大型语言模型训练需要多少台设备?
大型语言模型(Large Language Model, LLM)在近年来成为科技领域的热门话题,其复杂的结构和庞大的数据处理能力使得其应用广泛。然而,如何有效地训练这些模型是一个巨大的挑战。本文将深入探讨大型语言模型的训练需要多少台设备,以及在训练过程中需要考虑的关键因素。
模型训练的基础设施需求
训练大型语言模型需要强大的计算资源。通常,GPU(图形处理单元)是训练这些模型的首选设备,因为它们能够并行处理大量数据,显著加快训练速度。一个训练集群的规模往往取决于模型的复杂性、数据集的大小以及期望的训练速度。下图展示了一个典型的 GPU 集群架构:
在实际应用中,训练一个大型语言模型可能需要数十到数百台 GPU。为了有效地利用这些资源,通常需要采用多种并行计算策略,包括数据并行、模型并行和流水线并行等。
数据并行与模型并行
数据并行
数据并行是将整个数据集分成多个小数据集,每个 GPU 负责处理一个小数据集。这种方法可以显著缩短训练时间,因为多个 GPU 可以同时进行计算。然而,数据并行的缺点是需要在每轮训练后同步所有 GPU 的参数,这可能会导致通信瓶颈。
模型并行
模型并行是将模型本身划分为不同的部分,每个 GPU 负责计算一部分。这种方法适用于非常大的模型,因为它可以将模型的计算负载分散到多个设备上。然而,模型并行需要更多的协调和通信,可能会增加复杂性。
流水线并行与混合并行
流水线并行
流水线并行是一种将模型的层级结构分配给不同 GPU 的方法。每个 GPU 负责处理输入的一个阶段,然后将结果传递给下一个 GPU。这种方法可以减少 GPU 的闲置时间,提高集群的利用率。
混合并行
混合并行结合了数据并行和模型并行的优点。在这种设置中,不同的并行策略可以根据训练的不同阶段进行动态调整,以优化资源利用和训练速度。这种灵活性使得混合并行成为处理超大规模模型的理想选择。
计算资源的优化策略
在大型语言模型的训练中,如何有效利用计算资源是一个关键问题。以下是一些常见的优化策略:
梯度压缩
梯度压缩是一种减少 GPU 之间通信量的方法。通过只发送重要的梯度信息,可以显著降低通信开销,从而提高整体训练速度。
网络辅助计算
利用可编程交换机进行简单的计算操作,可以减轻 GPU 的负担。这种方法可以加快数据处理速度,减少网络延迟。
