

豆包 Doubao Image API 价格全面解析

Java Grok是一个功能强大的日志解析库,它以其简单易用的API和强大的解析能力,成为开发者处理日志文件的得力助手。通过Java调用Grok API,开发者可以轻松解析和分析各种格式的日志文件,从而提高系统的监控和调试效率。
Java Grok API是一个用于解析和分析日志文件的工具,它采用了正则表达式的模式匹配技术来提取日志中的关键信息。这使得开发者能够轻松地从复杂的日志数据中提取有用的信息,而无需手动编写复杂的正则表达式。
Java Grok提供了一系列内置的解析模式,这些模式涵盖了各种常见的日志格式,如Apache、Nginx、系统日志等。通过这些预定义的模式,开发者可以快速实现对日志数据的解析和分析,减少了开发过程中对日志格式的深度了解需求。
此外,Java Grok还支持自定义解析模式,这使得开发者可以根据特定的日志格式和业务需求,编写自己的解析规则,从而提高日志解析的灵活性和适应性。
Grok模式是由一个或多个模式组件构成的字符串,每个组件都用于匹配日志中的特定字段。通过使用Grok模式,开发者可以定义日志中每个字段的格式和位置,从而实现对日志数据的准确解析。
例如,下面是一个基本的Grok模式示例:
%{IPV4:client_ip} %{WORD:method} %{URIPATHPARAM:url} %{NUMBER:status}这个模式用于匹配一个简单的HTTP日志行,其中包含客户端IP地址、请求方法、URL路径和响应状态码。
每个模式组件都有一个名称和一个类型,名称用于标识匹配的字段,类型用于定义匹配的格式。通过这种方式,Grok模式可以实现对日志中各个字段的精确匹配和提取。
在Maven项目中使用Java Grok非常简单,只需在pom.xml文件中添加以下依赖即可:
io.krakens
java-grok
0.1.9
添加依赖后,Maven会自动下载所需的库文件,使得开发者可以在项目中直接调用Grok API进行日志解析。
下面是一个简单的Java Grok测试示例,展示了如何使用Grok API解析一行HTTP日志:
public static void main(String[] args) {
GrokCompiler grokCompiler = GrokCompiler.newInstance();
grokCompiler.registerDefaultPatterns();
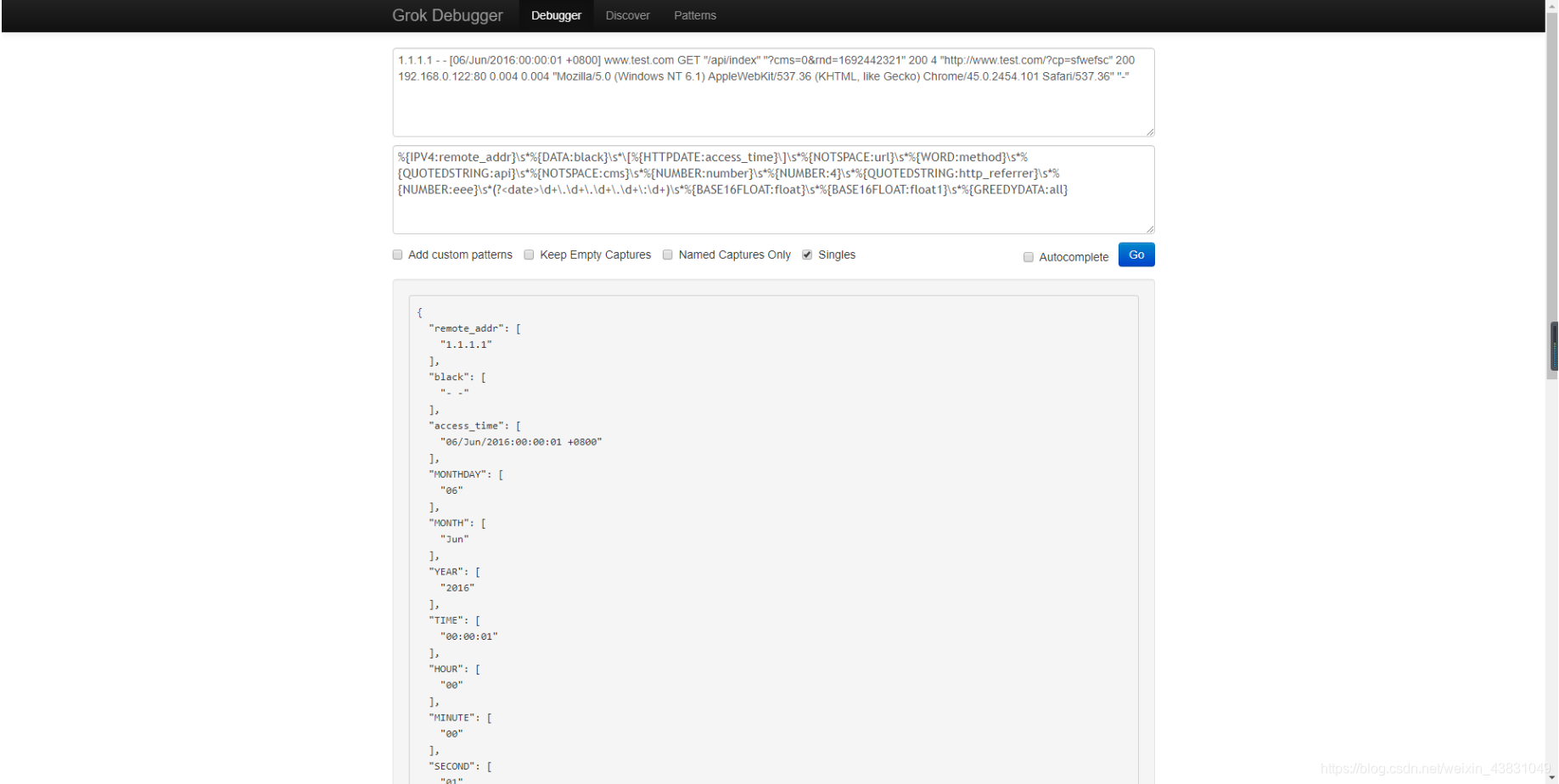
Grok grok = grokCompiler.compile("%{IPV4:remote_addr}\s*%{DATA:black}\s*\[%{HTTPDATE:access_time}\]\s*%{NOTSPACE:url}\s*%{WORD:method}\s*%{QUOTEDSTRING:api}\s*%{NOTSPACE:cms}\s*%{NUMBER:number}\s*%{NUMBER:4}\s*%{QUOTEDSTRING:http_referrer}\s*%{NUMBER:eee}\s*(?\d+\.\d+\.\d+\.\d+\:\d+)\s*%{BASE16FLOAT:float}\s*%{BASE16FLOAT:float1}\s*%{GREEDYDATA:all}");
String logMsg = "1.1.1.1 - - [06/Jun/2016:00:00:01 +0800] www.test.com GET "/api/index" "?cms=0&rnd=1692442321" 200 4 "http://www.test.com/?cp=sfwefsc" 200 192.168.0.122:80 0.004 0.004 "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36" "-"";
