

大模型RAG技术:从入门到实践

在本篇文章中,我们将深入探讨稳定扩散技术(Stable Diffusion),这种新兴的机器学习技术是如何结合数学模型和深度学习架构来生成高质量的图像。我们会从基础概念、模型架构、训练过程等方面进行详细的剖析,并结合代码示例来帮助读者从零开始构建自己的扩散模型。同时,本文还将解答一些关于扩散模型的常见问题,并提供相关的学习资源和工具。
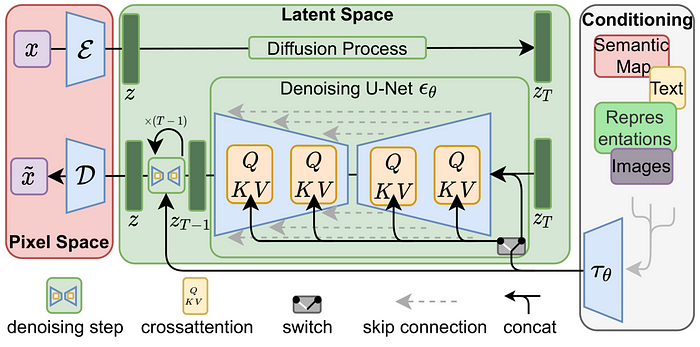
稳定扩散技术是一种基于潜在扩散模型(Latent Diffusion Models)的新型机器学习技术。其核心思想是通过扩散过程,将高维度的复杂数据映射到低维度空间进行训练。该技术主要包括以下三个组件:
文字编码器(Text Encoder):用于特征化输入文字内容的强大工具,可以是GPT、BERT等主流Transformer模型,负责将文本信息转换为模型可理解的特征向量。
扩散模型(Diffusion Model):通过降噪过程,将潜在空间中的图像逐步还原为真实图像。这个过程使用U-Net架构和注意力机制来提高模型表现,与传统的扩散模型相比,具有更高的精确性和鲁棒性。
变分自编码器(VAE):负责图像在潜在空间的压缩与重建,使得模型能够更快更好地学习图像特征。
在稳定扩散模型中,有几种不同的采样方法用于数据生成。以下是一些常见的采样方法:
高斯采样(Gaussian sampling):通过将高斯噪声添加到数据中生成新样本,有助于模型更好地理解数据的分布和特征。
朗之万采样(Langevin sampling):基于随机梯度下降的采样方法,通过在梯度中添加随机噪声生成新样本,帮助模型处理高度非线性的数据。
麦特波利斯-黑斯廷斯采样(Metropolis-Hastings sampling):一种马尔科夫链蒙特卡罗(MCMC)方法,用于生成一个表示数据分布的序列,帮助模型理解数据的复杂性和不确定性。

Dreambooth是由Google在2022年提出的一种技术,旨在保留图像特征的同时生成多样化的样式。其核心思想是基于生成对抗网络(GAN)模型,通过生成器与判别器的对抗来提高图像的质量和真实度。通过对Stable Diffusion进行微调,Dreambooth 能够在保持图像特征的前提下,生成多种风格的图像。

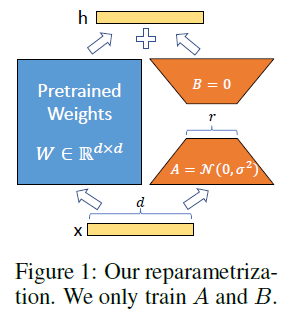
LoRA(Low-rank adaptation of large language models)是微软开发的一种局部调整模型,轻量且高效。其主要原理是将低秩矩阵分解应用于大型语言模型中,从而减少存储需求和计算成本。通过自适应学习方法调整模型参数,以更好地适应不同的语言模型和文本数据。
ControlNet模型由系统动态和控制器两个部分组成。系统动态部分处理非线性问题,而控制器部分则调节模型输出。通过根据系统状态和期望输出值的调整,ControlNet能有效提高模型的性能和准确度,成为目前Stable Diffusion应用中最热门的技术之一。
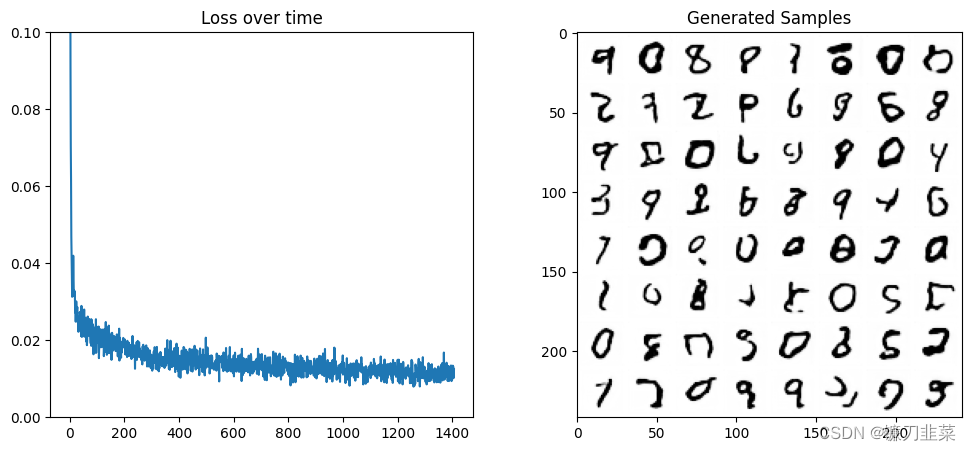
为了更好地理解扩散模型,我们尝试从零开始搭建一个简单的扩散模型。以下是实现过程:
环境准备:配置Google Colab环境,并安装所需的Python库,如diffusers。
退化过程:通过添加噪声模拟数据退化,定义一个函数来实现这一过程。
UNet网络:搭建一个简单的UNet模型,用于接收噪声图像并输出去噪结果。
训练模型:通过均方误差衡量模型输出与真实值的差距,逐步优化模型参数。
采样过程:从随机噪声开始,不断迭代去噪,逐步逼近目标图像。
高级模型训练:使用UNet2DModel,结合时间步的调节,提升生成图像的质量。
扩散模型作为生成式AI的重要组成部分,其技术的进步为图像生成、文本生成等领域带来了新的可能。随着技术的不断提升,未来扩散模型将在更多领域得到应用,并与其他人工智能技术紧密结合,为我们带来更智能、更高效的解决方案。

问:什么是扩散模型中的噪声调度器?
问:如何选择合适的采样方法?
问:Dreambooth技术如何影响艺术风格的生成?







