

如何使用 DeepSeek 构建 AI Agent:终极指南

Ollama是一种现代化的大模型部署解决方案,与Docker类似,利用容器化技术来简化复杂的部署过程。通过Ollama,用户可以在本地环境中轻松启动API服务,访问并使用LLaMA架构的开源大模型。本文将详细介绍如何在不同操作系统中部署Ollama,并通过API调用来与模型交互。
Ollama的安装非常简单,可以从官方网站Ollama下载适用于不同操作系统的安装包。用户需要根据自己的操作系统选择合适的版本,比如macOS、Windows或者Linux。下载后,按照安装向导进行操作,一路点击“下一步”即可完成安装。
安装完成后,用户可以在终端中输入ollama命令来查看Ollama支持的所有命令,包括启动、创建模型、运行模型等。
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
pull Pull a model from a registry
push Push a model to a registry
list List models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information
Use "ollama [command] --help" for more information about a command.Ollama安装后自动启动本地服务,用户可以通过访问本地API端口来验证是否安装成功。默认情况下,Ollama监听在localhost的11434端口。用户可以通过以下命令来测试服务是否正常启动:
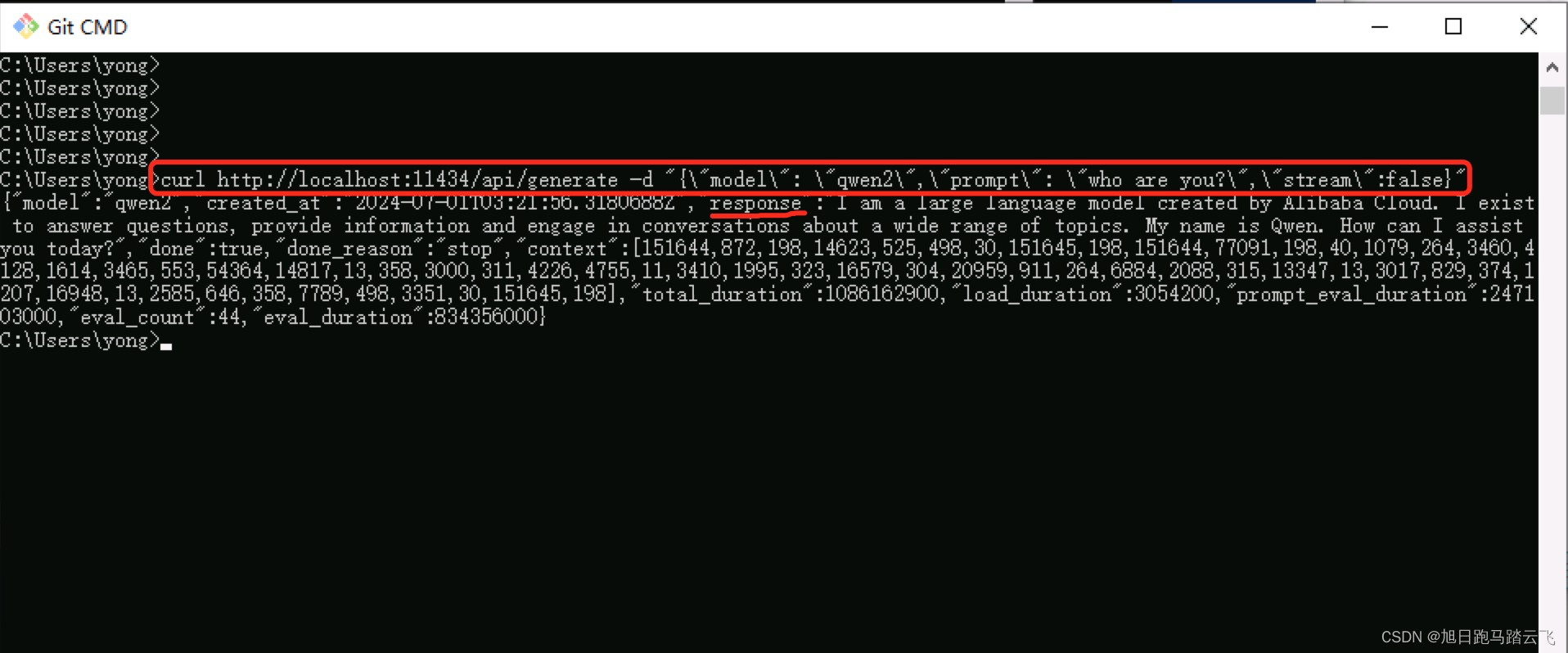
curl http://localhost:11434/api/generate -d '{"model": "qwen2","prompt": "who are you?","stream":false}'如果返回正常的结果,则说明API服务已成功启动。
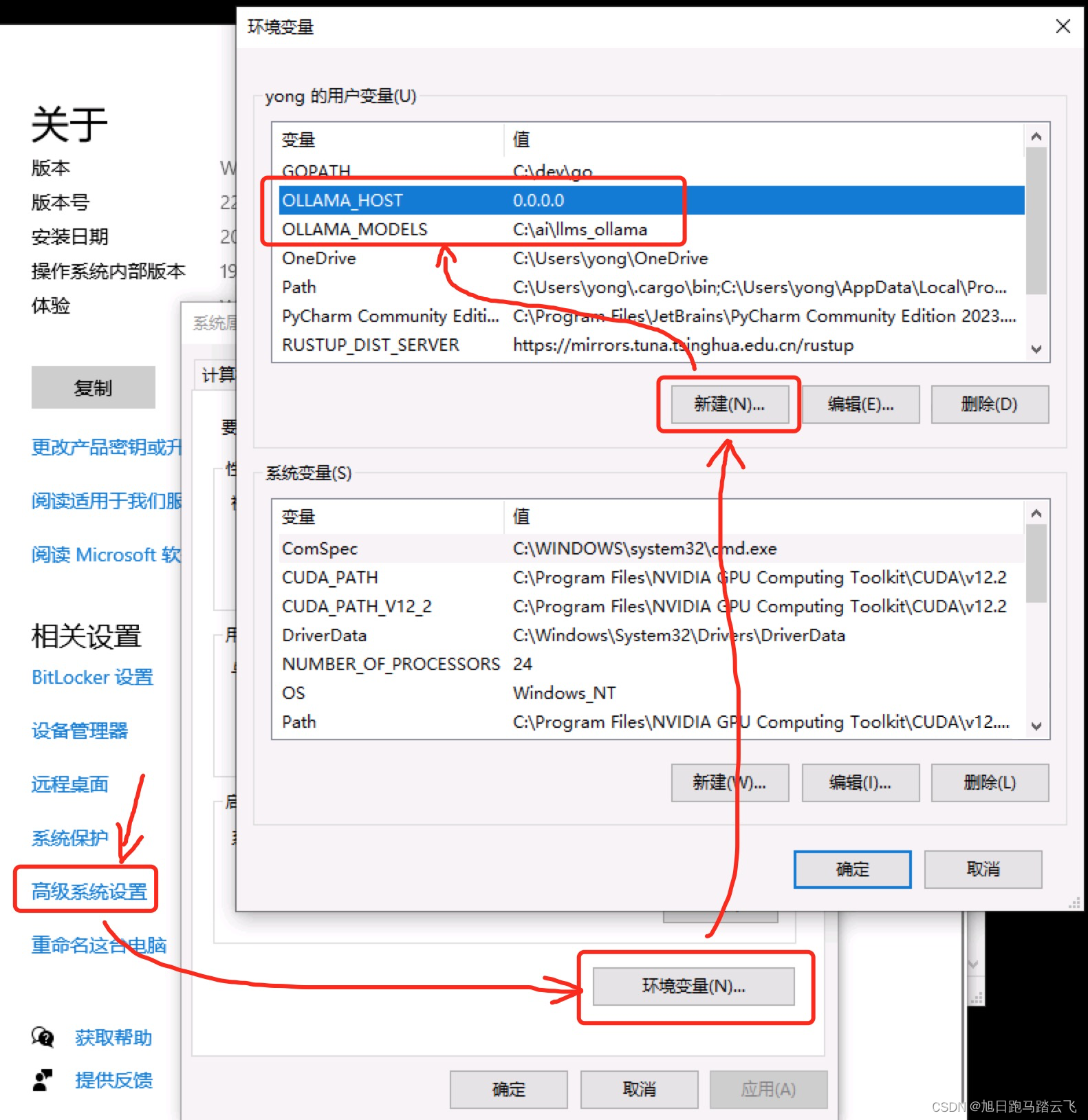
