

如何调用 Minimax 的 API

Hunyuan Video 是腾讯推出的高质量中文通用视频生成模型,以其卓越的性能和开源特性,成为目前开源视频生成基座模型中的佼佼者。本文将详细探讨 Hunyuan Video 的各种应用场景、代码实现细节、优化策略及其在不同领域的实践应用。
Hunyuan Video 是专为视频内容创作者、研究人员和开发人员设计的工具,支持中文输入提示(Prompt),采用图像-视频联合训练策略,并通过一系列精细的数据过滤技术,确保了视频的技术质量和审美吸引力。其开源性质为社区提供了强大的支持,有助于推动 AI 视频技术的发展。

开源视频生成模型为公众提供了创新的机会,尤其是对于那些想要深入了解视频生成技术或进行二次开发的研究人员和开发者。Hunyuan Video 的开源不仅缩小了闭源和开源模型之间的差距,还加速了社区探索的步伐。
与其他视频生成模型相比,Hunyuan Video 在运动动力学方面表现尤为出色。通过与全球领先的视频生成模型,如 Gen-3 和 Luma 1.6 的比较,该模型在整体满意度方面达到最高,尤其是在运动表现和细节捕捉上。
通过 Hunyuan Video,可以生成各种风格的视频场景,从真实电影镜头到动画风格的画面,满足多样化的创作需求。


Hunyuan Video 使用图像-视频联合训练策略,数据采集包括人物、动物、景观等多种素材,经过严格的空间质量和美学标准筛选,确保训练数据的高质量。
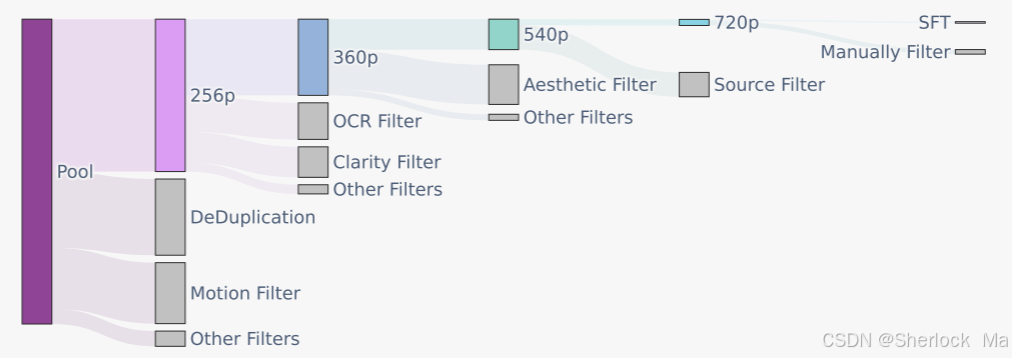
Hunyuan Video 使用 3D-VAE 来压缩视频和图像,支持视频和图像的同时处理。采用从低分辨率到高分辨率的训练策略,结合 L1 重建损失、感知损失和 GAN 对抗损失,提升视频重建质量。
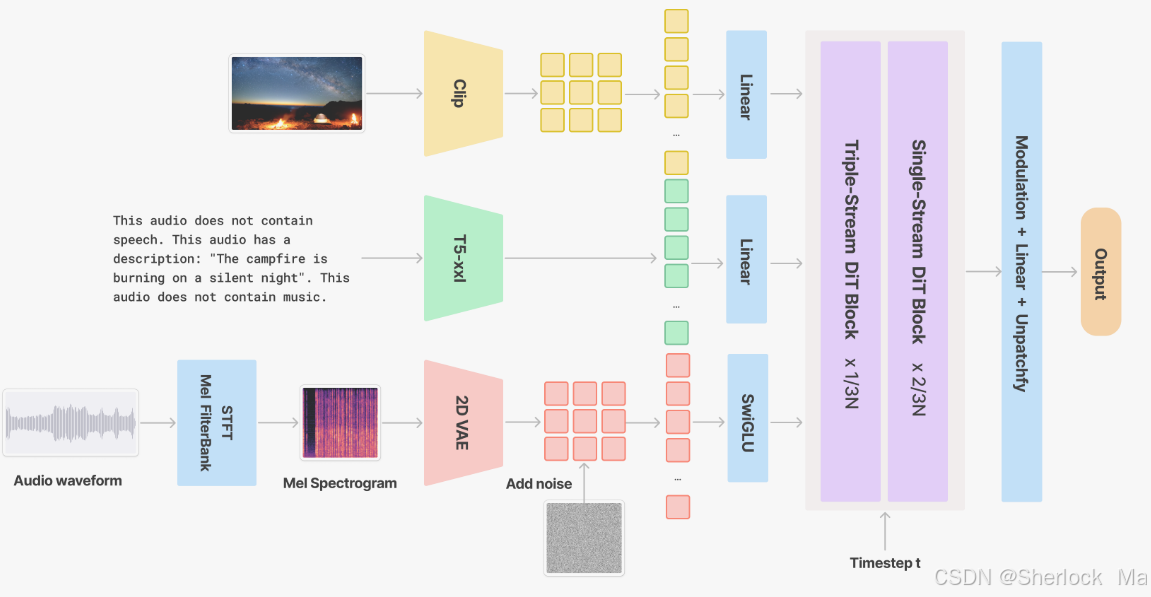
V2A 模块通过整合同步声音效果和背景音乐,增强视频内容的表现力。采用变分自动编码器(VAE)进行音频波形的潜在空间编码,结合视觉与文本特征提取,确保多模态信息的融合与对齐。
I2V 任务是指将图像作为视频的第一帧,根据字幕生成匹配的视频。通过人脸和身体检测器过滤训练数据,采用渐进式微调策略,增强模型在肖像领域的表现力。

