

豆包 Doubao Image API 价格全面解析

HunyuanVideo 是腾讯推出的一款开源视频生成大模型,凭借其出色的性能与闭源模型相媲美甚至更优。该模型采用了全面的训练框架,集成了数据整理、图像-视频联合模型训练和高效的基础设施,支持大规模模型训练和推理。HunyuanVideo 成功训练了一个拥有超过 130 亿参数的视频生成模型,是当前最大的开源视频生成模型之一。HunyuanVideo GitHub 官网

Open-Sora 是由北京大学和兔展科研团队推出的开源项目,旨在通过开源原则推动视频生成技术的发展。它基于 Diffusion Transformer(DiT)架构,使用华为开源的 PixArt-α 高质量文本到图像生成模型,并通过添加时间注意力层扩展为视频生成。Open-Sora 提供了一个简化且用户友好的平台,致力于高效制作高质量视频。Open-Sora GitHub 官网

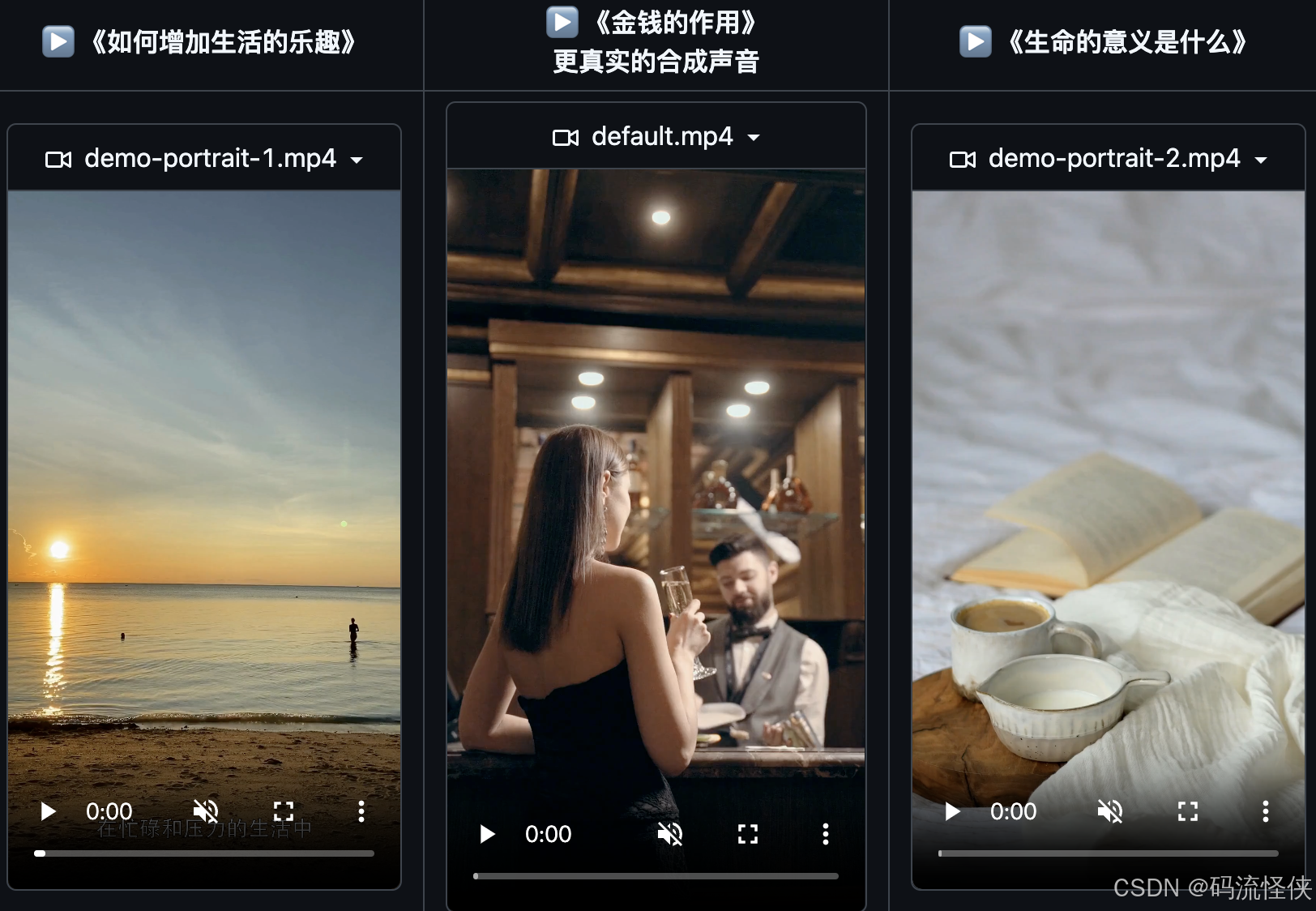
MoneyPrinterTurbo 是一个 Python 开发的开源工具,旨在通过自动化生成短视频加速内容生产。结合了图像处理、文本转语音 (TTS)、视频编辑等功能,支持 OpenAI、moonshot、Azure、gpt4free、one-api 等多种 AI 模型接入,满足不同用户的需求。用户可以快速制作符合社交媒体平台要求的短视频。MoneyPrinterTurbo GitHub
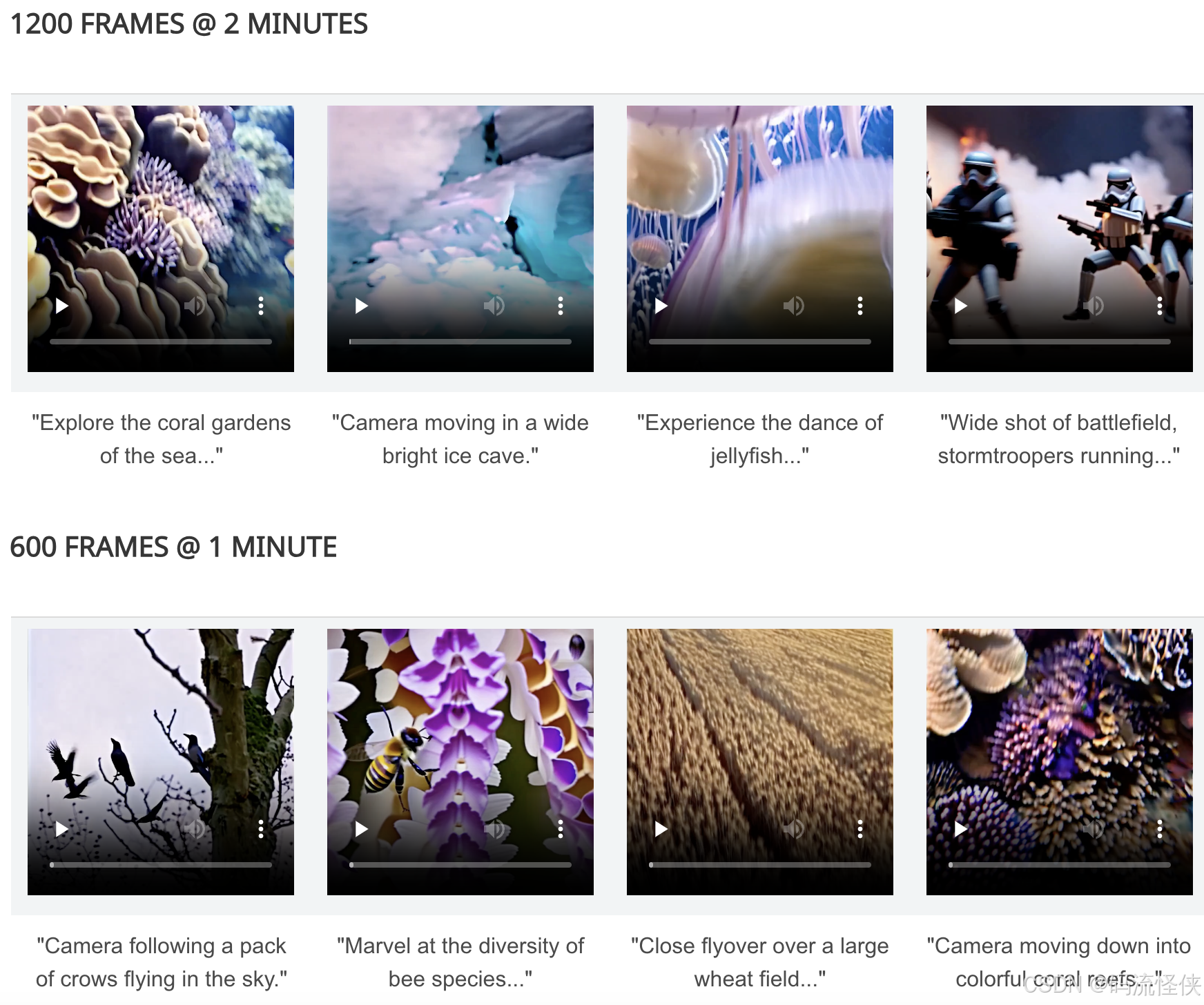
StreamingT2V 是由 PicsArt AI 研究团队推出的 AI 视频生成模型,能够从文本生成长达 1200 帧、时长为 2 分钟的长视频。通过引入条件注意模块(CAM)、外观保持模块(APM)以及随机混合方法,StreamingT2V 实现了长视频的流畅生成,确保时间上的连贯性和与文本描述的紧密对齐。StreamingT2V GitHub 官网
