

Optuna使用详解与案例分析

RAG系统,即检索增强生成模型,是一种结合了检索和生成能力的语言模型,广泛应用于问答系统、文本摘要等场景。随着人工智能技术的快速发展,对RAG系统性能的评估变得尤为重要。本文将详细介绍如何使用RAGAS框架对RAG系统进行评估,并探讨其重要性及实施方法。
RAGAS(Retrieval-Augmented Generation Assessment)是一个专门为评估RAG管道性能而设计的框架。该框架不仅帮助开发者和研究人员了解RAG应用的性能表现,还提供了一个度量驱动的开发(MDD)环境,以数据量化的方式指导决策过程,推动RAG系统的持续改进。
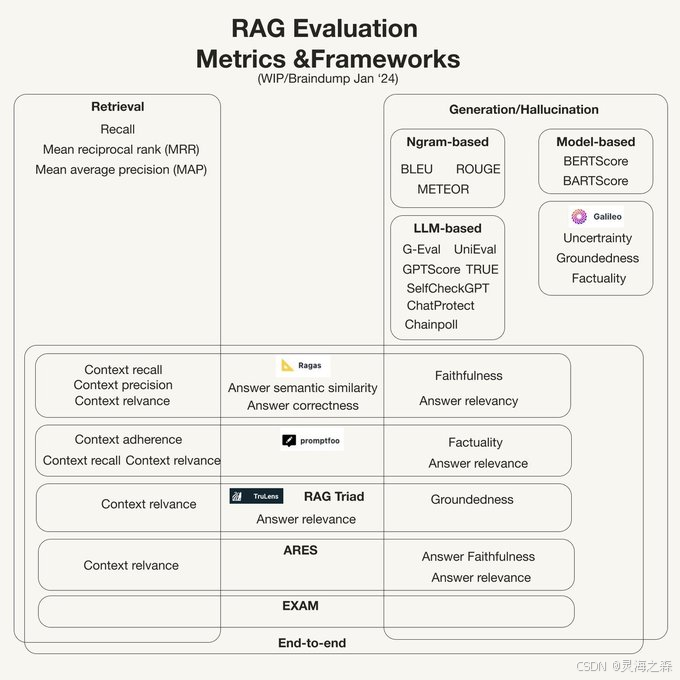
在深入了解RAGAS之前,我们先来看看业界是如何对RAG系统进行评估的。一般来说,RAG系统的评估可以分为三个主要部分:检索、生成/幻觉和端到端评估。
检索部分主要关注的是RAG系统中检索组件的性能。这包括了上下文的精确度和召回率等指标。这些指标能够反映检索系统是否能够准确地从大量信息中找到相关的答案。
生成部分的评估集中在生成的答案是否与检索到的上下文保持一致,以及答案的准确性和相关性。常用的评估指标包括基于n-gram的方法(如BLEU、ROUGE、METEOR)和基于模型的方法(如BERTScore、BARTScore)。
端到端评估是衡量RAG系统整体性能的关键。这部分的评估指标包括上下文召回、上下文精度、上下文相关性、答案语义相似性、答案正确性等。
RAGAS作为一个评估工具,其实施细节是至关重要的。以下是实施RAGAS时需要关注的几个关键点。
RAGAS在评估数据集时,不依赖人工标注的标准答案,而是通过底层的大语言模型(LLM)来进行评估。因此,评估数据集只需要包含问题-答案对(QA对)。
RAGAS提供了多种评估指标,包括组件级和系统级的指标。这些指标能够帮助我们全面地评估RAG系统的性能。

