

如何调用 Minimax 的 API

Hunyuan Video开源版本是腾讯推出的一个突破性的视频生成模型,旨在为企业和个人开发者提供免费的高质量视频生成工具。该模型的参数量达到130亿,能够在真实与虚拟之间实现自由切换。Hunyuan Video通过其卓越的画质和流畅的动态表现,使得视频生成更加真实和生动。
Hunyuan Video的开源不仅体现了腾讯在技术上的开放态度,也为整个视频生成领域带来了新的可能性。通过提供多种视角的镜头切换和无缝的艺术镜头过渡,Hunyuan Video在视觉叙事方面达到了新的高度。此外,模型在语义遵从能力上表现优异,能够根据简单的指令实现复杂的多主体描绘。
Hunyuan Video以其超写实的画质著称,能够在视觉上轻松实现真实与虚拟风格的切换。该模型通过先进的图像处理技术,确保每一帧都能呈现出极高的细节和逼真度。无论是动态场景还是静态画面,Hunyuan Video都能保证图像的清晰和细腻。
这得益于模型在光影反射上的物理定律遵循,减少了观众的跳戏感。用户可以通过简单的提示词来生成高质量的视频内容,如“超大水管浪尖,冲浪者在浪尖起跳,完成空中转体”,模型将自动生成符合描述的逼真影像。

Hunyuan Video突破了传统动态图像的局限,能够完美展现每一个动作的流畅过程。它采用全注意力机制而非时空模块,使得视频生成更加流畅和自然。这种技术的应用使得每帧视频的衔接更加紧密,观众在观看时不会感到任何突兀或不连贯。
通过对视频生成中时空特征的统一处理,Hunyuan Video不仅提升了视频的流畅度,还可以实现复杂场景下的多视角镜头切换。例如,在拍摄一位中国美女在伦敦背景下穿着汉服的动态场景时,Hunyuan Video能够在不同视角间无缝切换,保持主体的一致性。

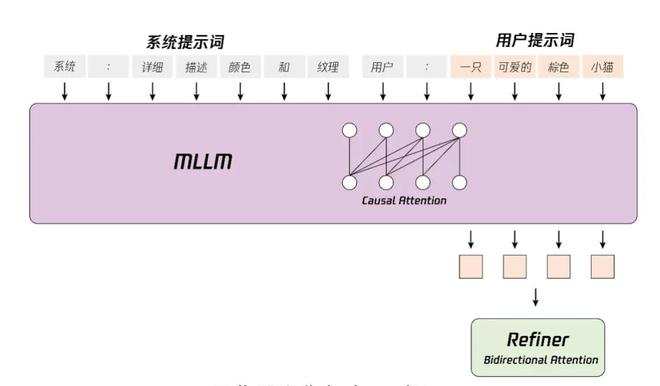
Hunyuan Video是业界首个以多模态大语言模型为文本编码器的视频生成模型,具备超高的语义理解能力。在处理多主体及属性绑定等生成领域的难点挑战时,Hunyuan Video表现出色。它能够通过简单的文本指令生成复杂的多主体场景,准确实现用户的创意。
该模型的语义遵从能力使得用户只需简单的指令即可实现多主体准确的描绘和流畅的创作。通过这种方式,Hunyuan Video不仅提升了创作的效率,还激发了无限的创意与灵感,充分展现AI超写实影像的独特魅力。

Hunyuan Video具备多视角镜头切换主体保持能力,能够实现艺术镜头的无缝衔接。通过这种原生镜头转换技术,Hunyuan Video打破了传统单一镜头生成形式,达到了导演级的无缝镜头切换效果。
在实际应用中,这种技术可以大大提高视频的观赏性和艺术性。例如,在拍摄一位60多岁、坐在巴黎咖啡馆沉思的男子时,Hunyuan Video可以自动切换到特写镜头,捕捉人物细微的表情变化,营造出浓厚的电影氛围。

Hunyuan Video开源版本采用了多种创新技术,加速了视频生成行业的发展步伐。通过新一代文本编码器提升语义遵循能力,自研3D视觉编码器支持图像视频混合训练,全注意力机制提升画面运镜能力。
此外,Hunyuan Video根据自研的图像视频Scaling Law设计和训练了最优配比模型。Scaling Law提供了指导如何扩展模型参数、训练数据和计算资源的经验公式,使得模型达到更好的性能。这不仅为开发者提供了强大的工具,也为整个行业的发展提供了新的思路与方向。
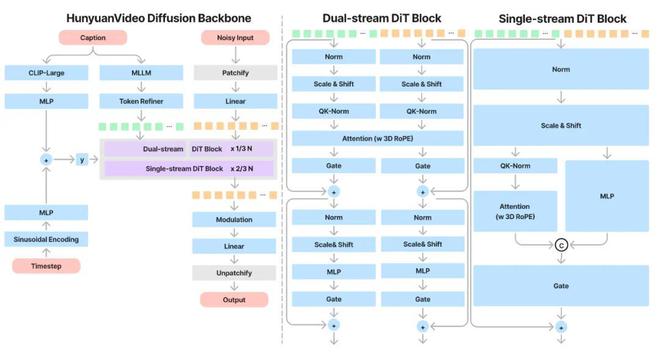
Hunyuan-Video是一个综合的视频训练系统,涵盖了从数据处理到模型部署的各个方面。其架构设计采用了先进的MLLM文本编码器,具备强大的语义跟随能力,能够轻松应对多个主体的描绘。
在数据处理方面,Hunyuan Video采用自动化数据过滤和人工过滤相结合的方式,从粗到细构建多个阶段的训练数据集。这种精细的数据处理架构确保了训练数据的高质量,为模型的性能提升奠定了基础。
问:Hunyuan Video开源版本有哪些应用场景?
问:如何申请使用Hunyuan Video的开源模型?
问:Hunyuan Video在语义理解上有何优势?
问:Hunyuan Video的开源对行业发展有何影响?
问:Hunyuan Video与其他视频生成模型相比有哪些优势?






