

PixVerse V3 API Key 获取:全面指南与实践

Kandinsky 3.0 是由俄罗斯最大的银行和金融服务公司 Sber 的人工智能部门 Sber AI 和 AIRI 合作推出的最新文本到图像生成模型。该模型基于潜在扩散技术,旨在改善对文本的理解和生成图像的质量。Kandinsky 3.0 的推出标志着文本到图像生成领域的又一重要进展,并通过开源代码和模型的方式促进了该领域的进一步发展。
近年来,文本到图像生成模型的质量有了显著提高,这主要归功于扩散概率模型的发明与应用。然而,尽管技术上取得了长足的进步,文本到图像生成任务仍然对研究人员提出了严峻的挑战。随着商业和设计领域对该技术的需求不断增加,与复杂文本描述相一致的生成能力显得尤为重要。
Kandinsky 3.0 是在前代 Kandinsky 模型基础上进行的重大改进。其采用了简化的单阶段 pipeline,通过直接使用文本嵌入进行生成,无需任何额外的先验知识,极大地提升了文本理解和图像质量。
Kandinsky 3.0 的架构设计采用了新的单阶段 pipeline,取代了前代使用的两阶段扩散映射方法。在新架构中,单阶段 pipeline 能够直接从文本嵌入生成图像,这种设计大大简化了模型的复杂程度,提高了生成效率和质量。
在 Kandinsky 3.0 中,U-Net 架构经过了多次实验与调整,最终选择了基于 ResNet-50 的残差模块作为核心去噪模块。通过增加网络的深度和优化参数分布,新架构在保持参数数量不变的情况下,提升了图像生成的效果。
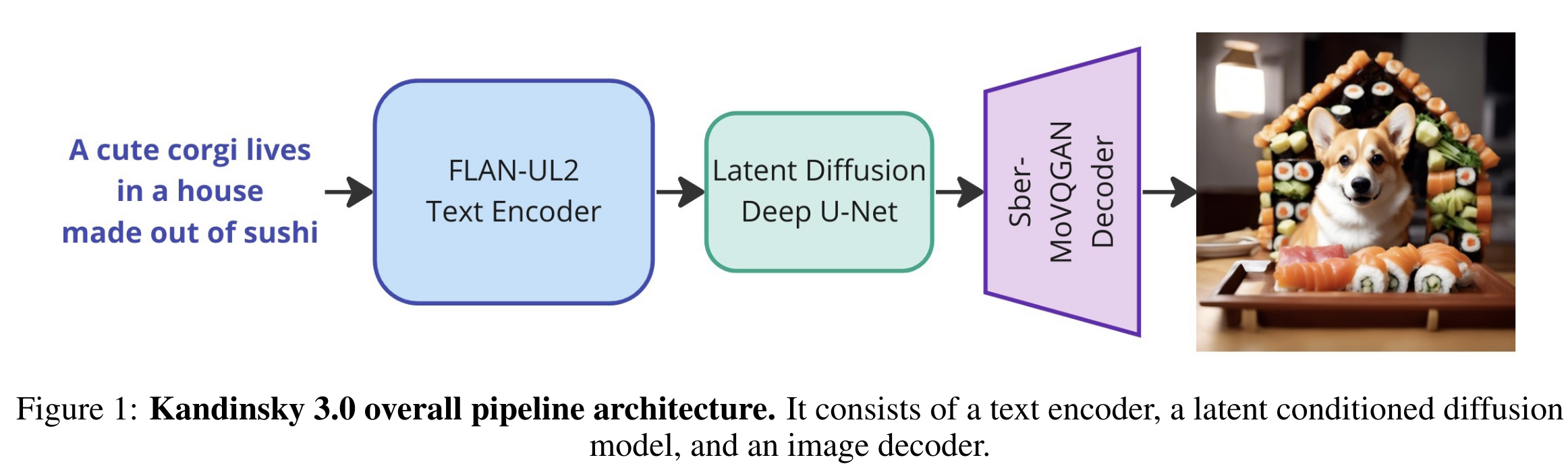
文本编码器在 Kandinsky 3.0 中扮演了重要角色,使用了 Flan-UL2 20B 模型的 8.6B 编码器。通过在大量文本语料库上的预训练及监督微调,该文本编码器显著增强了模型的文本理解能力,从而提升了生成图像的准确性。
在 Kandinsky 3.0 的训练过程中,使用了庞大的在线收集文本图像对数据集。为了确保数据质量,模型对数据进行了严格的审美质量过滤、水印检测、CLIP 相似性检查和感知哈希重复检测,特别是针对俄罗斯文化进行了特别的数据收集和标注。
