

豆包 Doubao Image API 价格全面解析

Gopher是由DeepMind开发的大语言模型,以其卓越的性能在自然语言处理领域引起了广泛关注。Gopher模型是基于自回归Transformer架构,并进行了多项优化以提升其在大规模文本数据集上的表现。相比于早期的语言模型,Gopher显著提高了在知识密集型任务上的表现,特别是在事实检测和常识推理方面。

Gopher的开发始于对语言模型的深刻理解和技术的不断进步。通过结合现代计算能力和先进的神经网络结构,Gopher能够在大规模数据集上进行高效的训练,并在多个自然语言处理任务中表现出色。其训练集MassiveText包含来自网页、书籍、新闻和代码的多源文本数据,为模型提供了丰富的语料支持。
Gopher采用自回归Transformer架构,并在此基础上进行了一些关键的创新,如使用LayerNorm替代RMSNorm,以及相对位置编码替代绝对位置编码。这些修改不仅提高了模型的训练效率,还使得Gopher能够处理比训练时更长的序列。这一特性使得Gopher在处理复杂任务时具有更大的灵活性和准确性。
在训练过程中,Gopher使用了Adam优化器,并通过调整学习率和批次大小来提高模型的稳定性和收敛速度。特别是在大规模训练中,Gopher通过增加每批次中的token数量和降低最大学习率来适应更大的模型规模。此外,采用bfloat16数值格式不仅减少了存储需求,还提高了训练吞吐量。
Gopher的训练和评估基于TPUv3集群,利用JAX和Haiku构建的代码库实现数据和模型并行。通过状态分区、模型并行和rematerialisation技术,Gopher能够在有限的TPU内存中高效运行。同时,数据并行和模型并行的低开销特性使得Gopher在大规模TPU集群中能够快速训练和评估。
Gopher在152个自然语言处理任务中进行了广泛的评估,结果显示其在阅读理解、人文科学、伦理、STEM和医学等领域均有显著的性能提升。特别是在知识密集型任务中,Gopher的表现超过了许多现有的最先进模型,如GPT-3和Jurassic-1。
Gopher在事实检测任务中展现了强大的能力,能够在提供证据的情况下超越有监督的SOTA模型。随着模型规模的增加,Gopher在区分真实信息和错误信息上的能力也有所提升,表明其在处理复杂语义任务时具备更高的准确性和可靠性。
Gopher在对话生成任务中通过使用few-shot方法进行prompting,能够模拟出高质量的对话内容。与传统的对话数据微调方法相比,Gopher在少量人类研究中展现了无显著差异的优越表现,进一步验证了其在对话生成中的潜力。
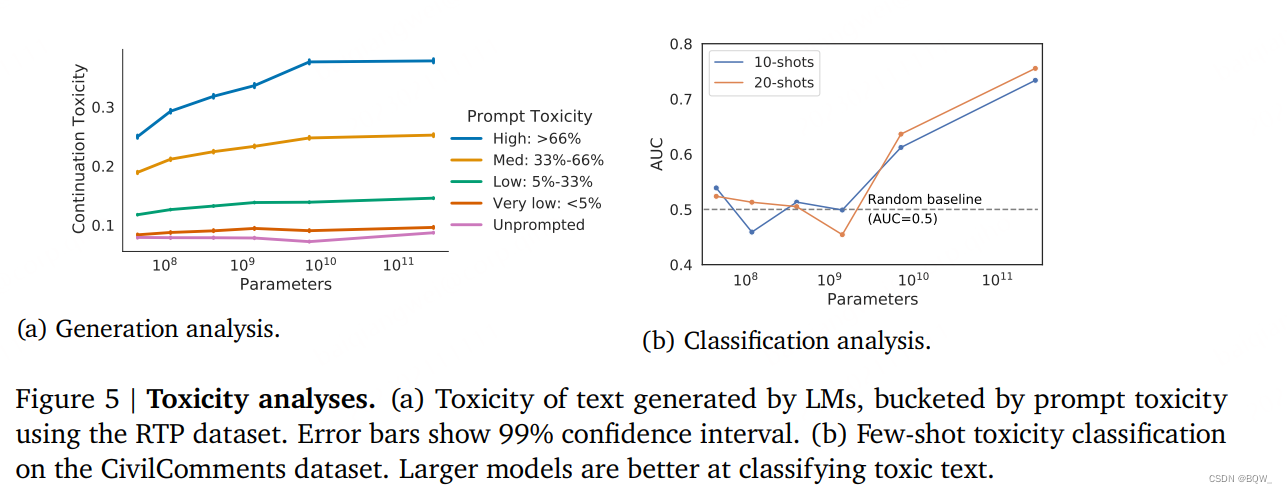
Gopher在生成文本时可能会出现毒性和偏见问题,特别是在处理带有毒性提示的情况下。虽然较大的模型能够更好地理解和处理这些提示,但仍然存在生成不当内容的风险。因此,在实际应用中需要对生成结果进行仔细审查和过滤。
尽管Gopher在许多任务中表现出色,但其性能提升并非均匀分布。在某些数学和逻辑推理任务中,模型规模的增加未能带来显著的性能提升。因此,如何在规模和性能之间找到最佳平衡点,仍然是一个需要持续探索的问题。
随着Gopher模型的不断改进,其在私人AI助手中的应用前景广阔。通过结合自然语言处理和对话生成能力,Gopher可以在个性化服务、智能问答和信息检索等领域发挥重要作用,为用户提供更加智能和高效的服务。
未来,Gopher可以通过多语言预训练和适应性学习,进一步拓展其在不同语言和文化背景下的应用能力。这将使其成为全球化背景下强大的AI助手工具。
Gopher的未来发展可以与其他前沿技术相结合,如增强现实、物联网和区块链等,形成更加综合和智能的服务平台。这将为用户带来更全面的智能体验和更高效的服务。
Gopher作为一个先进的大语言模型,在自然语言处理领域展示了其强大的潜力和广泛的应用价值。然而,在追求更高性能的同时,我们也需要警惕其可能带来的伦理和社会问题。通过不断优化和完善模型,我们期待Gopher能够在未来的AI发展中发挥更加积极的作用。
问:Gopher模型在什么任务上表现最好?
问:Gopher如何应对毒性和偏见问题?
问:如何在个人AI助手中应用Gopher?





