

中文命名实体识别(Named Entity Recognition, NER)初探

语音识别技术在现代生活中占据了重要的位置,它不仅能提升许多工作的效率,还为用户提供了更便捷的交互体验。为了在没有网络的情况下也能够进行语音识别,我们推出了基于C#开发的离线语音识别工具。这款工具可以精准地将短语音转换为文字,特别适用于需要快速语音转文字的场景。

本项目利用了C#语言在Windows平台上的高效性和易用性,通过本地化的语音识别库实现离线语音识别,从而避免了网络延迟和不稳定性的问题。我们优化了识别算法,以提高识别速度和响应时间,让用户能够快速获得准确的文字输出。
语音识别的核心在于将声音信号转换为文本信息,这需要处理信号的采集、分析和转换。这一过程包括特征提取、声学模型匹配和语言模型的结合。在我们的工具中,这些步骤都在本地完成,以确保数据的安全性和处理的高效性。
C#作为一种面向对象的编程语言,具有强大的库支持和易于调试的特性,使得开发高效的桌面应用程序变得更加简单。利用C#,开发者可以轻松调用Windows API,进行底层的音频处理和数据管理。
在会议场景中,传统的记录方式效率低且容易遗漏重要信息。我们的工具可以实时将会议发言转换为文字记录,便于后期整理和分析。这不仅提高了记录的准确性,还为记录员节省了大量时间。
通过语音输入生成文字笔记,可以极大地提高记录效率。特别是在快节奏的工作环境中,语音转文字的功能让记录工作变得轻松而高效。
在教育场景中,教师可以使用语音识别工具将课堂讲解内容转换为文字,这不仅有助于学生的复习,还可以作为教学资料归档,方便未来的教学调整和改进。
对于某些需要语音命令控制的嵌入式系统或应用,离线语音识别工具可以在没有网络连接的情况下完成命令的识别和执行,增强了系统的独立性和可靠性。
离线识别无需网络连接即可完成,确保了用户数据的安全性和隐私保护。用户不必担心网络中断带来的识别失败,从而提高了工具的可靠性。
我们的工具专门针对短语音进行了优化,能够在极短的时间内完成识别任务。这种优化使得它非常适合需要快速响应的应用场景,如实时翻译和语音控制。
工具支持用户根据自己的需求配置识别库。这种灵活性使得用户可以根据不同的应用场景调整识别参数,确保最佳的识别效果。
我们的项目经过多次优化,识别速度快,响应迅速,即使在高负荷的情况下,也能提供准确的文字输出。这种特性使得工具在实际应用中获得了用户的一致好评。
我们非常欢迎开发者们贡献代码、提出改进建议或报告问题。您可以通过GitHub的Issue或Pull Request功能与我们进行交流。我们期待与您共同完善这款工具,让其在更多场景中发挥作用。
本项目采用开源许可证,具体信息请查看项目中的LICENSE文件。
对于需要在线语音识别的场景,我们可以使用Microsoft Azure的语音识别服务。Azure提供了一套强大的API,可以进行实时语音转文字。
首先,用户需要有一个Microsoft Azure账号,并创建语音服务资源。在Azure门户中创建资源后,可以获取服务密钥和区域信息。这些信息将用于配置语音识别服务。
在项目中引用Azure Cognitive Services的语音识别库是实现在线语音识别的第一步。用户可以通过NuGet包管理器,搜索并安装Microsoft.CognitiveServices.Speech包。
以下是一个简单的代码示例,演示如何使用Azure语音服务进行语音转文字:
using Microsoft.CognitiveServices.Speech;
// 初始化语音配置
var config = SpeechConfig.FromSubscription("YourSubscriptionKey", "YourRegion");
// 创建语音识别器
using var recognizer = new SpeechRecognizer(config);
// 开始识别
var result = await recognizer.RecognizeOnceAsync();
// 输出结果
Console.WriteLine(result.Text);Azure的优势在于其强大的云计算能力和高准确率的识别结果,适合需要大量语音处理的场景。
Whisper是一款支持多语言的语音转文字工具,不仅可以处理视频和音频文件,还支持实时语音的自动采集和录制。它支持多种输出格式,包括纯文本、带时间戳的文本、字幕格式等。
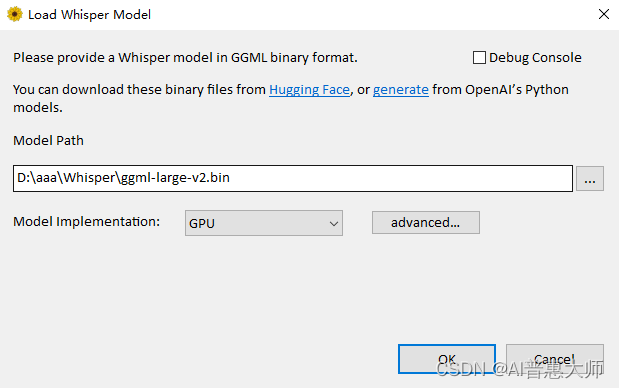
在使用Whisper之前,需要先下载并配置语言模型。用户可以通过提供的链接下载模型文件,配置简单,使用方便。
用户可以选择要转换的视频或音频文件,设置输出格式,然后开始转换。支持的格式包括纯文本、带时间戳的文本、字幕等,满足不同的应用需求。

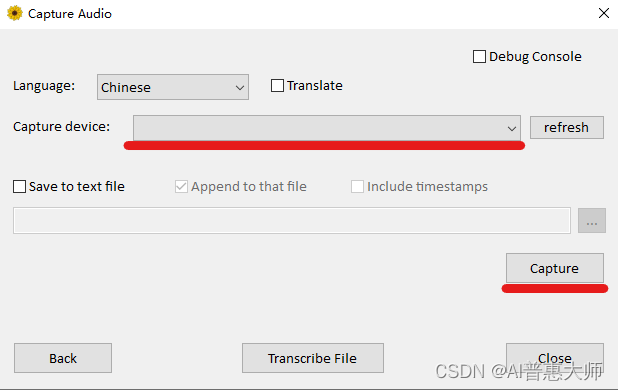
用户可以通过选择麦克风设备进行实时语音采集,工具会自动记录并转换为文字。
为了提高语音转文字的准确性,用户可以优化音频的质量,使用高质量的麦克风设备,或者通过配置更适合的语言模型来提高识别效果。
离线语音识别工具可以在本地完成所有的识别过程,无需将数据上传到云端,这大大提高了数据的安全性和隐私保护。
选择合适的语音识别工具需要考虑应用场景、语音文件的类型、需要的功能(如支持的格式、语言、实时处理等)以及工具的易用性和扩展性。
语言模型是语音识别系统中用于理解和处理自然语言的核心组件。它通过分析和预测文字序列,帮助提高语音识别的准确度。
C#语音识别工具主要针对Windows平台进行优化,但通过使用.NET Core等跨平台技术,部分功能也可以在其他平台上实现。用户可以根据具体需求进行调整和开发。






