

如何调用 Minimax 的 API

HunyuanVideo 是一款开源的视频生成基础模型,其生成性能可与业内顶尖的闭源模型媲美。拥有超过 130 亿个参数,是当前规模最大的开源视频生成模型。该模型集成了数据精选、高级架构设计、渐进式模型扩展与训练,以及高效的基础设施,以支持大规模模型训练与推理。HunyuanVideo 在视频生成的视觉质量、运动动态、视频-文本对齐和语义场景切换四个关键方面表现出色。专业评测显示,HunyuanVideo 的表现优于 Runway Gen-3、Luma 1.6 以及其他三款顶尖的中文视频生成模型。
通过开源模型代码和应用,HunyuanVideo 致力于缩小开源与闭源社区之间的性能差距,推动更具活力和创新的视频生成生态体系。
HunyuanVideo 采用了图像-视频联合训练策略,将训练数据精细划分为不同类别,以满足各自的训练需求。视频数据被划分为五个不同组别,图像数据则被划分为两个组别,以确保在训练过程中充分发挥数据的特性和优势。本节将重点介绍视频数据的精细化筛选和准备过程。
原始数据池涵盖多个领域,包括人物、动物、植物、风景、交通工具、物体、建筑及动画等多种类别的视频。所有视频采集均设定了基本的阈值要求,如视频的最小时长等。此外,还针对部分数据设定了更高的筛选标准,包括空间分辨率、特定宽高比、构图、色彩和曝光等专业要求,确保数据在技术质量和美学品质上均达标。
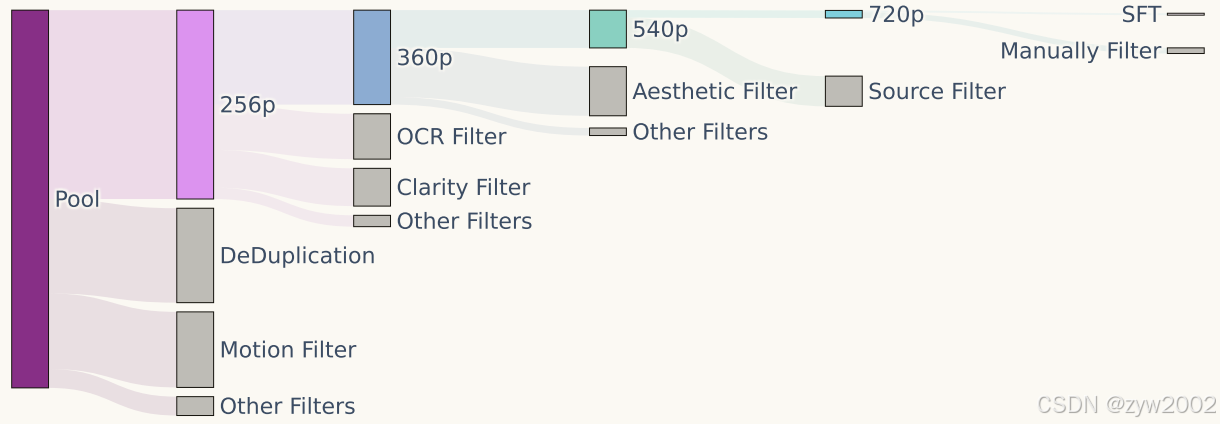
HunyuanVideo 采用了一系列预处理技术来提升数据质量。首先,使用 PySceneDetect 将视频分割为单镜头片段。然后,利用 OpenCV 的拉普拉斯算子提取清晰帧作为视频片段的起始帧。接着,通过内部 VideoCLIP 模型计算视频嵌入向量,用于去重和聚类。
构建了一个分层数据筛选管道,通过多维度的筛选技术来提升数据质量,包括使用 Dover 评估视频片段的美学和技术质量,剔除模糊视频,预测视频的运动速度,获取场景边界信息,移除带有过多文本或字幕的片段,并去除水印、边框和标志等遮挡或敏感信息。
通过小规模模型实验验证筛选器的有效性,并据此逐步优化数据筛选管道。最终,为不同训练阶段构建了五个视频训练数据集,视频分辨率逐步提升,并根据训练阶段动态调整筛选阈值。
为提升生成模型的提示响应能力和输出质量,开发了内部视觉语言模型(VLM),为所有图像和视频生成结构化标注。这些标注采用 JSON 格式,从多维度提供全面的描述信息,包括短描述、密集描述、背景、风格、镜头类型、光照和氛围等。
训练了一个相机运动分类器,能够预测 14 种相机运动类型,包括变焦、平移、俯仰、绕拍、静态镜头和手持镜头。高置信度的相机运动预测结果被集成到 JSON 格式的结构化标注中,从而赋予生成模型对相机运动的控制能力。
