

大模型RAG技术:从入门到实践


大模型微调(Fine-tuning)是针对预训练模型进行针对性优化的过程,旨在提升其在特定任务上的性能。通过微调,模型可以适应特定领域的需求,表现出更高的准确性和效率。微调的核心在于利用特定领域的数据集,对已预训练的模型进行进一步训练,使其在特定任务上表现更佳。
微调不仅是提升模型性能的关键手段,也是实现模型定制化的重要步骤。大模型,如GPT-3、BERT等,虽然在通用任务上表现出色,但在特定领域的应用中往往需要进一步优化。这一过程能够让模型更好地理解领域特定的语言模式和知识,从而提升任务表现。
微调的核心在于通过特定领域的数据对预训练模型进行优化。这个过程涉及对模型参数的调整,尤其是超参数的设置,如学习率、批次大小和训练轮次等。超参数的合理设置对于微调的成功至关重要。
在微调过程中,模型通过不断调整参数,逐步适应新的数据分布,从而在特定任务上取得更好的性能。合理的超参数设置可以加速训练过程,提高模型的收敛速度和最终性能。
选择合适的平台进行微调是成功的关键。Hugging Face 是一家专注于自然语言处理(NLP)模型训练和部署的平台公司,提供了丰富的预训练模型和工具,助力快速开发与部署。
Hugging Face 平台的优势在于其跨平台兼容性,与 TensorFlow、PyTorch 和 Keras 等主流深度学习框架兼容。其微调工具可以节省从头开始训练模型的时间和精力,而庞大的用户社区也为用户提供了丰富的支持和帮助。
在开始微调之前,首先需要选择与任务相关的数据集,并对其进行预处理。这包括数据的清洗、分词和编码等步骤。数据的质量直接影响到微调的效果,因此需要确保数据集的准确性和多样性。
