

LLM的预训练任务有哪些

HDBSCAN是一种基于密度的聚类算法,类似于DBSCAN,但具有自动确定簇数的优势。本文详细介绍了HDBSCAN在Python中的实现及参数选择方法,并展示了其在离群值检测中的应用。HDBSCAN尤其适合处理噪声数据和发现非凸形状的簇。通过合理选择参数,HDBSCAN可以有效地识别数据中的结构和异常点。
DBSCAN是一种基于密度的聚类算法,它不需要指定聚类的数量。算法通过定义两个关键参数:Eps(领域半径)和MinPts(最少点数),来识别数据集中的密集区域,并将其标记为簇。Eps定义了一个点的邻域范围,而MinPts确定了在该邻域内必须包含的最少点数,以使该点成为核心点。
DBSCAN从一个未访问的点开始,将其标记为访问过,并检查其是否为核心点。如果是,则形成一个新的簇,并将该核心点的Eps邻域内的所有点加入到候选集N中。然后,迭代地检查N中的每个点,扩展该簇,直到N为空。此时,簇已完全生成,算法会继续寻找下一个未访问的点。
在DBSCAN中,点与点之间的关系通过密度可达和密度相连来定义。密度可达意味着一个点可以通过核心点的链条到达另一个点,而密度相连意味着两个点可以通过一个公共核心点相互连接。这种关系帮助算法识别簇结构。
选择合适的Eps值对于DBSCAN的效果至关重要。通常使用k-distance图来选择Eps值。通过计算每个点到其第k个最近邻的距离,并将这些距离排序后绘制图形,可以通过找到图中的拐点来确定Eps值。
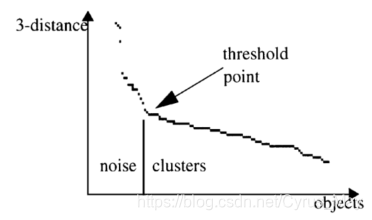
MinPts的选择通常基于Eps的选取,建议选择k值加1。具体来说,如果你选择的k值为2倍的特征数减1,那么MinPts应该为k加1。这确保了每个核心点的邻域内有足够的点数来形成一个有效的簇。
Eps和MinPts的组合决定了DBSCAN的聚类结果。过大的Eps会导致簇数量减少,过小的MinPts会导致噪声点增加。因此,选择合适的参数需要根据数据分布进行多次试验和调整。
在Python中,可以使用scikit-learn库来实现DBSCAN聚类。首先,需要导入必要的库,并设置随机种子以确保结果的可重复性。
import numpy as np
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN
np.random.seed(2021)为了展示DBSCAN的效果,我们生成moon数据并进行绘图。这些数据有助于展示DBSCAN在处理非凸形状数据集时的优势。
data = np.ones([1005,2])
data[:1000] = make_moons(n_samples=1000, noise=0.05, random_state=2022)[0]
data[1000:] = [[-1,-0.5], [-0.5,-1], [-1,1.5], [2.5,-0.5], [2,1.5]]
plt.scatter(data[:,0],data[:,1],color="c")
plt.show()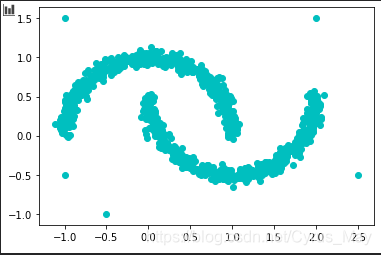
使用DBSCAN类来创建聚类模型并进行训练。通过选择合适的Eps和MinPts参数,可以有效地识别数据中的簇。
k = 3 # 2*维度-1
k_dist = select_MinPts(data, k)
k_dist.sort()
plt.plot(np.arange(k_dist.shape[0]), k_dist[::-1])
# 由拐点确定邻域半径
eps = k_dist[::-1][15]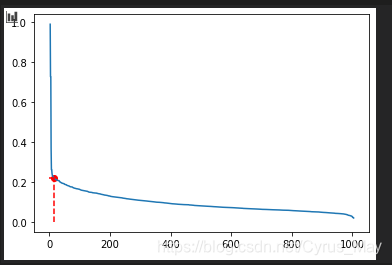