训练了一个 3DVAE 模型,将像素空间的视频和图像压缩到紧凑的潜在空间。为了同时处理视频和图像,采用的是 CausalConv3D。对于一个形状为 (T+1) × 3 × H × W 的视频,3DVAE 将其压缩为潜在特征。这种压缩方法显著减少了后续模型所需的令牌数量,使其能够以原始分辨率和帧率训练视频,同时保持较高的效率和质量。
3DVAE 训练策略
在训练过程中,我们采用了课程学习策略,逐步从低分辨率短视频训练到高分辨率长视频。为了改善高运动视频的重建效果,我们在采样帧时随机选择了 1 至 8 范围内的采样间隔,确保从视频剪辑中均匀地抽取帧。
推理阶段
在单块GPU上编码和解码高分辨率长视频可能会导致显存不足 (OOM) 错误。为了解决这一问题,采用了一种时空切片策略,将输入视频在空间和时间维度上划分为重叠的切片。每个切片单独编码/解码,最终再将输出拼接在一起。对于重叠区域,我们使用线性组合进行平滑融合。这一切片策略使我们能够在单块GPU上处理任意分辨率和时长的视频。
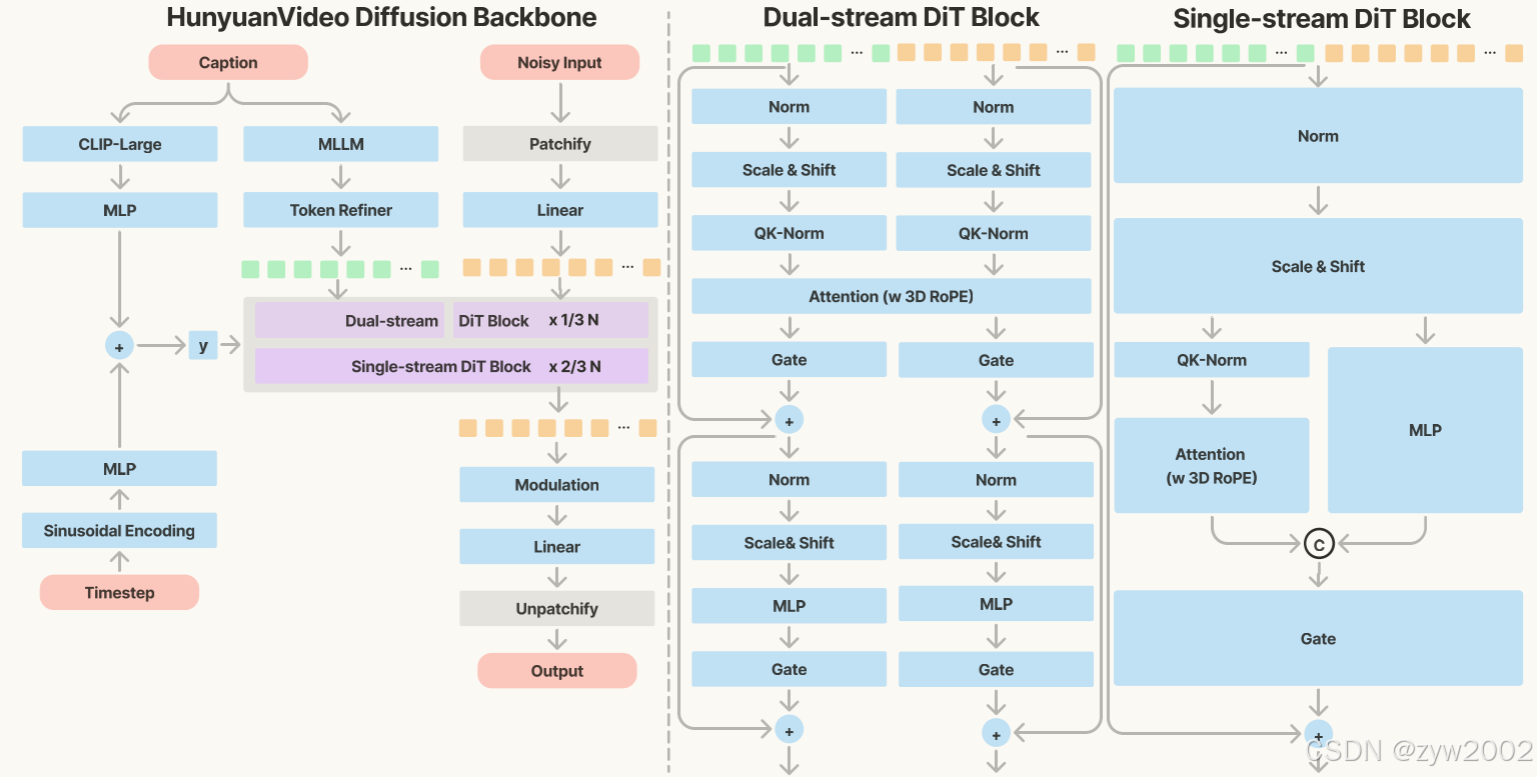
HunyuanVideo 中的 Transformer 设计,采用了统一的全注意力机制,并基于以下三大理由:
模型的具体结构如下图所示。
本研究使用 Flow Matching 框架来训练图像和视频生成模型。Flow Matching 的核心思想是将复杂的概率分布通过一系列变量变换转换为简单的概率分布,通过逆变换从简单分布生成新的数据样本。
训练过程
输入表示使用训练集中图像或视频的潜在表示。通过线性插值方法,构建训练样本。目标是预测速度场,指导样本向样本移动。优化参数通过最小化预测速度和真实速度的均方误差 (MSE) 来优化模型参数。
推理过程
初始噪声样本从高斯分布中抽取。使用一阶 Euler 常微分方程 (ODE) 求解器,结合模型预测的估计值,逐步计算生成样本。
背景和动机
早期实验表明,预训练模型显著加速了视频训练的收敛速度,并提升了视频生成性能。为此,提出了一种两阶段的渐进式图像预训练策略,用于视频训练的热启动。
阶段 1:256px 图像训练
目标是模型首先在低分辨率(256px)图像上进行预训练。策略包括多尺度训练,在 256px 图像上启用多长宽比训练,帮助模型学习生成宽广长宽比范围内的图像。
阶段 2:混合尺度训练
目标是增强模型在高分辨率(如 512px)上的能力。提出混合尺度训练方法,在每次训练的全局批次中,引入两个或多个尺度的多长宽比 buckets。
相比图像生成,视频生成在减少推理步骤的同时维持空间质量和时间质量更加具有挑战性。为了解决这一问题,我们重点研究如何减少视频生成所需的推理步骤数量。