选择一个适合的预训练模型是微调成功的基础。常用的预训练模型包括 BERT、GPT-3 等。根据任务需求设置微调参数,包括学习率、训练轮次和批处理大小等。
在微调过程中,加载预训练的模型和权重,并根据任务需求对模型进行必要的修改。选择合适的损失函数和优化器,使用选定的数据集进行微调训练。
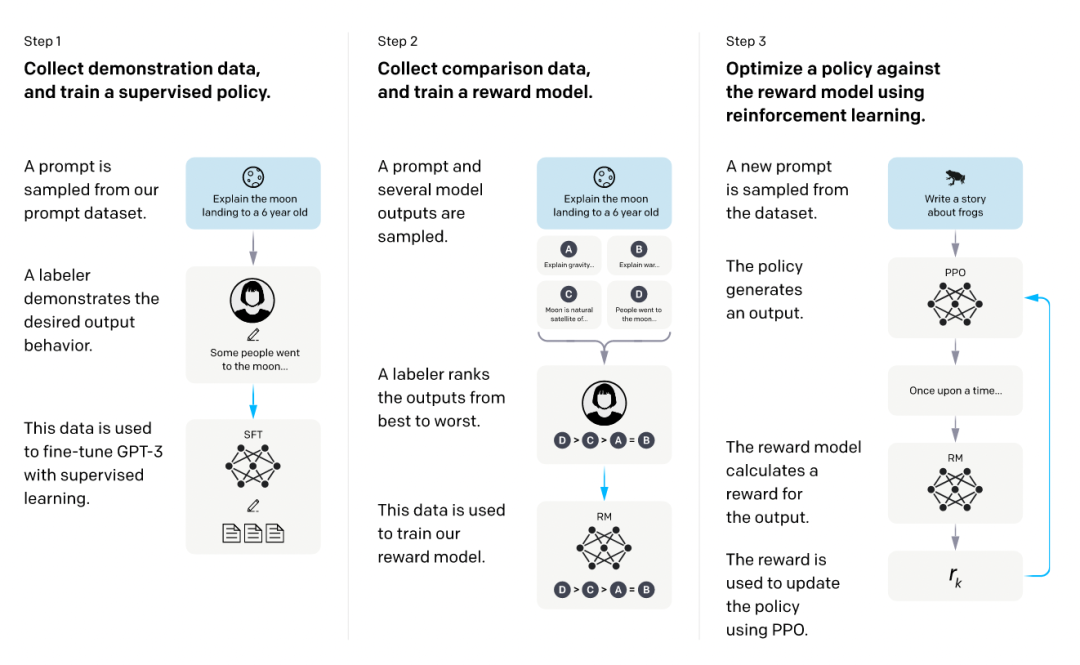
强化学习结合人类反馈(RLHF)是一种利用人类反馈作为奖励信号来训练强化学习模型的方法。通过这种方法,模型能够更符合人类的偏好,提高文本生成的质量。
在这个过程中,首先使用监督数据微调语言模型,然后训练奖励模型评估文本质量。最终,通过强化学习训练,模型在生成文本时能够更好地符合人类的期望。
微调技术在多个领域得到了广泛的应用。通过全量微调和参数高效微调(PEFT),模型可以适应不同的任务需求,达到更高的性能表现。全量微调适用于需要充分利用预训练模型通用特征的场景,而PEFT则适用于资源有限的情况。
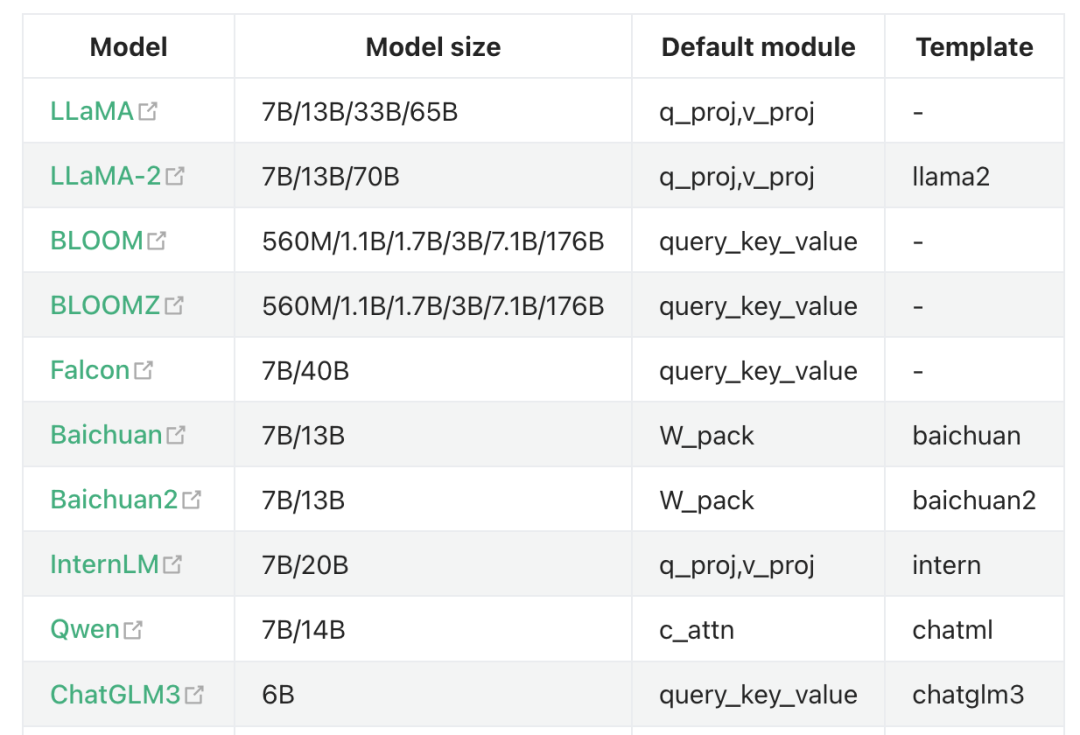
支持微调的模型众多,包括BERT、GPT-3等。而数据集则是微调成功的关键,常用的数据集包括中文问答、情感分析、文本相似度和摘要生成等。
LLaMA-Factory 是一个全栈微调工具,支持海量模型和多种主流微调方法。通过这个工具,用户可以进行快速实验和模型验证,显著提高微调效率。
大模型微调是一个复杂但必要的过程,通过选择合适的微调方法和工具,结合合理的数据集和超参数设置,可以显著提升模型在特定任务上的表现。未来,随着微调技术的不断发展,其应用范围和效果将更加广泛和深入。
问:什么是大模型微调?
问:微调过程中需要注意哪些超参数?
问:有哪些常用的微调平台?







