

PixVerse V3 API Key 获取:全面指南与实践

FIFO-Diffusion 是一种革命性的技术,能够从文本生成无限长度的视频。在这篇文章中,我们将深入探讨如何调用 FIFO-Diffusion 的 API 以实现文本到视频的转换。我们将涵盖其核心机制、技术实现、应用场景以及如何在实际操作中进行 API 调用。
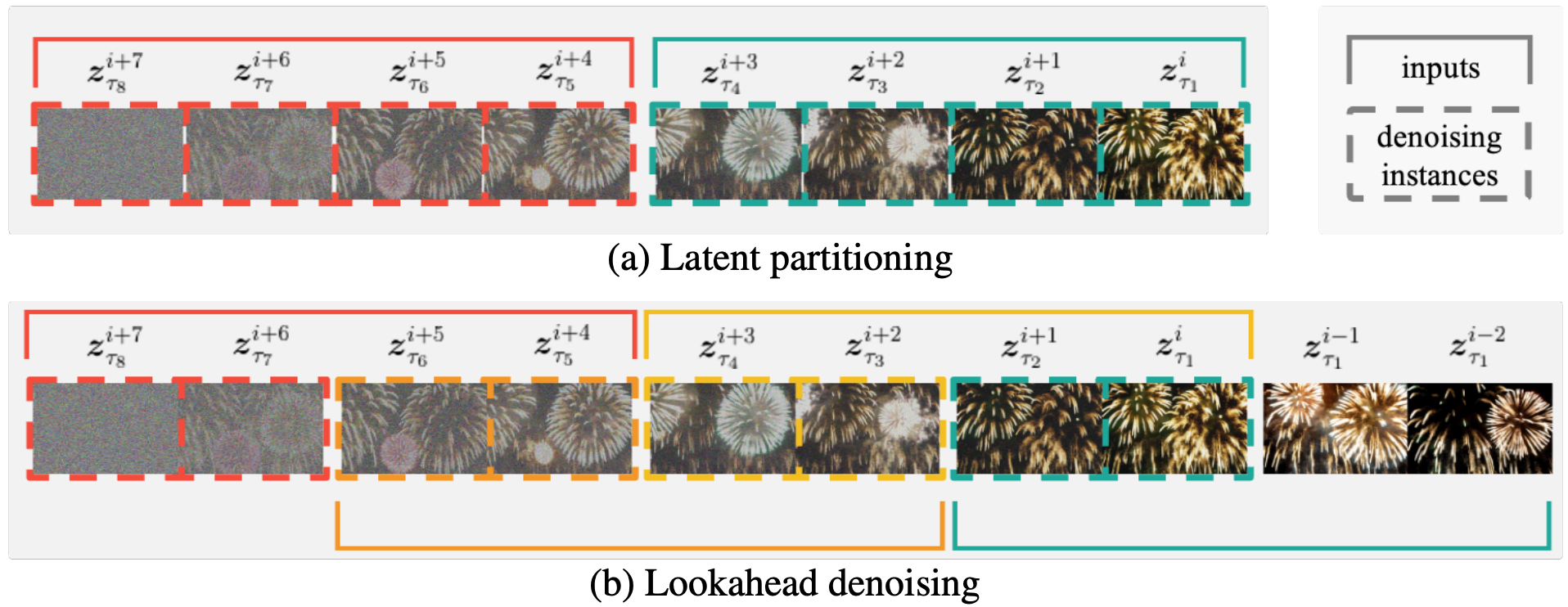
FIFO-Diffusion 是基于预训练扩散模型的新颖推理技术,能够在无需模型训练的情况下生成无限长的视频。其核心在于对角去噪算法,通过将完全去噪的帧出队和新的随机噪声帧入队,实现视频的无缝生成。在此过程中,FIFO-Diffusion 引入了前向降噪和潜在分区技术,以减少训练与推理之间的差距。通过这些优化策略,该技术能够高效地生成高质量的视频。

FIFO-Diffusion 的对角去噪算法是一种处理连续帧中噪声水平不断增加的技术。通过在每一步中执行去噪和重新噪声化,该算法能够在不降低视频质量的情况下生成长视频。此算法的关键在于通过前向参考利用更干净的帧,从而在保持上下文一致性的同时优化视频质量。
潜在分区将扩散过程划分为多个部分,以减少最大噪声水平差异。这种方法结合了前向降噪技术,使所有帧都能用足够数量的前帧进行替代。通过这种方式,FIFO-Diffusion 能够有效地利用已有的干净帧,提升视频生成的效率和质量。
调用 FIFO-Diffusion 的 API 需要遵循一定的步骤和要求。首先,需要注册并获取 API 访问权限。接下来,根据 API 文档来配置请求参数,例如文本描述、视频长度等。最后,通过 HTTP 请求调用 API,并处理返回的数据。
要调用 FIFO-Diffusion 的 API,首先需要在项目官方网站上注册一个开发者账号,并申请 API 访问权限。注册成功后,您将获得一个唯一的 API 密钥,用于身份验证。
在调用 API 时,需要根据文档提供的参数说明配置请求。常见的参数包括:
一旦配置好请求参数,即可通过 HTTP 请求(如 POST 请求)调用 API。以下是一个简单的请求示例:
POST /generate-video
Host: api.fifo-diffusion.com
Content-Type: application/json
Authorization: Bearer YOUR_API_KEY
{
"text": "一个充满活力的水下场景,一个潜水者探索沉船",
"duration": 60,
"model": "VideoCrafter2"
}FIFO-Diffusion 在多个领域中展现了其应用潜力,特别是在创意产业、教育和营销领域。由于其能够从简单的文本描述生成高质量视频,它为内容创作者提供了更多的可能性。
在创意产业中,FIFO-Diffusion 可以辅助艺术家和设计师将想象力转化为视觉内容。通过该技术,艺术家可以轻松创建动态艺术作品,而不需要复杂的技术技能。
在教育领域,FIFO-Diffusion 能够帮助教育者创建生动的教学视频。通过文字描述,教师可以生成复杂理论的动态演示,提高学生的理解力和兴趣。
对于营销团队而言,FIFO-Diffusion 提供了一种快速生成产品宣传视频的工具。通过简单的文本描述,团队可以将产品概念转化为视觉内容,吸引潜在客户的注意力。

FIFO-Diffusion 项目具备多项特点,使其成为一个极具吸引力的开源项目。
该项目的设计考虑到了资源有限的开发者和艺术家,能够在低于 10GB 的 VRAM 环境下高效运行。这对于预算有限的用户来说是一个巨大的优势。
FIFO-Diffusion 支持多种模型配置,包括 VideoCrafter2 和 Open-Sora Plan。这些模型针对不同硬件环境进行了优化,确保了广泛的适用性。
FIFO-Diffusion 是一种基于预训练扩散模型的推理技术,用于生成无限长的视频。它通过文本描述生成视频,而无需模型训练。
要获取 FIFO-Diffusion 的 API 访问权限,您需要在项目官方网站上注册一个开发者账号,并申请 API 访问许可。注册成功后,您将获得一个 API 密钥。
FIFO-Diffusion 设计用于低 VRAM 环境,能够在低于 10GB 的 VRAM 下高效运行,适合资源有限的开发者和艺术家。
使用 FIFO-Diffusion 生成视频需要调用其 API,配置文本描述、视频长度和模型等参数,并通过 HTTP 请求发送给 API。
FIFO-Diffusion 可应用于创意产业、教育和营销等领域,辅助艺术家、教育者和营销团队生成高质量的视觉内容。






