Java 调用 Deep Voice API 完整指南
文章目录
深入了解 Java 与 Deep Voice API 的整合
Java 作为一种强大的编程语言,广泛应用于企业开发中,而 Deep Voice API 是一个高效的语音处理工具,支持语音识别、语音合成等功能。将 Java 与 Deep Voice API 整合,可以大幅提升应用的智能化程度,尤其是在语音交互和自然语言处理领域。
在本文中,我们将详细讲解如何使用 Java 调用 Deep Voice API,包括 API 的配置、代码实现、以及本地模型部署。无论是基于 DeepSeek 开放平台的 API 调用,还是本地化私有部署 DeepSeek R1 模型,都将一一解读。
使用 Java 调用 Deep Voice API 的基础设置
安装 Deep Voice Java 绑定
Deep Voice 提供了 Java 绑定,支持开发者在 Java 项目中轻松集成语音处理功能。以下是安装步骤:
- 下载 Deep Voice Java 绑定:访问 Deep Voice 官方网站 下载必要的绑定文件。
- 配置 Java 项目:通过 Maven 或 Gradle 添加依赖。
- 引入绑定类:在代码中导入
org.mozilla.deepspeech.libdeepspeech.DeepSpeechModel类。 - 加载模型:使用
loadModel方法加载 Deep Voice 模型文件。 - 释放资源:调用
freeModel方法清理模型资源。
以下是一个简单的代码示例:
import org.mozilla.deepspeech.libdeepspeech.DeepSpeechModel;
public class DeepVoiceExample {
public static void main(String[] args) {
DeepSpeechModel model = new DeepSpeechModel("model_path");
String result = model.recognize("audio_file_path");
System.out.println("识别结果: " + result);
model.freeModel();
}
}配置环境
确保你的开发环境满足以下要求:
- JDK 版本:建议使用 JDK 17 或以上。
- 系统依赖:安装必要的系统库,如
libdeepspeech.so。 - 模型文件:下载 Deep Voice 提供的预训练模型,确保与代码路径一致。
以下图片展示了配置完成后的项目结构:
基于 DeepSeek 开放平台的 API 调用