Match grokMatch = grok.match(logMsg);
Map resultMap = grokMatch.capture();
System.out.println(resultMap);
}代码的输出结果将是一个包含日志信息各个字段的Map对象。例如:
{date=192.168.0.122:80, all="Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36" "-", remote_addr=1.1.1.1, float1=0.004, MONTH=Jun, method=GET, eee=200, HOUR=00, black=- -, cms=?cms=0&rnd=1692442321, TIME=00:00:01, float=0.004, INT=+0800, url=www.test.com, number=200, YEAR=2016, 4=4, http_referrer=http://www.test.com/?cp=sfwefsc, MINUTE=00, SECOND=01, api=/api/index, MONTHDAY=06, access_time=06/Jun/2016:00:00:01 +0800}通过这种方式,开发者可以轻松地从日志中提取所需的信息,并进行后续的数据分析和处理。
虽然Java Grok提供了丰富的内置模式,但在某些情况下,开发者可能需要定义自己的解析规则来满足特定的日志格式需求。Java Grok支持自定义模式的使用,使得开发者可以编写自己的正则表达式来解析日志。
在自定义模式时,开发者可以通过Grok API提供的方法,将新的模式注册到GrokCompiler中,然后在解析日志时使用这些自定义模式。
GrokCompiler grokCompiler = GrokCompiler.newInstance();
grokCompiler.registerDefaultPatterns();
// 自定义模式
String customPattern = "%{TIMESTAMP_ISO8601:timestamp1}%{SPACE}%{WORD:location}.%{WORD:level}%{SPACE}%{IP:ip}%{SPACE}%{MONTH:month}";
Grok grok = grokCompiler.compile(customPattern);通过这种方式,开发者可以灵活地应对各种复杂的日志格式,满足不同场景下的日志解析需求。
在处理大规模日志数据时,Java Grok的性能表现至关重要。为了提高Grok API的解析效率,开发者可以采取以下几种优化技巧:
通过这些优化技巧,开发者可以显著提高Java Grok的解析性能,满足高效日志处理的需求。
Java Grok在多个领域和场景中得到了广泛应用,以下是一些常见的应用场景:
在系统监控和调试中,日志是获取系统运行状态和故障信息的重要来源。通过Java调用Grok API,开发者可以实时解析和分析系统日志,从而及时发现和解决系统问题。
在大数据分析和挖掘中,日志数据是一种重要的数据来源。通过Java Grok,开发者可以从海量的日志数据中提取关键信息,并进行数据分析和挖掘,从而发现潜在的业务价值。
在安全审计和合规性检查中,日志数据是进行安全事件分析和合规性验证的重要依据。通过Java Grok,开发者可以自动化解析和分析安全日志,提高审计和合规检查的效率和准确性。
问:Java Grok支持哪些日志格式?
问:如何提高Java Grok的解析性能?
问:Java Grok可以解析自定义的日志格式吗?
问:Java Grok是否支持多线程解析?
问:如何在Maven项目中集成Java Grok?