通过插入参考图像的潜像,Hunyuan Video 实现可控的化身动画。此功能允许使用显式驱动信号(如语音、表情、姿势模板)以及文本提示进行控制。

下载源码后,按照以下步骤配置 conda 环境,确保 flash attention 与 torch 版本匹配。
conda env create -f environment.yml
conda activate HunyuanVideo
python -m pip install -r requirements.txt
python -m pip install git+https://github.com/Dao-AILab/flash-attention.git@v2.5.9.post1官方提供的 Docker 镜像可以简化环境配置,适合需要快速部署的用户。
wget https://aivideo.hunyuan.tencent.com/download/HunyuanVideo/hunyuan_video_cu12.tar
docker load -i hunyuan_video.tar
docker image ls
docker run -itd --gpus all --init --net=host --uts=host --ipc=host --name hunyuanvideo --security-opt=seccomp=unconfined --ulimit=stack=67108864 --ulimit=memlock=-1 --privileged docker_image_tag使用 sample_video.py 脚本生成视频样本,支持多种参数配置。
cd HunyuanVideo
python3 sample_video.py
--video-size 720 1280
--video-length 129
--infer-steps 50
--prompt "A cat walks on the grass, realistic style."
--flow-reverse
--use-cpu-offload
--save-path ./results是的,Hunyuan Video 可以通过其先进的模型架构和数据过滤技术生成高动态范围的视频,确保在不同光照条件下的视觉质量。
可以使用官方提供的 Docker 镜像,并使用 –use-cpu-offload 参数减少对 GPU 的依赖,从而在低性能计算机上运行。
是的,Hunyuan Video 的提示重写模块支持多语言输入,并将其转换为模型偏好的标准化提示。
由于 Hunyuan Video 是开源项目,用户可以根据相关开源协议进行商业用途,但需遵循协议中的限制和条款。
可以通过调整生成参数(如视频长度、分辨率、采样步数等)以及使用高质量的训练数据来优化生成的视频质量。