为了支持远程访问,用户需要配置环境变量OLLAMA_HOST为0.0.0.0,这样就可以通过IP地址访问API服务。此外,用户可以通过配置OLLAMA_MODELS来更改大模型的默认存储路径。更改配置后,需要重启Ollama服务使其生效。
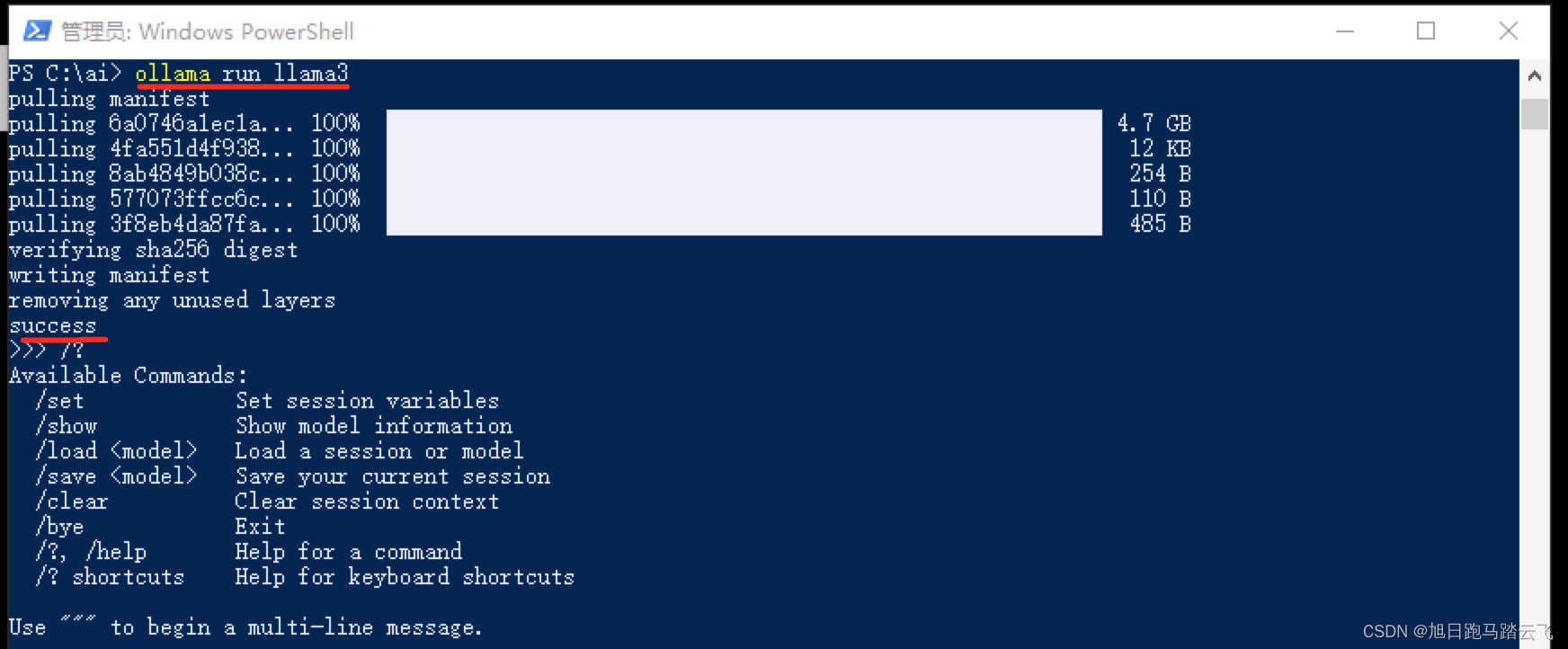
实际部署大模型时,用户可以选择不同的模型版本进行安装和运行。以LLaMA3模型为例,用户可以通过以下命令来运行模型:
ollama run llama3如果模型未下载,Ollama会自动进行下载。下载完成后,模型将自动启动。
用户可以在Jupyter Notebook中通过LangChain直接调用Ollama。需要首先安装Jupyterlab,然后创建一个新的Notebook文件,输入如下代码来调用模型:
from langchain_community.chat_models import ChatOllama
from langchain_core.messages import HumanMessage
ollama_llm = ChatOllama(model="llama3")
messages = [
HumanMessage(content="你好,请你介绍一下你自己")