Context Precision是衡量检索到的上下文与真实答案相关的chunk是否排名靠前的指标。该指标的计算方法涉及到对检索到的每个上下文块进行相关性检查,并计算precision@k值。
from datasets import Dataset
from ragas.metrics import context_precision
from ragas import evaluate
data_samples = {...}
dataset = Dataset.from_dict(data_samples)
score = evaluate(dataset,metrics=[context_precision])
score.to_pandas()Context Recall衡量检索到的上下文与标准答案的匹配程度。该指标的计算涉及到将标准答案分解为单独的陈述,并验证每个陈述是否可以归因于检索到的上下文。
from datasets import Dataset
from ragas.metrics import context_recall
from ragas import evaluate
data_samples = {...}
dataset = Dataset.from_dict(data_samples)
score = evaluate(dataset,metrics=[context_recall])
score.to_pandas()Faithfulness衡量生成的答案与给定上下文之间的事实一致性。该指标的计算涉及到将生成的答案分解为单独的陈述,并验证每个陈述是否可以从给定的上下文中推断出来。
from datasets import Dataset
from ragas.metrics import FaithulnesswithHHEM
from ragas import evaluate
faithfulness_with_hhem = FaithulnesswithHHEM()
data_samples = {...}
dataset = Dataset.from_dict(data_samples)
score = evaluate(dataset,metrics=[faithfulness_with_hhem])
score.to_pandas()Answer Relevancy侧重于评估生成的答案与给定提示的相关性。该指标的计算涉及到使用大型语言模型(LLM)从生成的答案中对问题的“n”个变体进行逆向工程,并计算生成的问题与实际问题之间的平均余弦相似度。
from datasets import Dataset
from ragas.metrics import answer_relevancy
from ragas import evaluate
data_samples = {...}
dataset = Dataset.from_dict(data_samples)
score = evaluate(dataset,metrics=[answer_relevancy])
score.to_pandas()Answer Semantic Similarity的概念涉及评估生成的答案与真实答案之间的语义相似程度。该评估使用交叉编码器模型来计算语义相似性得分。
from datasets import Dataset
from ragas.metrics import answer_similarity
from ragas import evaluate
data_samples = {...}
dataset = Dataset.from_dict(data_samples)
score = evaluate(dataset,metrics=[answer_similarity])
score.to_pandas()Answer Correctness的评估涉及将生成的答案与真实答案进行比较,以判断生成的答案的准确性。该评估依赖于真实答案和生成的答案,得分范围从0到1。
特定领域评估指标是一种基于评分量规的评估指标,用于评估模型在特定领域的性能。这种评估方法不需要标准答案(ground-truth),而是通过大型语言模型(LLM)根据知识文档来生成query和answer,然后对answer进行修改和完善,也可以作为ground-truth使用。
LangSmith是LangChain官方的SaaS服务,可以调试、测试、评估和监控构建在任何LLM框架上的链和智能代理,并与LangChain无缝集成。LangFuse则是一个开源的AI应用维护平台,可以作为LangSmith的替代品,并且它集成了LangChain,同时也可直接对接OpenAI API。
答:RAGAS框架的主要优势在于其能够提供全面的评估指标,帮助开发者和研究人员深入了解RAG系统的性能,并指导他们进行系统优化。
答:RAGAS可以通过底层的大语言模型(LLM)来进行评估,不需要依赖人工标注的标准答案。它通过生成query和answer,然后对answer进行修改和完善,作为ground-truth使用。
答:RAGAS支持多种评估指标,包括忠实度、答案相关性、上下文精确度、上下文召回率等,这些指标能够帮助全面评估RAG系统的性能。
答:使用RAGAS进行端到端评估时,需要关注答案语义相似性和答案正确性这两个关键指标。这些指标能够衡量生成答案与真实答案之间的匹配程度和准确性。
答:LangSmith和LangFuse作为AI应用维护平台,可以帮助开发者调试、测试、评估和监控RAG系统,提供可量化的见解和可操作的反馈,从而持续改进系统性能。
RAGAS作为一个强大的评估工具,为RAG系统的开发和维护提供了重要的支持。通过使用RAGAS,开发者和研究人员可以深入理解系统性能,并据此进行优化和改进。RAGAS的实施不仅提高了RAG系统的可靠性和效率,还促进了整个人工智能领域的技术进步。