Kandinsky 3.0 的训练过程分为多个阶段,以不同分辨率和数据集进行训练:
Kandinsky 3.0 支持图像修复(Inpainting)和扩展(Outpainting),通过在基础模型权重基础上对 U-Net 输入卷积层的修改,使其能够接受图像 latent 和掩码输入,从而实现图像的局部修复和全局扩展。

利用 Deforum 技术,Kandinsky 3.0 还支持从图像生成视频,涉及一系列迭代步骤,如图像的三维表示转换、空间变换应用、2.5D 场景投影回 2D 图像等。
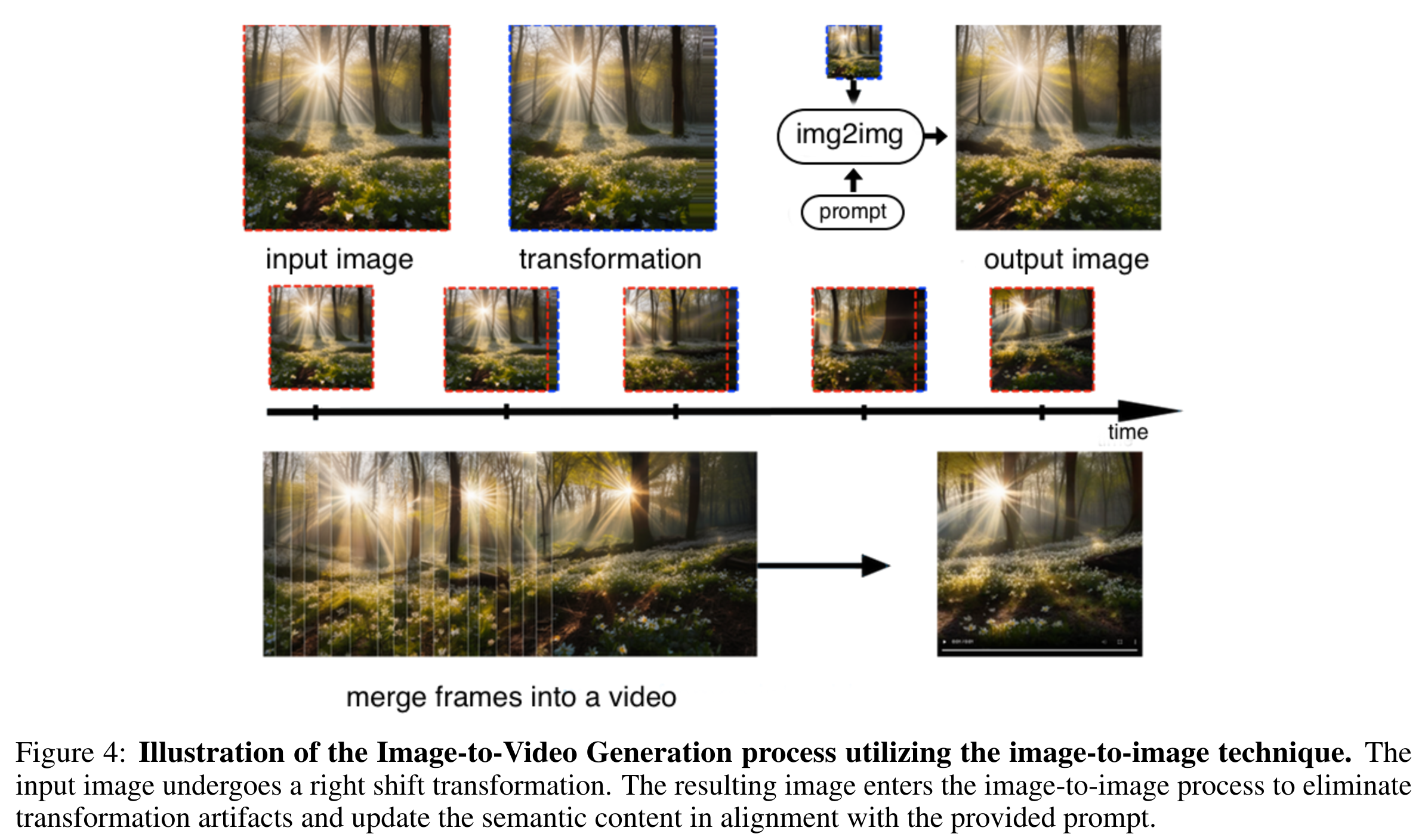
在 Kandinsky 3.0 的基础上,开发了文本到视频的生成流程 Kandinsky Video,通过文本编码器和图像解码器生成关键帧,并在帧之间进行插值,生成流畅的视频效果。
