如何调用 Minimax 的 API

Hunyuan-Video 是腾讯推出的一款高质量中文通用视频生成模型。作为开源视频生成基座模型中的佼佼者,Hunyuan-Video 凭借其卓越的性能和开放的特性,迅速成为视频内容创作者、研究人员和开发者的首选工具。它支持中文输入提示(Prompt),采用图像-视频联合训练策略,并通过一系列精细的数据过滤技术,确保生成的视频在技术质量和审美吸引力上都能满足用户的高标准。这种开源模式不仅缩小了闭源和开源视频基础模型之间的差距,还加速了社区对视频生成技术的探索。

官方网站: https://aivideo.hunyuan.tencent.com/
Hunyuan-Video 生成的视频内容多样且细腻,涵盖了从人物肖像到复杂场景的广泛应用。以下是一些模型生成效果的例子:




Hunyuan-Video 的论文对比了全球领先的视频生成模型,如 Gen-3 和 Luma 1.6,以及中国市场上表现最好的商业模型。结果显示,Hunyuan-Video 在运动动力学等方面表现出色,达到了最高的整体满意度。这一高性能的实现得益于其独特的数据处理和模型训练策略。
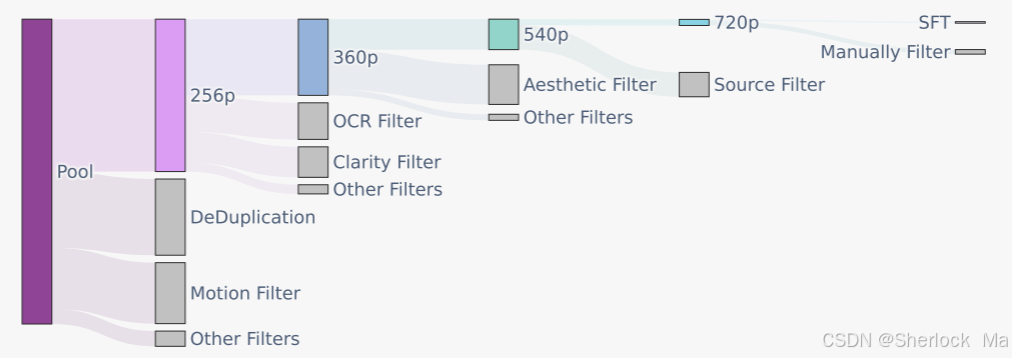
Hunyuan-Video 使用图像-视频联合训练策略,将视频素材精心分为五个不同的组,而图像则分为两组,依据各自的训练需求进行定制。这种分类确保了模型能够在多个维度上进行高效学习。
使用 PySceneDetect 将原始视频拆分为单镜头视频剪辑,通过 OpenCV 的拉普拉斯算子识别清晰的起始帧。利用内部 VideoCLIP 模型计算视频剪辑的 Embedding,通过余弦距离进行重复数据删除,并应用 k-means 算法获取概念质心,用于排序和平衡。通过这些技术手段,模型能够在美学、运动和概念范围内不断优化。