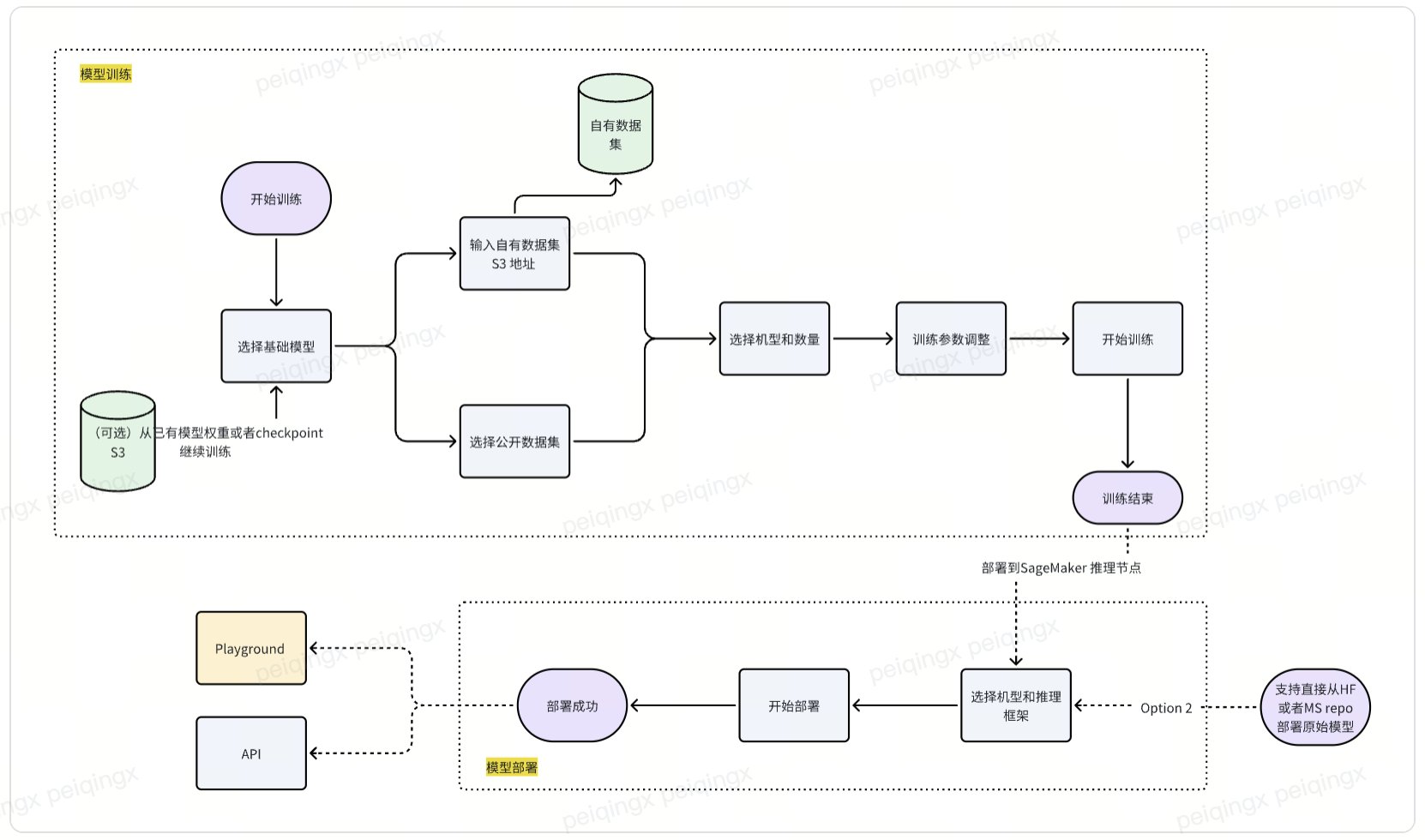
使用 Amazon SageMaker 进行模型微调
Amazon SageMaker 提供了一种灵活的方式来训练和微调大型语言模型。通过 SageMaker,用户可以轻松地调整训练参数,选择适合的硬件配置,并在模型训练过程中监控各项指标。
SageMaker 的使用步骤
- 选择模型和数据集:在 SageMaker 控制台中选择要训练的模型和相应的数据集。
- 配置训练参数:根据模型的需求设置训练参数,包括学习率、批量大小等。
- 启动训练任务:使用 SageMaker 的 Python SDK 启动训练任务,并实时监控训练进度。
微调方法的选择
在微调大型语言模型时,有多种方法可供选择。常见的微调方法包括全参数微调、PEFT(参数高效微调)和 LoRA(低秩适应)。
全参数微调
全参数微调涉及调整模型的所有参数,以适应特定任务。这种方法可以实现最佳的性能,但需要大量的计算资源。
LoRA 微调
LoRA 微调通过低秩矩阵分解来减少权重和计算复杂度,这是针对资源有限的情况的一种高效方法。尽管性能可能略逊于全参数微调,但其计算成本显著降低。
结论
训练大型语言模型需要考虑多种因素,包括硬件资源、并行策略和微调方法。通过合理配置和优化,可以在确保模型性能的同时降低计算成本。未来,随着技术的不断进步,大型语言模型的训练将变得更加高效和可及。
FAQ
-
问:大型语言模型的训练需要多少台 GPU?
- 答:这取决于模型的复杂性和数据集的大小。通常,训练一个大型语言模型可能需要数十到数百台 GPU。
-
问:数据并行和模型并行有什么区别?
- 答:数据并行是将数据集分成多个小数据集分配给不同的 GPU,而模型并行是将模型本身分成不同的部分分配给不同的 GPU。
-
问:SageMaker 如何帮助优化大型语言模型的训练?
- 答:SageMaker 提供了灵活的硬件配置和训练参数设置,帮助用户在训练过程中实时监控和优化模型性能。
-
问:LoRA 微调适用于哪些场景?
- 答:LoRA 微调适用于计算资源有限的场景,因为它能有效降低计算成本,同时保持较高的模型性能。
-
问:在微调过程中如何选择合适的参数?
- 答:可以通过试验不同的参数组合,并根据模型的性能指标进行调整,以找到最佳的参数配置。