DeepSeek 提供了强大的开放平台,开发者可以通过 API 进行语音处理。以下是基于 DeepSeek 平台的整合步骤。
注册 API Key 并配置
- 访问 DeepSeek 开放平台。
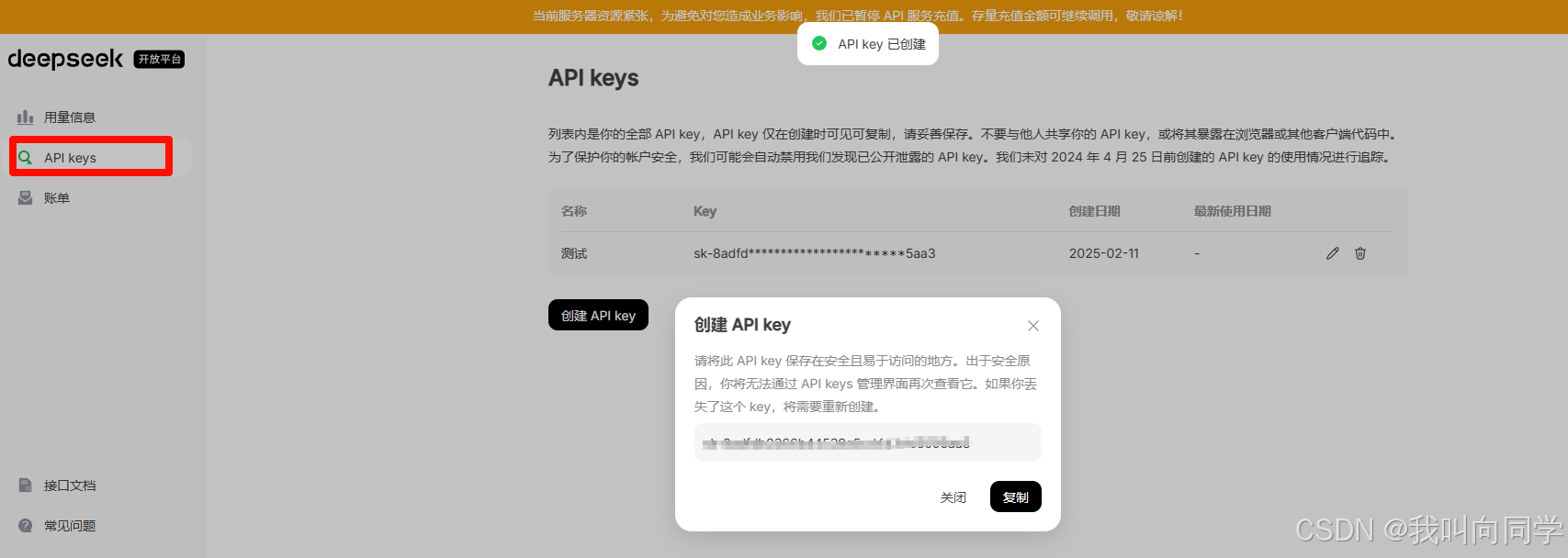
- 注册账号并创建 API Key,确保妥善保存。
以下是示例图片展示了 API Key 的生成过程:
Spring Boot 项目依赖配置
在 Spring Boot 项目中,通过 Maven 引入 spring-ai-openai-spring-boot-starter 依赖:
org.springframework.ai
spring-ai-openai-spring-boot-starter
1.0.0-M5
修改配置文件,添加 API Key 和模型信息:
spring:
ai:
openai:
base-url: https://api.deepseek.com/v1
api-key: sk-your-deepseek-key-here
chat.options:
model: deepseek-chat实现代码逻辑
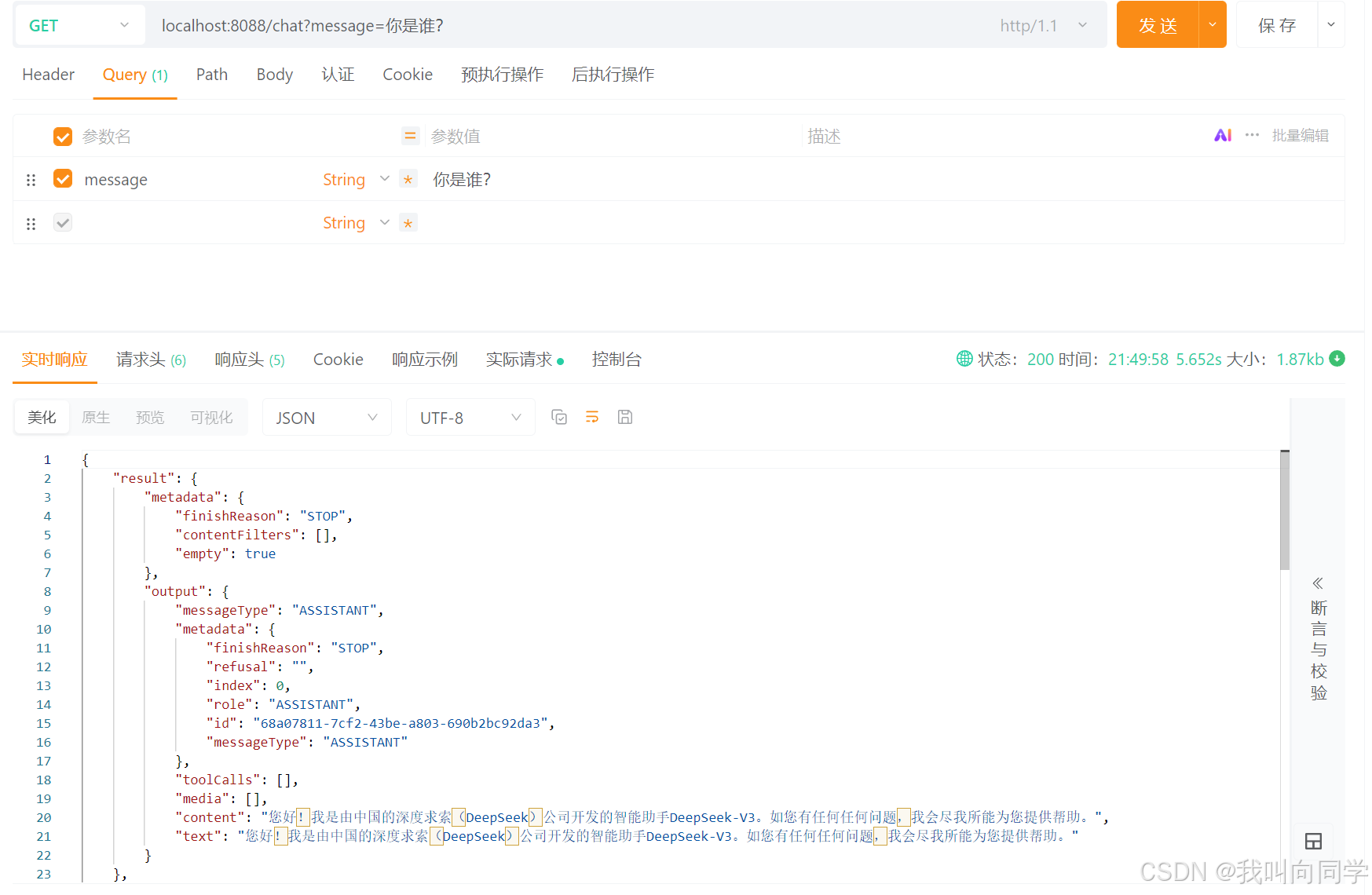
以下代码展示了如何通过 API 调用 DeepSeek 模型实现语音识别:
@RestController
public class ChatController {
@Resource
private OpenAiChatModel chatModel;
@GetMapping("/chat")
public ChatResponse chat(String message) {
// 调用 DeepSeek 模型
Prompt prompt = new Prompt(new UserMessage(message));
return chatModel.call(prompt);
}
}API 调用成功后,返回的结果可以直接用于后续处理。
本地化私有部署 DeepSeek R1 模型
对于需要高性能和数据隐私的场景,可以选择本地部署 DeepSeek 模型。
安装 Ollama 工具
- 下载并安装 Ollama。
- 使用以下命令拉取 DeepSeek R1 模型:
ollama pull deepseek-r1:8b
ollama list deepseek以下是 Ollama 安装成功后的界面截图:
修改 Spring Boot 项目配置
添加 Ollama Starter 依赖:
org.springframework.ai
spring-ai-ollama-spring-boot-starter
0.8.1