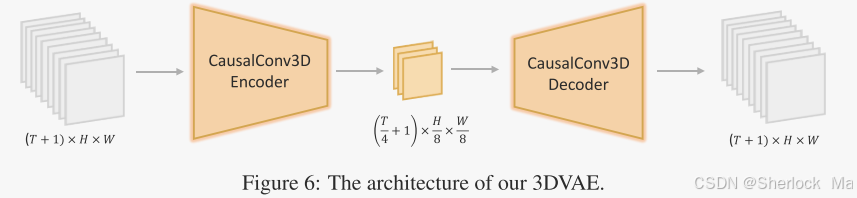
Hunyuan-Video 的 3D-VAE 通过 CausalConv3D 将视频和图像压缩到紧凑的潜在空间中,显著提高了视频生成的效率和质量。在训练过程中,使用从低分辨率短视频逐渐变化到高分辨率长视频的策略,确保了高运动视频的重建质量。
Hunyuan-Video 采用了统一的全注意力机制 Transformer 设计,支持图像和视频的统一生成。文本编码器通过在潜在空间中提供指导信息,增强了文本与视频生成之间的联系。使用大语言模型作为文本特征提取器,提升了文本信息的表达能力。
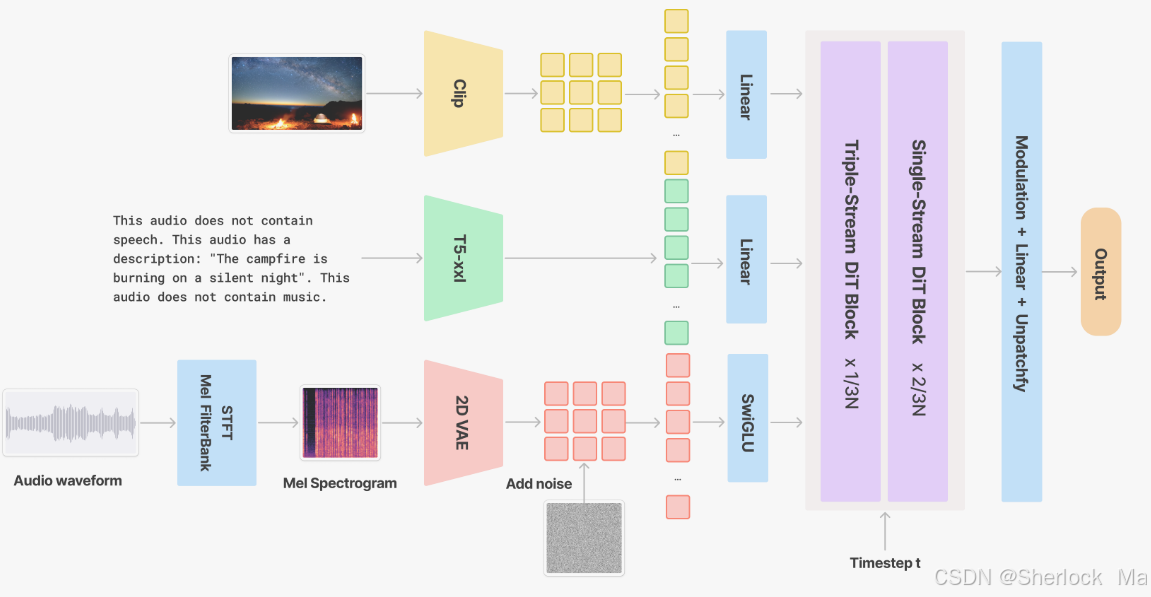
视频到音频模块通过添加同步的声音效果和背景音乐,提升了视频内容的表现力。V2A 模型通过梅尔频谱图和 VAE 编码器,在潜在空间中重建高保真的音频信号。
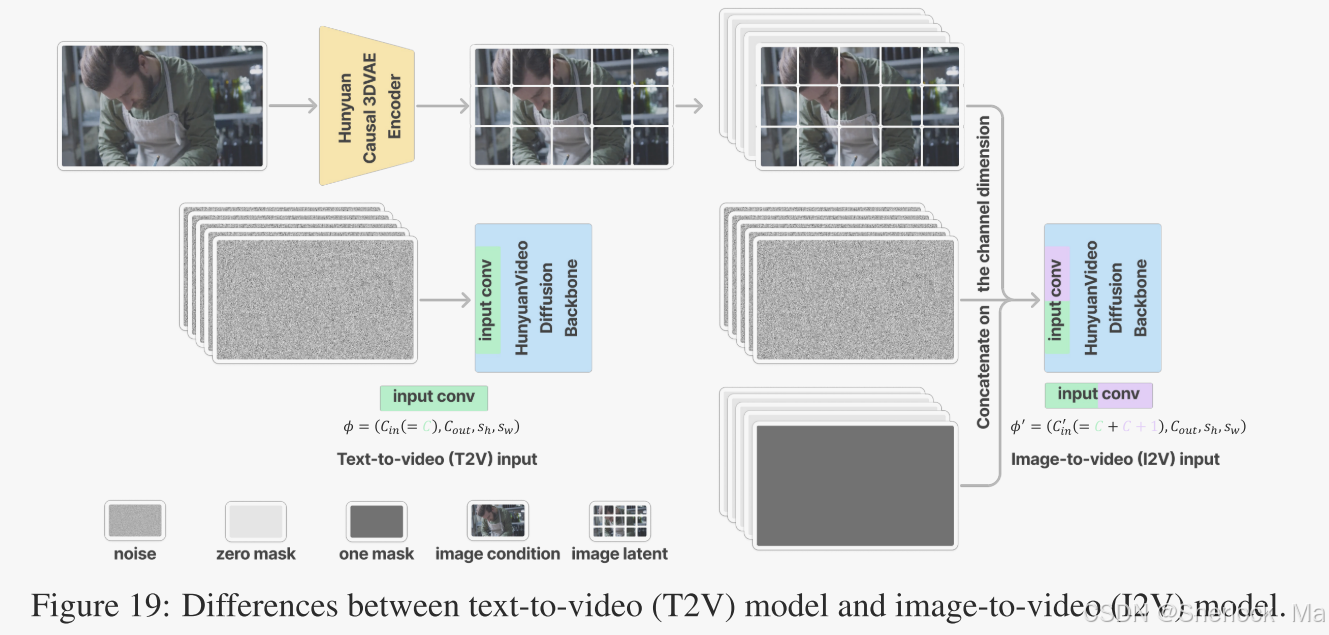
图像到视频(I2V)功能允许用户通过输入图像和字幕,生成与之匹配的视频内容。这一功能通过引入图像作为视频的第一帧并结合文本条件,确保生成的视频与原始输入的主题紧密贴合。
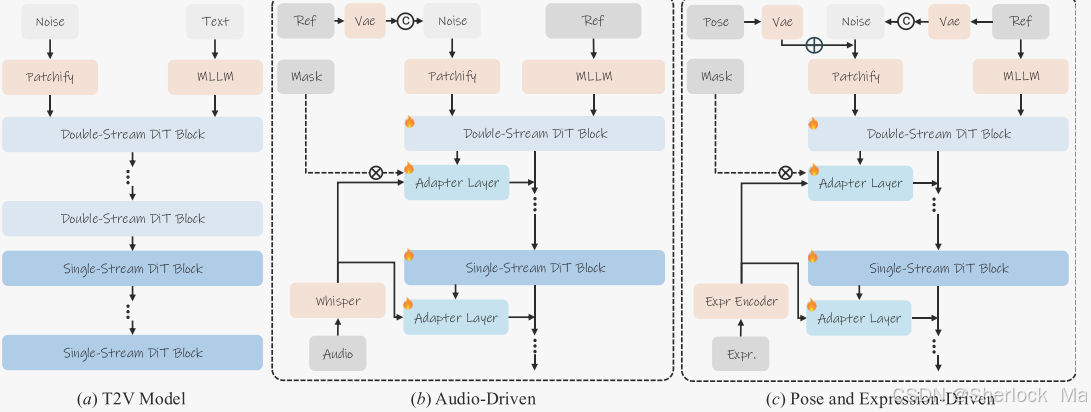
通过结合音频信号、姿势模板和表情模板,Hunyuan-Video 能够实现丰富的化身动画控制,提升角色的表现力和真实感。通过对参考图像的编码,以及使用多种适配器,模型能够实现对复杂动画的高精度控制。