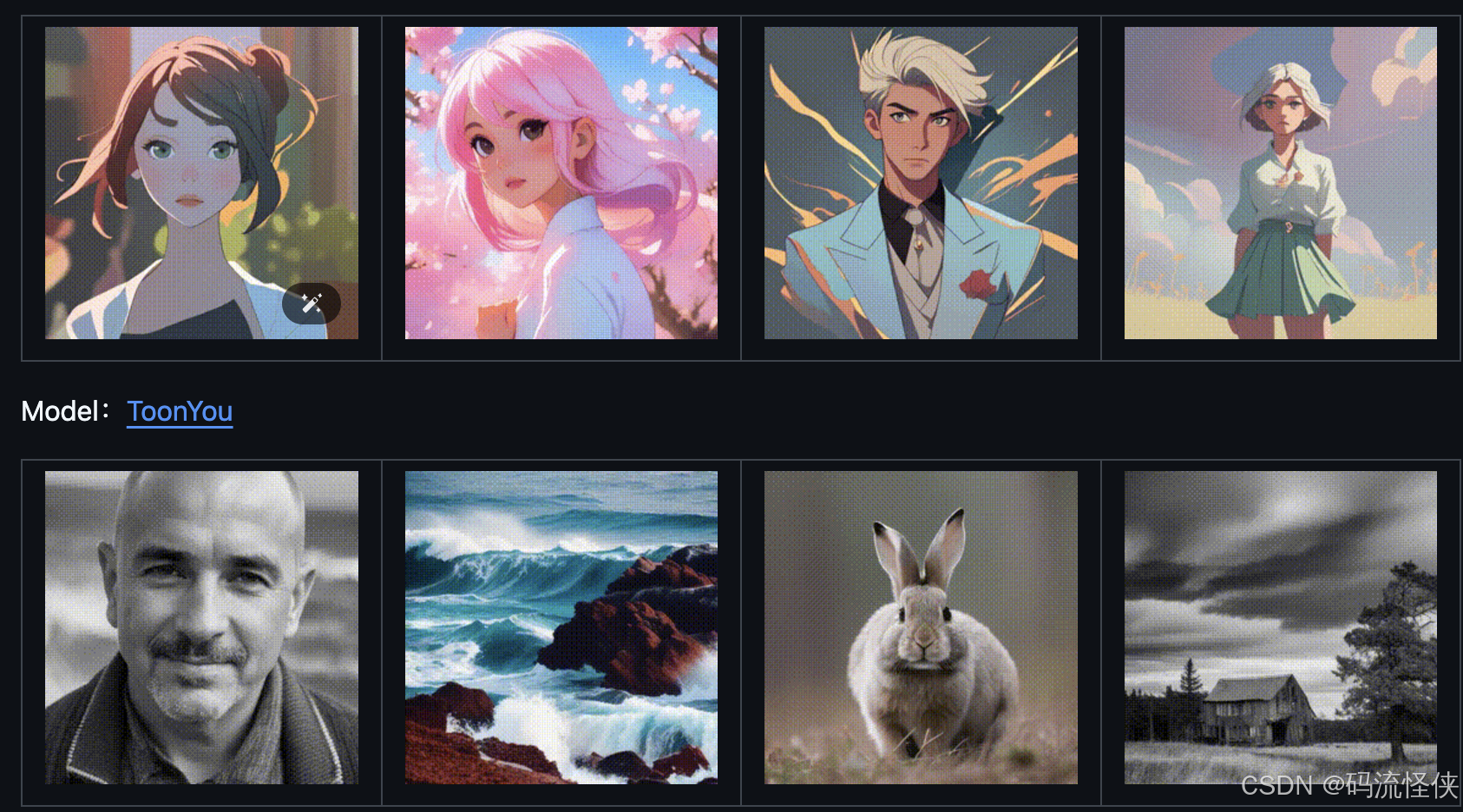
AnimateDiff 是一个强大的 AI 视频生成框架,能够将个性化的文本到图像(T2I)模型扩展为动画生成器。通过从大规模视频数据集中学习到的运动先验知识,作为 Stable Diffusion 文生图模型的插件,允许用户将静态图像转换为动态动画。AnimateDiff GitHub 官网
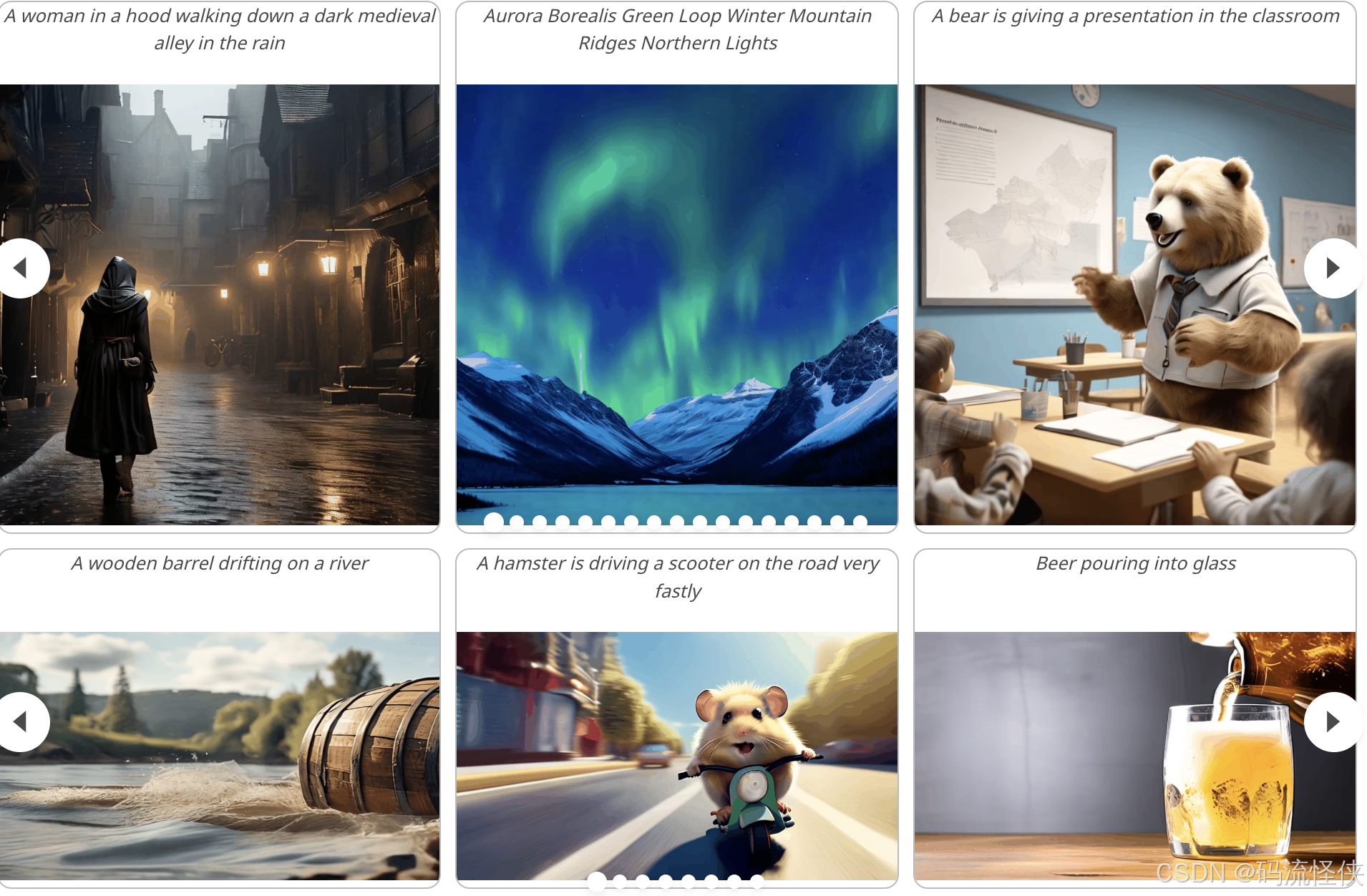
StoryDiffusion 是由南开大学和字节跳动合作推出的开源 AI 故事创作项目,专注于从文本描述生成具有一致性的图像和视频序列。通过结合一致性自注意力和语义运动预测器,为视觉故事生成领域提供了新的探索方向。StoryDiffusion GitHub 官网

Video-LaVIT 是一种创新的多模态预训练方法,旨在赋予大型语言模型(LLMs)理解和生成视频内容的能力。通过有效地将视频分解为关键帧和时间运动,解决了大规模预训练中视频的时空动态建模的挑战。Video-LaVIT GitHub 官网
Hunyuan Image 作为私人 AI 助手在图像生成领域的应用潜力巨大。随着技术的不断发展,它将为用户提供更为个性化和高效的图像生成解决方案。未来,Hunyuan Image 可以在更多领域发挥作用,如娱乐产业、教育领域,以及各种需要图像生成的应用场景。通过不断优化模型架构和融合多模态技术,Hunyuan Image 将继续引领图像生成技术的发展潮流。
问:Hunyuan Image 如何提升图像生成效率?
问:是否可以将 Hunyuan Image 应用于视频生成?
问:Hunyuan Image 对于教育领域有何应用?
问:如何保障 Hunyuan Image 的生成内容质量?
问:Hunyuan Image 的未来发展方向是什么?





