

Stable Diffusion Agent 开发:技术解析与应用前景

7月6日,快手在世界人工智能大会上宣布其文生图大模型可图(Kolors)将全面开源。这一模型支持中英文双语,生成效果可与Midjourney-v6媲美,支持长达256字符的文本输入,具备优异的英文和中文文字生成能力。目前,可图(Kolors)已在Huggingface和GitHub上线,开放模型权重和完整代码供个人开发者免费使用。

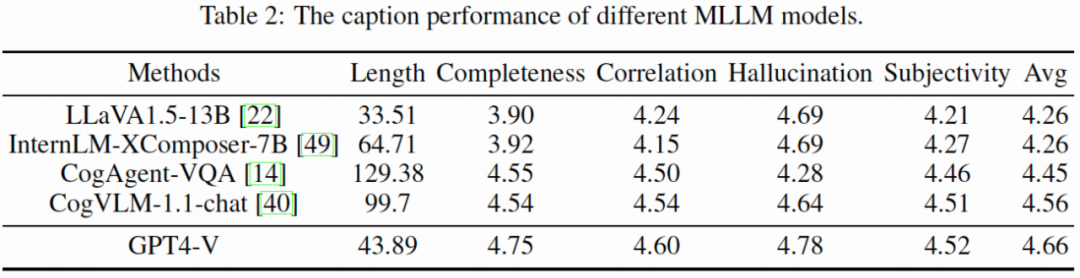
在智源FlagEval文生图模型评测中,可图(Kolors)表现优异,主观综合评分全球第二,尤其在图像质量上表现突出,显著优于其他模型。

可图(Kolors)采用了大语言模型ChatGLM3进行文本表征,文本提示词长度达256字符,远超CLIP的77字符。在GLM的加持下,可图(Kolors)展现出强大的复杂文本理解能力,能够正确绘制多主体画面,并且准确对应多种颜色的服饰。

在模型训练中,使用CogVLM进行打标,采用混合描述的方式提高文本描述的精细化程度。
可图(Kolors)是首个原生支持中文文字生成的文生图模型。通过专门构建的中文写字数据集,Kolors能够准确绘制结构复杂的汉字,同时也支持英文文字生成,具备设计美学与创意。

可图(Kolors)在概念学习和质量微调阶段,采用了数十亿图像文本对训练,涵盖广泛实体概念,并通过加噪策略优化提升生成高分辨率图像的稳定性和美感。

可图团队提出了KolorsPrompts评测集,涵盖14个垂类和12个挑战项,通过专业评测人员的打分,可图在综合满意度和图像质量上表现出色,达到Midjourney-v6水平。

通过Dreambooth & Lora实现模型微调和IP定制,如快手吉祥物小快和招财鸭IP。

人像ID保持,支持多种风格化人像,增加玩法趣味性。

虚拟试穿技术的应用,支持多种服饰细节的提取与表征,实现自然的人物试穿效果。

快手计划陆续开源可图(Kolors)的相关应用,这将为开发者提供全面的工具和资源,推动文生图技术的进步和普及。自开源以来,可图大模型受到了广泛关注和使用,Kolors-ControlNet等生态插件能力也在不断提升。
问:可图(Kolors)与其他文生图模型有何不同?
问:可图(Kolors)开源后开发者可以做什么?
问:如何体验可图的虚拟试衣功能?
问:可图(Kolors)在图像生成领域的应用前景如何?
问:可图(Kolors)的主要特点是什么?







