

文心一言写代码:代码生成力的探索

通义千问最近推出了QWEN2.5系列模型,提供了更高效和具成本效益的AI解决方案。智匠MindCraft结合了这些模型,并提供API调用功能。本文将详细介绍如何调用Hunyuan-Turbo-Preview的API,并探讨其在成本效益和性能上的优势。
Qwen2.5模型是阿里巴巴最先进的开源模型之一,其72B参数模型在多个指标上可对标Mistral-Large2和Llama3.1-70B等高参数模型。Qwen2.5 72B的API指向Qwen-Plus,其性能可与GPT4o和Claude3.5 Sonnet媲美,价格仅为1元/百万tokens,输入成本为0.8元/百万tokens,输出成本为2元/百万tokens。
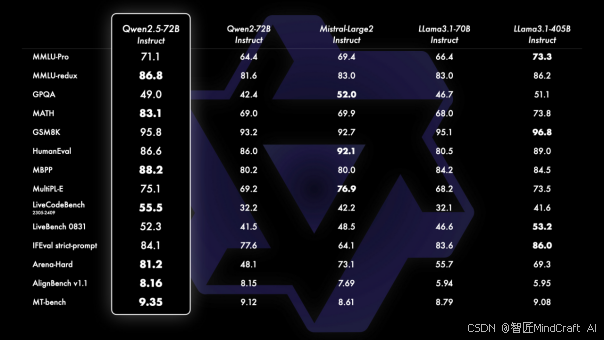
这种高性价比使得Qwen-Plus在商业应用中非常具有竞争力。上下文长度为128K,最大输出为8K,这些特性使得Qwen-Plus在大规模数据处理和复杂任务中表现出色。
Qwen2.5-Math是继Qwen2-Math之后的新一代数学计算模型,其在多个指标上已达到顶级水平。API型号为qwen-math-plus,输入成本为4元/百万tokens,输出成本为12元/百万tokens,最大上下文长度为4K,最大输出为3K。
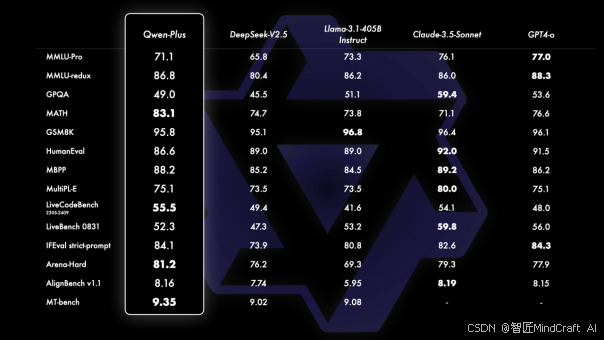
这款模型专注于数学计算领域,其高效的计算能力和高精度的结果使得它在科学研究和工程计算中具有重要应用。
作为通义千问的旗舰商业模型,Qwen-Max的上下文长度为32K,最大输出为8K,输入成本为20元/百万tokens,输出成本为60元/百万tokens。尽管具体性能尚未详述,但预计其性能将超越Qwen2.5。
Qwen-Max适用于需要超大上下文和复杂处理的场景,如自然语言处理和大规模数据分析。
Qwen-Turbo作为通义千问系列的低成本模型,以“速度最快、成本最低”而闻名,适合简单任务。其价格为输入0.3元/百万tokens,输出0.6元/百万tokens,最大上下文长度为128K,最大输出为8K。
这一模型特别适合处理速度要求高、预算有限的项目。
Qwen-VL-Max具备强大的视频识别能力,其性能在行业内处于领先地位。该模型对于需要处理视频数据的应用场景,如视频监控和多媒体内容分析,提供了理想的解决方案。
调用Hunyuan-Turbo-Preview的API需要进行以下步骤:
首先,访问腾讯云混元产品页面进行注册。在注册完成后,您会获得一个API密钥,这是调用API的必要凭证。
在使用API时,需要设置正确的请求头和请求体。以下是一个示例请求配置:
POST /v1/models/hunyuan-turbo-preview/messages HTTP/1.1
Host: api.tencentcloud.com
Content-Type: application/json
Authorization: Bearer
{
"model": "hunyuan-turbo-preview",
"messages": [
{"role": "system", "content": "你是一个有帮助的助手。"},
{"role": "user", "content": "今天天气怎么样?"}
]
}API返回的响应通常是JSON格式,其中包含生成的文本或其他信息。正确解析这些响应对于获取有用的数据至关重要。
在调用API时,可能会遇到各种错误,如身份验证失败或请求格式错误。建议在代码中加入错误处理机制,以确保在发生错误时能够及时响应。
在技术文档和文章中使用图片链接,可以帮助读者更好地理解复杂的概念和流程。确保图片链接的有效性和相关性,是提升文章质量的重要因素。
优化API调用效率可以通过以下几个方面:
在可能的情况下,尽量减少API调用的次数,将多个请求合并为一个,以减少网络通信的开销。
对于静态或不常变化的数据,使用缓存可以显著提高响应速度,减少对API的依赖。
确保每个请求只包含必要的信息,避免冗余数据,以减少带宽消耗和服务器负担。
答:您可以通过访问腾讯云混元产品页面进行注册,并在完成注册后获取您的API密钥。
答:确保请求格式正确,并在请求头中包含有效的API密钥。处理响应时,注意解析返回的JSON格式数据。
答:在代码中加入错误处理机制,捕获并处理常见错误,如身份验证失败或请求格式错误。
答:Qwen2.5模型适合大规模数据处理、复杂任务和需要高性价比的应用场景。
答:可以通过减少请求次数、使用缓存和优化请求内容来提高API调用的性能。