DBSCAN不仅可以用于簇的识别,还非常适合用于检测数据中的离群值。通过分析聚类结果,可以识别数据集中不属于任何簇的点,这些点通常被视为噪声或离群值。
在DBSCAN聚类后,通过可视化将核心点、边界点和噪声点进行区分,可以清晰地看到数据的分类情况以及离群值的分布。
class_1 = []
class_2 = []
noise = []
for index, value in enumerate(label):
if value == 0:
class_1.append(index)
elif value == 1:
class_2.append(index)
elif value == -1:
noise.append(index)
plt.scatter(data[class_1, 0], data[class_1, 1], color="g", label="class 1")
plt.scatter(data[class_2, 0], data[class_2, 1], color="b", label="class 2")
plt.scatter(data[noise, 0], data[noise, 1], color="r", label="noise")
plt.legend()
plt.show()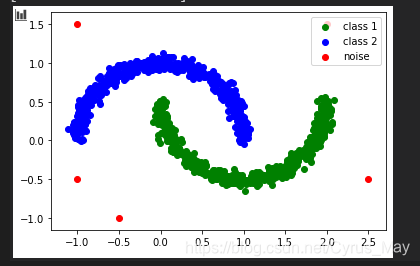
通过DBSCAN聚类实例,可以观察到算法在处理不同数据分布时的优劣。尤其是当数据集存在大量噪声时,DBSCAN能够有效地识别出这些异常,并提供合理的聚类结果。
在scikit-learn中,DBSCAN类用于实现密度聚类。该类通过定义Eps和min_samples等参数,帮助用户识别数据中的自然簇结构。这种方法特别适合处理具有不同密度和非凸形状的数据集。
DBSCAN类的关键参数包括:
调节Eps和min_samples的值是DBSCAN性能优化的关键。通常,需要通过多次实验来找到合适的参数组合,以便获得最佳的聚类效果。
通过生成一组具有不同形状的数据集,可以测试DBSCAN在处理非凸形状和噪声数据时的能力。下图展示了数据的初始分布。
from sklearn import datasets
X1, y1 = datasets.make_circles(n_samples=5000, factor=.6, noise=.05)
X2, y2 = datasets.make_blobs(n_samples=1000, n_features=2, centers=1.2, 1.2, cluster_std=.1, random_state=9)
X = np.concatenate((X1, X2))
plt.scatter(X[:, 0], X[:, 1], marker='o')
plt.show()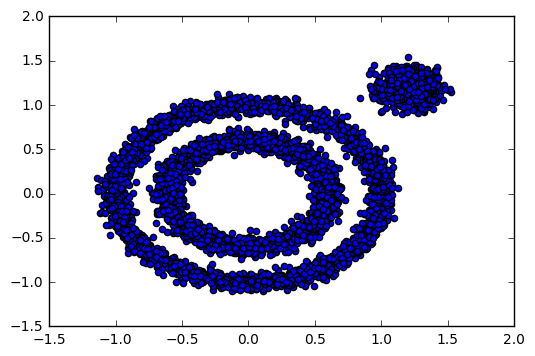
使用默认参数的DBSCAN可能无法直接得到满意的聚类结果。因此,需要通过调整Eps和min_samples来优化聚类效果。
from sklearn.cluster import DBSCAN
y_pred = DBSCAN(eps=0.1, min_samples=10).fit_predict(X)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.show()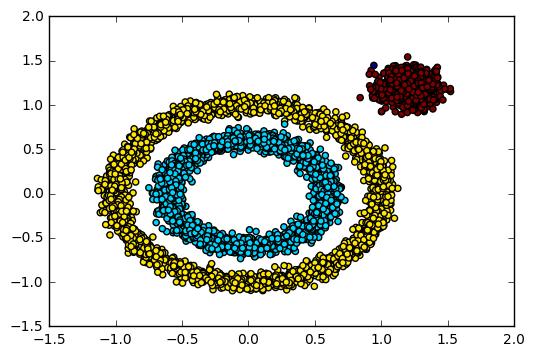
通过调参,DBSCAN可以更准确地识别数据中的簇结构和噪声点。这个过程表明了参数选择对聚类结果的重要性。