配置文件中指定本地模型:
spring:
ai:
ollama:
base-url: http://localhost:11434
chat:
model: deepseek-r1:8b本地调用代码
以下代码展示了如何调用本地模型实现语音处理功能:
@RestController
@RequestMapping("/ai")
public class LocalChatController {
@Resource
private ChatClient chatClient;
@GetMapping("/chat")
public ResponseEntity<Flux> chat(@RequestParam("message") String message) {
Flux response = chatClient.prompt(message).stream().content();
return ResponseEntity.ok(response);
}
}通过本地模型,可以实现快速响应,同时保障数据安全。
高级功能与优化
多线程处理语音任务
为了提升性能,可以通过多线程技术并发处理多个语音任务。例如:
ExecutorService executor = Executors.newFixedThreadPool(5);
List<Future> results = new ArrayList();
for (String audio : audioFiles) {
results.add(executor.submit(() -> model.recognize(audio)));
}模型优化与定制化
可通过微调模型或蒸馏技术,优化 DeepSeek 模型以适应特定场景需求。
常见问题解答 (FAQ)
FAQ
-
问:如何获取 DeepSeek 的免费试用 API Key?
- 答:访问 DeepSeek 开放平台,注册即可获取免费 API Key。
-
问:本地部署模型的硬件要求是什么?
- 答:建议使用至少 16GB 内存和 4 核 CPU 的计算机,GPU 支持可显著提升性能。
-
问:如何处理识别结果的错误率?
- 答:可以尝试调整输入音频的质量或使用更高精度的模型版本。
-
问:Spring Boot 项目中如何调试 API 调用?
- 答:建议使用 Postman 或 Insomnia 工具测试 API 调用,并检查日志输出。
-
问:是否支持其他语言的语音识别?
- 答:Deep Voice 支持多种语言的训练模型,请根据需求选择合适的模型。
通过本文的详细指导,相信您已经掌握了如何使用 Java 调用 Deep Voice API,并结合实际场景进行开发和优化。