在人工评测中,Kandinsky 3.0 的图像质量和文本理解能力得到了验证。在与先前版本和其他模型的对比中,Kandinsky 3.0 在大多数情况下表现优异。
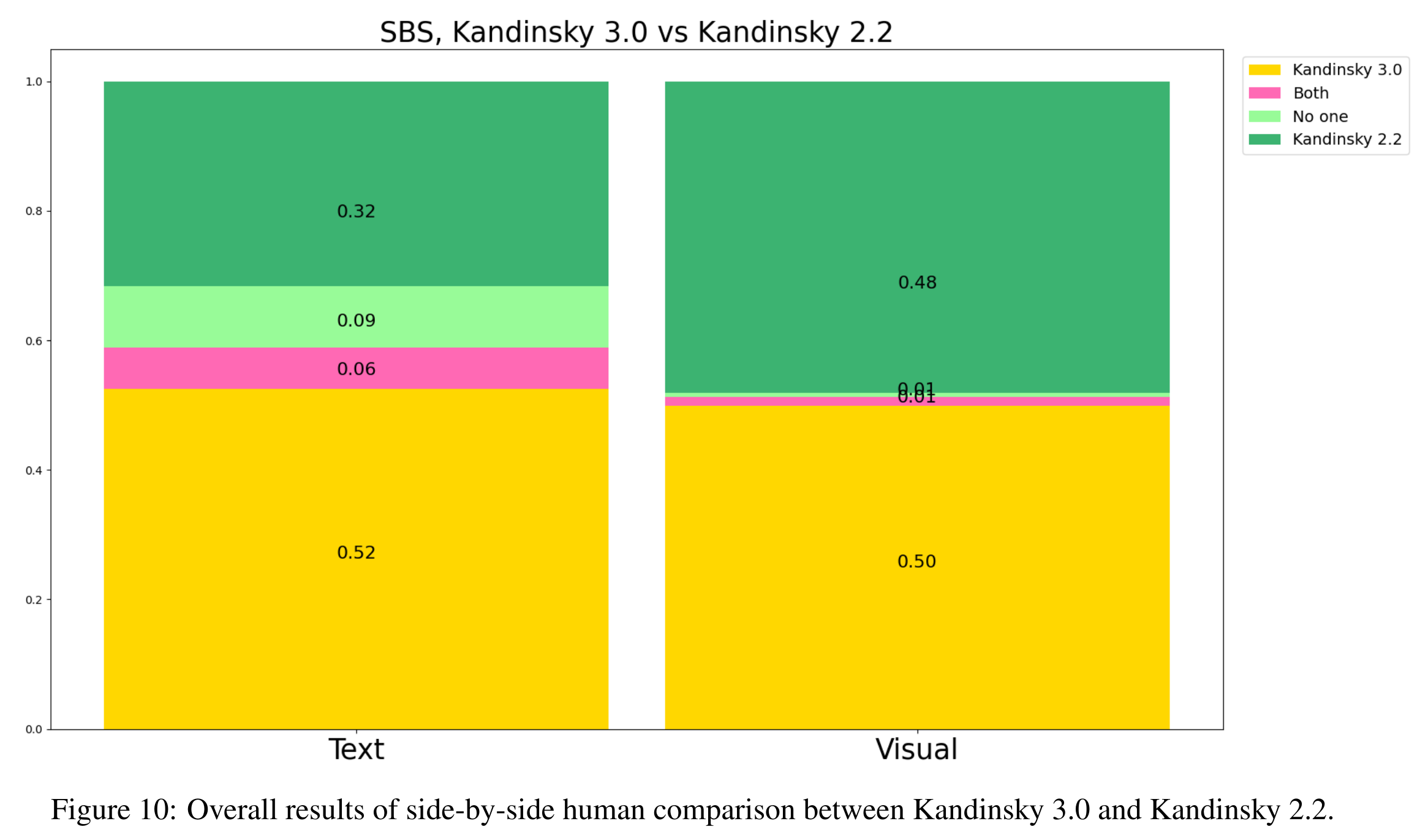
尽管在与 DALLE 的对比中,Kandinsky 3.0 的表现略逊一筹,但在与 SDXL 的对比中,整体效果优于 SDXL,显示了其在生成图像质量上的显著提升。

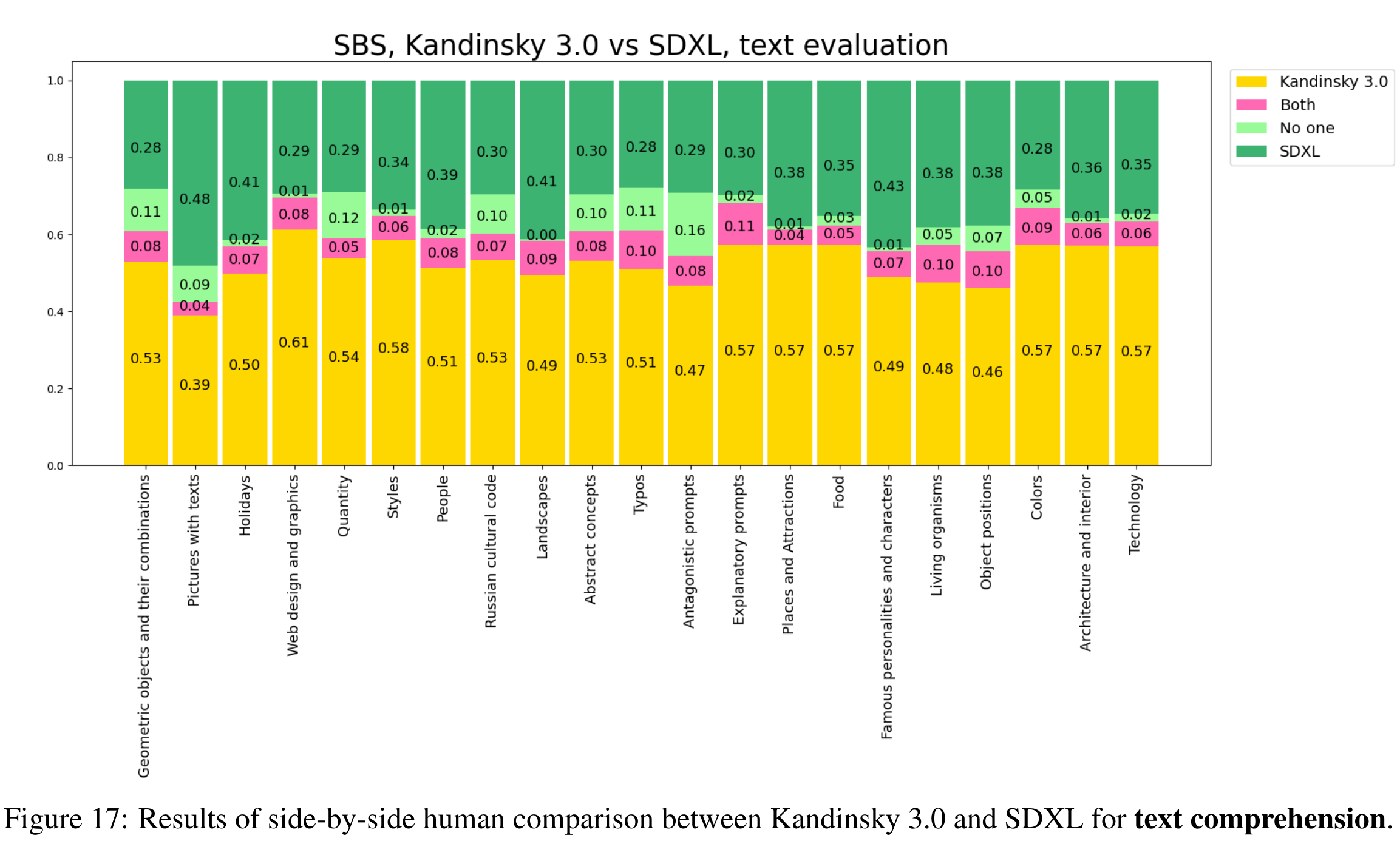
Kandinsky 3.0 的推出不仅提升了文本到图像生成的质量和效率,也表明开源在推动技术进步中的重要作用。未来,随着更多相关技术和数据的引入,Kandinsky 3.0 有望在更广泛的应用场景中发挥更大的作用。
问:Kandinsky 3.0 与前代模型相比有哪些改进?
问:Kandinsky 3.0 如何处理多语言文本输入?
问:如何使用 Kandinsky 3.0 进行图像到视频的生成?





