

DeepSeek Janus-Pro 应用代码与图片链接实践


eDiff-I 是一种基于文本到图像扩散模型的生成方法,利用专家去噪器集合来提高生成效率。它不仅能够生成高分辨率的图像,还能处理复杂的文本提示,展示出强大的零样本泛化能力。eDiff-I 的模型通过一系列嵌入(如 T5 文本、CLIP 文本和 CLIP 图像嵌入)来实现条件合成,从而赋予模型多样化的图像生成行为。这一功能让用户可以实现风格迁移,甚至可以通过简单的文本涂鸦来控制生成图像的布局。

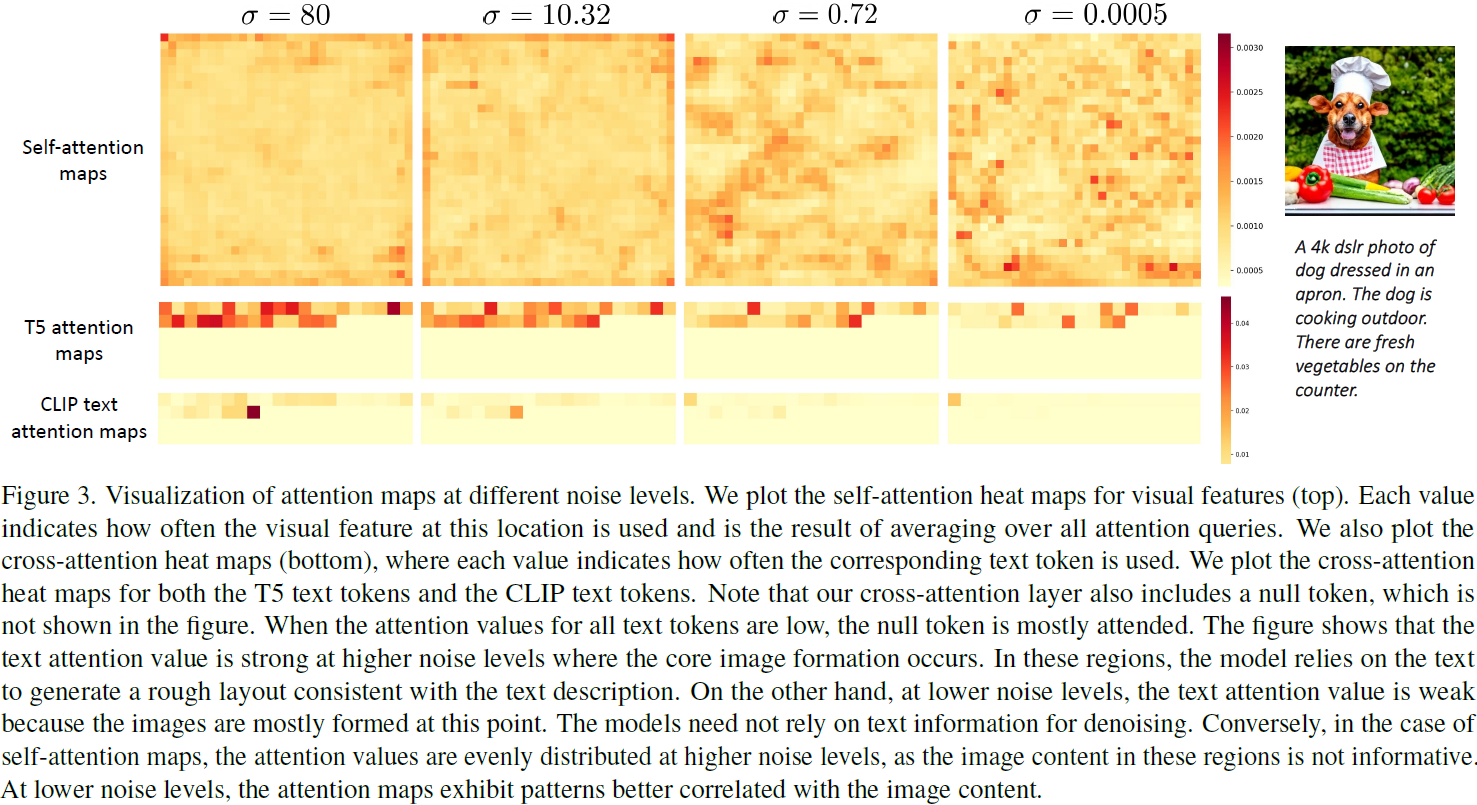
eDiff-I 的核心在于其专家去噪器的设计。通过将生成过程分为多个阶段,每个阶段使用专门的去噪器来处理不同的噪声级别,从而提高生成质量。这样的设计确保了模型在不同阶段能够灵活地处理文本和视觉信息。另一方面,eDiff-I 还集成了多种预训练的文本编码器,提升了模型在生成图像细节上的表现。
在调用 eDiff-I 的 API 之前,用户需要获取访问权限。这通常涉及申请 API Key,之后可以通过该 Key 进行授权调用。要申请 API Key,用户需要注册并登录到 eDiff-I 的官方网站,填写相关信息后即可获得。
eDiff-I 支持多种输入条件,包括 T5 文本嵌入、CLIP 文本嵌入和图像嵌入。这些嵌入在不同的生成阶段发挥不同的作用。通过组合这些输入条件,eDiff-I 能够生成更符合用户预期的图像。
T5 文本嵌入主要用于捕捉输入文本的细节信息,在生成的早期阶段提供对文本的更好理解,从而引导生成过程。
CLIP 文本嵌入有助于确定生成图像的全局外观,而 CLIP 图像嵌入则用于风格迁移,通过参考图像的风格影响生成结果。
eDiff-I 的“用文字作画”功能允许用户通过简单的文字和涂鸦来控制生成图像的布局。用户可以在画布上选择文本短语并进行涂鸦,生成的图像将遵循这些输入的空间布局。
用户在画布上绘制的短语和涂鸦会被转换为二进制掩模,这些掩模与交叉注意力矩阵结合,用于调整生成过程中各图像区域对文本的关注程度。
通过一系列实验,eDiff-I 证明了其在生成图像质量上的优势。与其他模型相比,eDiff-I 在 FID 和 CLIP 分数上表现更佳,尤其是在复杂场景和长文本描述的生成任务中。
在不同的数据集上,eDiff-I 使用 CLIP 和 T5 文本嵌入的表现也有所不同。T5 嵌入在描述性文本中表现优于 CLIP 嵌入,而联合使用这两种嵌入可以获得更好的结果。
eDiff-I 通过其创新的专家去噪器设计和多条件输入支持,实现了高性能的文本到图像生成。未来,eDiff-I 的应用前景广阔,不仅能为数字艺术创作提供便利,还能在更多领域发挥作用。
问:如何获得 eDiff-I 的 API 访问权限?
问:eDiff-I 如何实现风格迁移?
问:eDiff-I 的“用文字作画”功能如何工作?
问:eDiff-I 能否处理长文本描述?
问:如何确保生成图像与文本提示一致?






