生成人类语言。这些模型在大量的文本数据上进行训练,例如国外的GPT-3、GPT-4、PaLM、Galactica和LLaMA等,国内的有ChatGLM、文心一言、通义千问、讯飞星火等。
随着语言模型规模的扩大,模型展现出了一些惊人的能力,通常在各种任务中表现显著提升。这时我们进入了大语言模型(LLM)时代。为了探索性能的极限,许多研究人员开始训练越来越多庞大的语言模型,例如拥有1750亿参数的GPT-3和5400亿参数的PaLM。
LLM已经在自然语言处理领域产生了深远的影响。它可以帮助计算机更好地理解和生成文本,包括写文章、回答问题、翻译语言。
在信息检索领域,LLM可以改进搜索引擎,让我们更轻松地找到所需的信息。在计算机视觉领域,研究人员还在努力让计算机理解图像和文字,以改善多媒体交互。
上下文学习能力是由GPT-3首次引入的。这种能力允许语言模型在提供自然语言指令或多个任务示例的情况下,通过理解上下文并生成相应输出的方式来执行任务,而无需额外的训练或参数更新。
input = 






