

PixVerse V3 API Key 获取:全面指南与实践

华为PixArt-α是一种创新的文本到图像(T2I)生成模型,通过使用Transformer架构实现了高效的图像合成。它是由华为诺亚方舟实验室、大连理工大学和香港大学的研究团队共同开发的,旨在以低成本实现高质量图像生成。相比传统模型,PixArt-α不仅降低了训练成本,还减少了二氧化碳排放,成为AIGC社区和初创公司构建T2I模型的新选择。
PixArt-α的训练策略分为三个阶段:
这种分解策略使PixArt-α在训练效率和图像合成质量上都取得了显著优势。
PixArt-α采用了Diffusion Transformer(DiT)架构,创新性地引入了跨注意力模块和自适应标准化层(adaLN-single)。跨注意力层的引入使得文本特征能够灵活注入,而adaLN-single则减少了模型参数量。
class CrossAttentionLayer(nn.Module):
def __init__(self, dim, num_heads):
super(CrossAttentionLayer, self).__init__()
self.self_attention = nn.MultiheadAttention(dim, num_heads)
self.cross_attention = nn.MultiheadAttention(dim, num_heads)
self.layer_norm = nn.LayerNorm(dim)
def forward(self, x, text_features):
x = self.layer_norm(x)
x, _ = self.cross_attention(x, text_features, text_features)
return x为了提高文本图像对的对齐效率,PixArt-α引入了一种自动标注流程,生成高信息密度的图像标题。研究团队对LAION和SAM数据集进行了详细的名词统计,确保模型在训练中能够掌握更多概念。
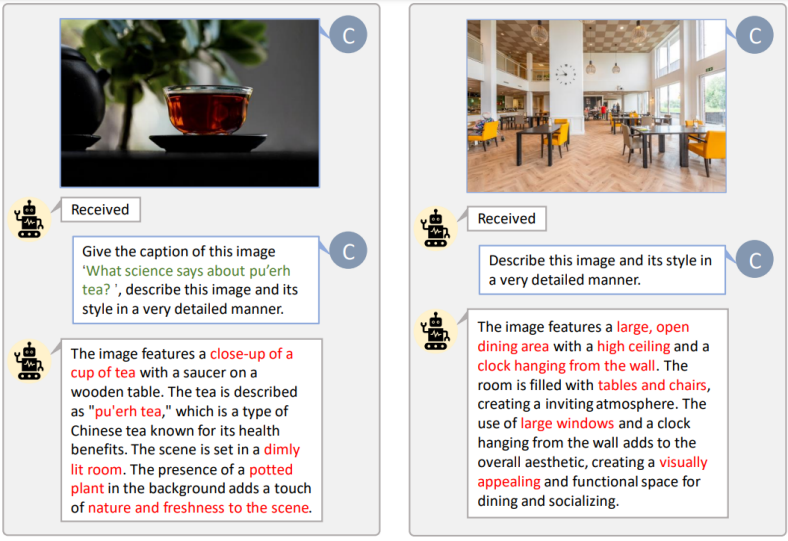
PixArt-α支持与ControlNet和DreamBooth结合使用。ControlNet通过生成HED边缘图像作为控制信号,增强了图形生成的细节表现力。DreamBooth则通过少量图像和文本提示,生成高保真度的图像,展现出与环境的自然交互。

在User study、T2ICompBench和MSCOCO Zero-shot FID等指标下,PixArt-α展示了其卓越的图像生成能力。在与Midjourney等其他模型的对比中,PixArt-α在质量和对齐度方面都表现优异。
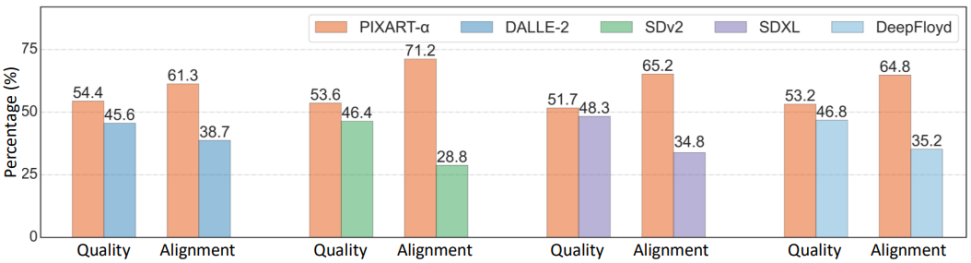
PixArt-α通过创新的训练策略、架构设计和数据构建,实现了低成本高质量的文本到图像生成。未来,研究团队希望PixArt-α能够为AIGC社区带来更多创新,推动高效T2I模型的发展。
问:PixArt-α的主要优势是什么?
问:PixArt-α如何实现高质量的图像生成?
问:PixArt-α支持哪些应用场景?
问:如何开始使用PixArt-α?
问:PixArt-α与其他T2I模型相比有哪些不同?






