

如何调用 Minimax 的 API

近年来,文本到图像合成技术迅速发展,尤其是自回归和扩散模型的崛起,使得图像生成进入了一个新的时代。然而,这些模型往往需要大量的计算资源和时间进行迭代推理。本文介绍了一种新型的生成对抗网络(GAN)架构——GigaGAN,它不仅在速度上远超传统方法,而且在图像质量和灵活性上表现出色。
GigaGAN的出现是为了应对现有文本到图像合成模型的局限性。传统的生成模型如StyleGAN具有强大的生成能力,但在处理复杂数据集时常显得力不从心。GigaGAN通过创新的架构设计,成功将GAN的优势应用于大规模数据集的图像生成中。
生成对抗网络(GAN)由生成器和鉴别器组成,生成器负责生成逼真的图像,而鉴别器则用于判别图像的真伪。两者通过对抗训练不断优化,使得生成器生成的图像越来越逼真。
GigaGAN在传统GAN的基础上引入了多种创新技术,包括样本自适应内核选择和交错注意力机制。这些改进使其能够在大规模数据集上稳定训练,并生成高质量的图像。
GigaGAN的核心结构包括生成器、鉴别器和基于GAN的上采样器。生成器通过映射网络和合成网络的协同作用,将条件向量和潜在代码映射为高质量图像。
生成器的设计重点在于如何有效利用文本信息来调制生成过程。GigaGAN通过引入交叉注意力机制,使得生成器可以精准地捕捉文本提示中的细节信息,从而生成与文本描述高度一致的图像。

GigaGAN采用了一种创新的样本自适应内核选择方法,通过动态选择卷积滤波器来增强生成器的表现力。这一技术使得GigaGAN能够在不同的图像生成任务中灵活调整其生成策略。

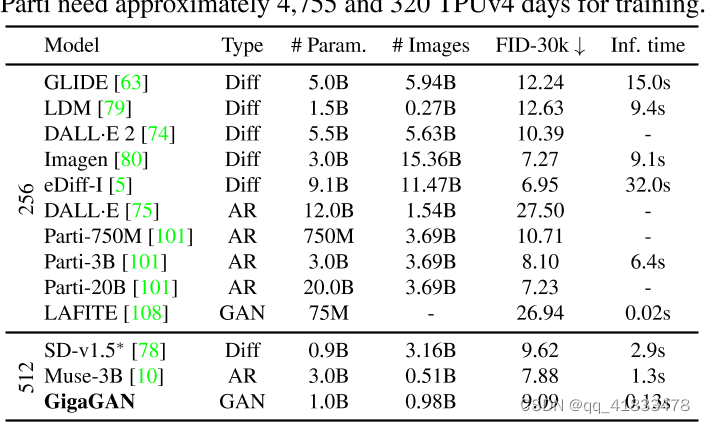
通过一系列实验,GigaGAN在多个方面展现了其优越性。与其他主流模型进行对比,GigaGAN在速度和质量上均有显著提升。
在相同条件下,GigaGAN的推理速度比Stable Diffusion快了数十倍,仅需0.13秒即可生成一张512像素的图像。这一优势使得GigaGAN非常适合实时应用场景。
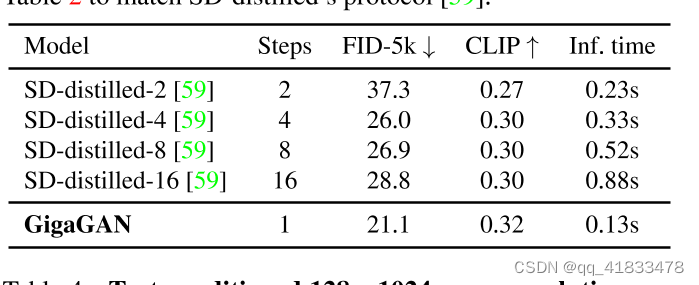
在与SD-distilled模型的比较中,GigaGAN在图像生成的质量和速度上均表现出色,其生成的图像在细节处理和色彩还原上更为出色。
GigaGAN不仅在图像生成速度上有突破,其在潜在空间编辑应用上也展现了巨大的潜力,包括风格混合、提示插值和提示混合等。
风格混合是通过在生成过程中使用两个随机潜码实现的。GigaGAN能够将不同风格的要素进行结合,生成具有全新风格的图像。

通过在提示之间进行插值,GigaGAN能够生成从一种风格平滑过渡到另一种风格的图像。这个特性使其在艺术创作和设计领域具有广泛的应用潜力。

在推理速度和图像分辨率方面,GigaGAN具有无可比拟的优势。然而,其生成的视觉质量尚未达到DALL·E 2等生产级模型的水平。
尽管GigaGAN在速度上占据优势,但在视觉效果上仍无法与DALL·E 2等模型媲美。模型生成的细节和真实感仍需进一步优化。

GigaGAN展示了GAN在文本到图像合成领域的巨大潜力,其独特的架构设计为未来的研究提供了新的思路。随着技术的不断进步,GigaGAN有望在更多应用场景中展现其强大的生成能力。
问:什么是GigaGAN?
问:GigaGAN的主要优势是什么?
问:GigaGAN与其他模型相比如何?
问:GigaGAN的应用领域有哪些?
问:GigaGAN的未来发展方向是什么?





