

Node.js 后端开发指南:搭建、优化与部署

在当前的信息化时代,处理和理解表格数据已成为日常工作中不可或缺的一部分。无论是在文档还是电子表格中,表格数据的应用场景广泛而复杂。微软的研究论文《Table-GPT: Table-tuning GPT for Diverse Table Tasks》为我们提供了一个全新的视角,即通过Table-GPT模型优化大型语言模型(LLM)对表格数据的理解能力。本文将深入探讨Table-GPT模型的创建、性能及其在实际办公场景中的应用,以帮助用户从数据整理到表格应用选择正确的GPT模型。

Table-GPT模型是微软针对大型语言模型(LLM)在表格任务中的表现进行优化的结果。该模型通过更好地理解输入中的表格数据,提高了对表格相关问题的响应准确性。这对于需要处理大量表格数据的用户来说是一个巨大的进步,因为它意味着可以更准确地从表格中提取信息,并生成准确的响应。
大型语言模型大多是在自然语言文本和代码上进行预训练的,这些数据与表格数据有着本质的不同。表格数据的二维特性使其在理解和回答相关问题时,需要模型具备垂直阅读的能力。然而,目前的LLM在处理表格数据时,往往更擅长水平推理而不是垂直推理。

在缺失值识别任务中,模型需要识别并准确地指出表格中缺失值所在的行和列。从示例中可以看出,尽管模型能够识别出行,但在列的识别上却存在错误。

在列过滤任务中,模型需要根据给定的值找到对应的列。从示例中可以看出,模型的回答并不准确,这表明模型在处理表格数据时存在一定的局限性。

在更复杂的表格问答任务中,模型需要根据表格数据回答问题。从示例中可以看出,模型在回答有关二年级学生美术成绩的问题时,给出了错误的结果。
表调优(Table-Tuning)是一种新方法,它受到指令调优的启发,并在大型语言模型中被证明是成功的。通过在表指令数据集上微调模型,可以创建出在表格任务上表现更好的模型版本。
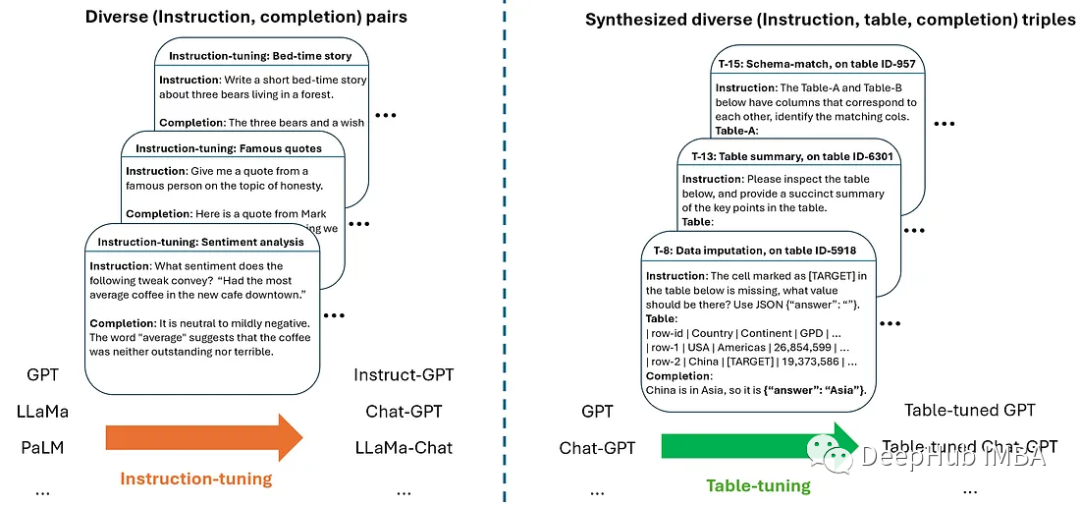
用于表调优的数据集是通过合成增强的方法创建的。这种方法从大量真实的表格开始,通过自动生成带有指令、表格和响应的三元组样本,从而创建出一个多样化的标记数据集。
在合成步骤中,从一组支持的任务中采样一个真实的表格和一个任务,创建新的样本。生成的示例中的表不一定与输入表相同,这为模型提供了更多的训练样本。
在合成步骤之后,为了创建更多样化的数据集,论文使用了三种类型的增强:指令级增强、表级增强和标签级/响应级增强。这些增强方法有助于提高模型的泛化能力,并确保数据的多样性。
TableLLM是一款具备130亿参数的大型语言模型,专为处理表格数据任务而生。它采用了一种创新的远程监督训练法,结合推理扩展策略,让模型能更好地把握推理模式,并通过交叉验证确保数据生成的质量。
TableLLM的整体架构包括构建远程监督学习训练数据和模型训练两个部分。模型训练针对文档嵌入的和电子表格嵌入的表格数据使用不同的提示,以适应不同的应用场景。
TableLLM在电子表格嵌入场景中普遍超越其他方法,在文档嵌入场景中与GPT-3.5持平。这表明TableLLM在处理表格数据方面具有显著优势,尤其是在电子表格数据的应用场景中。
答:Table-GPT模型通过表调优(Table-Tuning)的方法,在表指令数据集上微调模型,使模型能够更好地理解输入中的表格数据,并提高对表格相关问题的响应准确性。
答:表调优的数据集是通过合成增强的方法创建的。首先从大量真实的表格开始,通过自动生成带有指令、表格和响应的三元组样本,从而创建出一个多样化的标记数据集。
答:TableLLM模型的主要优势在于其专门针对表格数据任务设计,能够适应各种实际办公需求。它采用了远程监督训练法和推理扩展策略,通过交叉验证确保数据生成的质量,从而在处理表格数据方面展现出显著优势。
答:TableLLM模型在电子表格嵌入场景中普遍超越其他方法,在文档嵌入场景中与GPT-3.5持平。这表明TableLLM在处理电子表格和文档中的表格数据方面具有强大的性能。
从数据整理到表格应用,选择合适的GPT模型对于提高工作效率和准确性至关重要。Table-GPT模型和TableLLM模型的出现,为处理表格数据提供了新的解决方案。它们通过优化模型对表格数据的理解能力,使得从数据整理到表格应用变得更加高效和准确。随着技术的不断进步,我们可以期待未来会有更多创新的模型和方法出现,进一步推动表格数据处理的发展。






