

文心一言写代码:代码生成力的探索

基于LangChain与文心一言的检索增强生成(RAG)技术是一项结合检索与生成的创新自然语言处理技术,能够通过检索相关信息为生成模型提供辅助,提升文本生成的质量和准确性。本文将深入探讨这一技术的核心原理、应用案例及未来发展潜力。
RAG技术通过结合检索与生成两种NLP任务,利用向量数据库的高效存储和检索能力,召回目标知识,同时通过大模型和Prompt工程,将召回的知识合理利用,生成目标答案。
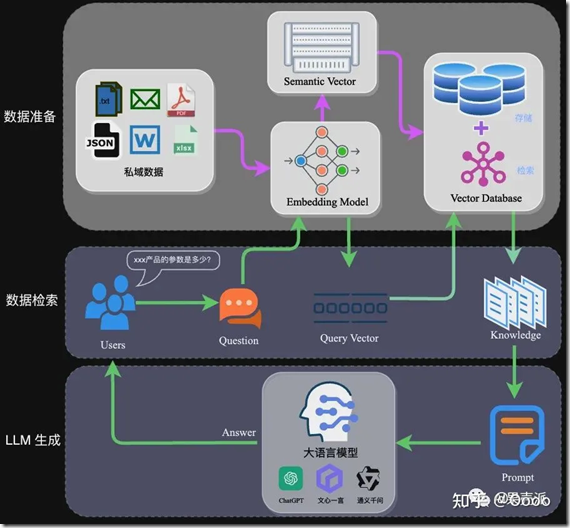
RAG的架构如图中所示,完整的RAG应用流程主要包含两个阶段:
数据准备是RAG技术的基础,主要包括数据提取、文本分割、向量化等步骤。数据提取阶段,需从多个数据源加载数据,并进行格式化处理,以适应统一的处理框架。
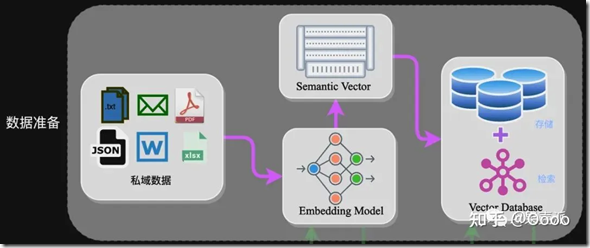
文本分割时需考虑embedding模型的Tokens限制和语义完整性。常用分割方式有句分割和固定长度分割。
向量化是将文本数据转化为向量矩阵的过程,影响后续检索效果。常用的embedding模型包括ChatGPT-Embedding、ERNIE-Embedding V1等。
在应用阶段,通过高效的检索方法召回与提问相关的知识。常用方法有相似性检索和全文检索。
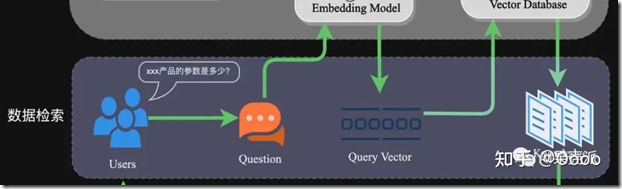
Prompt是影响模型输出准确率的关键因素之一。RAG场景中的Prompt一般包括任务描述、背景知识、任务指令等。

在实验中,通过LangChain和文心一言的结合,优化检索策略,提高检索效率和准确性,引入注意力机制提升生成模型的输出一致性。
利用RAG技术对民法典进行分析,加快对复杂法律条文的理解,提升法律咨询的效率和准确性。
展望未来,基于LangChain与文心一言的RAG技术将在多个领域发挥重要作用,如智能问答系统、内容创作和教育领域。
问:RAG技术有哪些应用场景?
问:如何提高RAG系统的检索效率?
问:RAG技术如何确保生成文本的准确性?
问:RAG技术在个性化内容生成中有哪些潜力?
问:未来RAG技术的发展方向是什么?
总之,基于LangChain与文心一言的检索增强生成(RAG)技术为自然语言处理领域带来了新的发展机遇,通过深入挖掘其技术潜力并不断拓展应用场景,我们有望在未来看到更多创新性的NLP应用成果诞生。