]
chat_model_response = ollama_llm.invoke(messages)
chat_model_response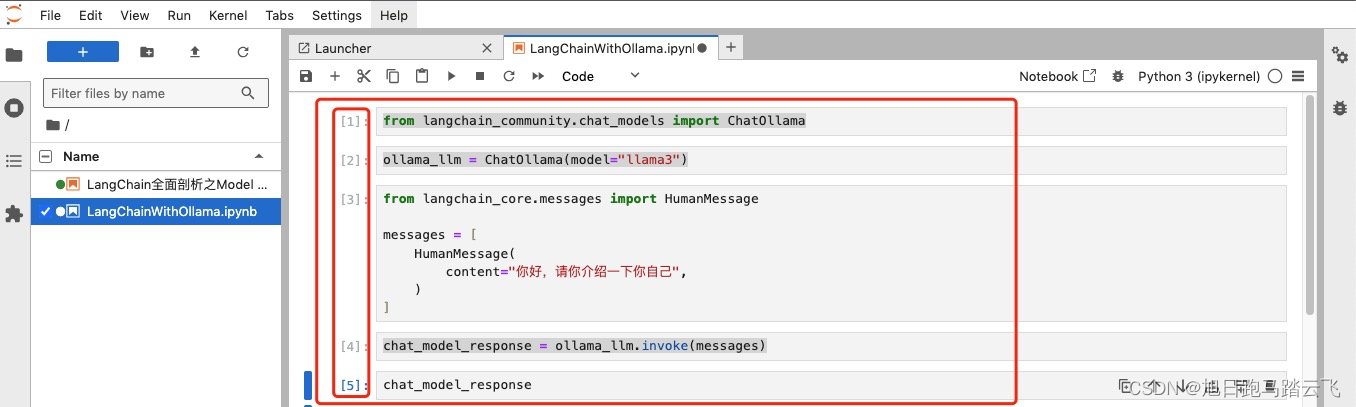
通过Python代码,用户也可以直接调用Ollama的API服务。以下是一个简单示例:
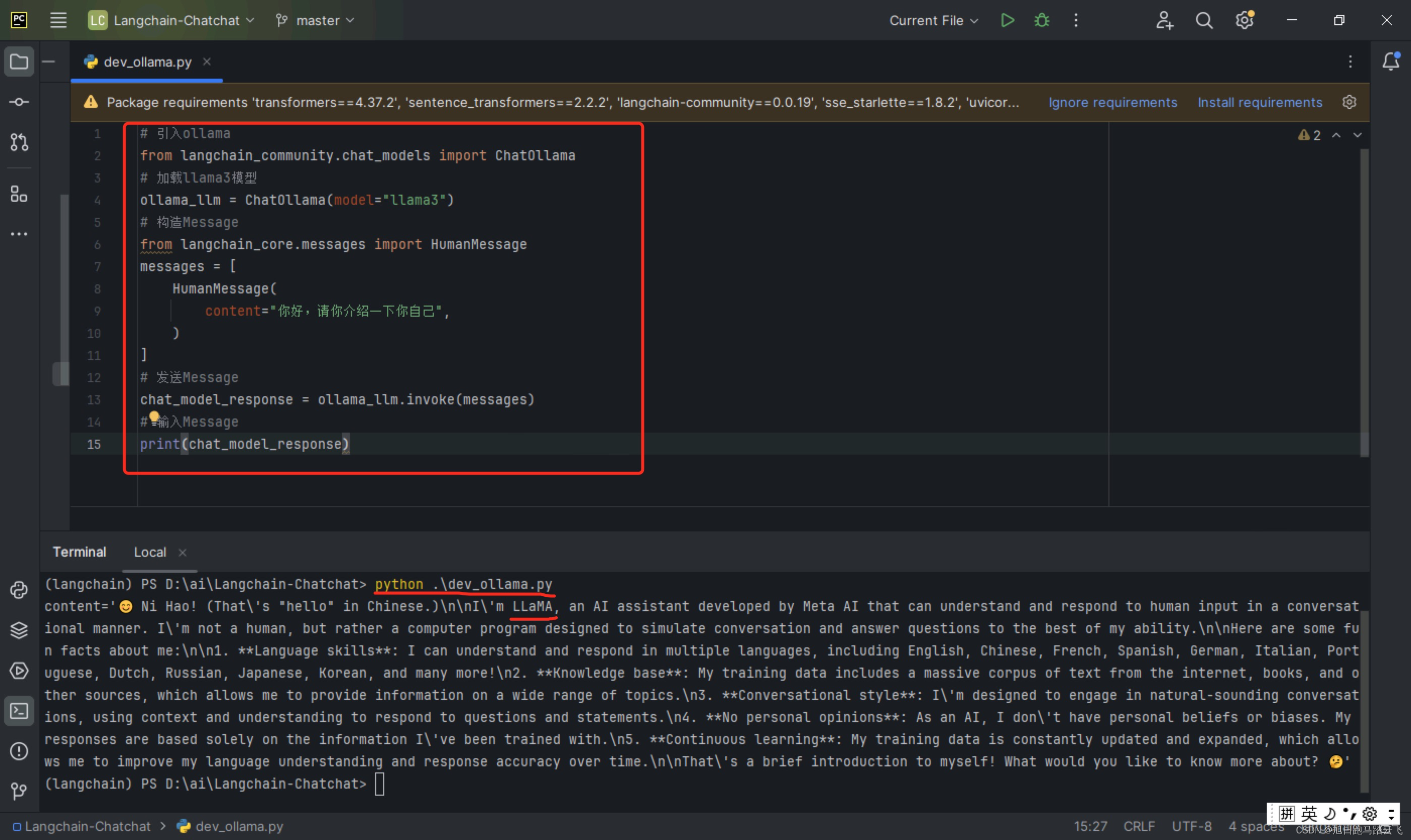
from langchain_community.chat_models import ChatOllama
ollama_llm = ChatOllama(model="llama3")
messages = [HumanMessage(content="你好,请你介绍一下你自己")]
chat_model_response = ollama_llm.invoke(messages)
print(chat_model_response)执行以上代码可以得到AI模型的响应。
Ollama不仅支持终端交互,还允许通过API进行调用。主要提供了generate和chat两个API接口。
generate API用于生成单次交互的数据,可以通过以下命令调用:
curl http://localhost:11434/api/generate -d '{"model": "gemma:2b", "prompt":"介绍一下React,20字以内"}'chat API支持多轮对话,允许保留上下文信息:
curl http://localhost:11434/api/chat -d '{"model": "gemma:2b", "messages": [{"role": "user", "content": "介绍一下React,20字以内"}]}'除了命令行和API,用户还可以使用开源的Web UI工具来更直观地与大模型进行交互。例如,可以使用open-webui来搭建本地的可视化交互界面。
OLLAMA_MODELS来更改默认模型存储路径。OLLAMA_HOST为0.0.0.0,并重启Ollama服务。通过上述步骤,用户可以在本地环境中轻松部署和运行Ollama,利用其强大的API调用功能与大模型进行交互,为开发和测试提供了极大的便利。







