

快速高效的语音转文字工具:让语音转文字更简单

中文命名实体识别(Named Entity Recognition, NER),是一项在自然语言处理中至关重要的技术。它的核心任务是在文本中识别出具有特定意义的实体,例如人名、地名、机构名和专有名词等。对于信息提取、问答系统、句法分析、机器翻译以及面向Semantic Web的元数据标注等应用领域,NER都是不可或缺的基础工具。本文将详细探讨NER的技术原理、方法、工具以及未来挑战。
命名实体识别是自然语言处理中的一项关键任务,旨在从文本中提取出特定类型的实体。实体类型可以包括人名、地名、机构名等。NER的过程就是将文本中这些实体类型识别并进行标注的过程。
命名实体是特定类型实体的具体实例。比如,“人名”是一种实体类型,而“蔡英文”就是一种具体的“人名”实体。同样,“时间”是一种实体类型,而“中秋节”则是一种具体的“时间”实体。NER的目标就是从文本中识别和标注出这些具体的命名实体。
NER是一种序列标注问题,因此其数据标注方式遵循序列标注问题的方式。主要有以下几种方法:
BIOES是一种常见的数据标注方式,其中:
这种方式能够更准确地标注文本中的实体位置和类型。
IOB标注方式简单且常用,其中:
这种方式强调实体的开始和内部位置,适合用于简单的实体识别任务。
在NER任务中,主要有以下几种方法:
这种方法依赖预定义的规则和词典,通过匹配规则来识别实体。优势在于对特定领域的实体识别准确率较高,但缺乏灵活性,难以适应多样化和复杂的文本。
使用HMM、CRF等机器学习算法,通过训练数据学习实体识别的特征。相比于规则方法,机器学习方法具有更好的泛化能力和灵活性。
以BiLSTM-CNN-CRF、BERT等技术为代表,深度学习方法能够自动提取特征,减少对人工特征工程的依赖,同时具有更强的识别能力和适应性。
利用注意力机制和迁移学习等技术,如GPT-3.5、Llama等,能够在少量标注数据的情况下实现较好的识别效果,是未来NER技术发展的方向之一。
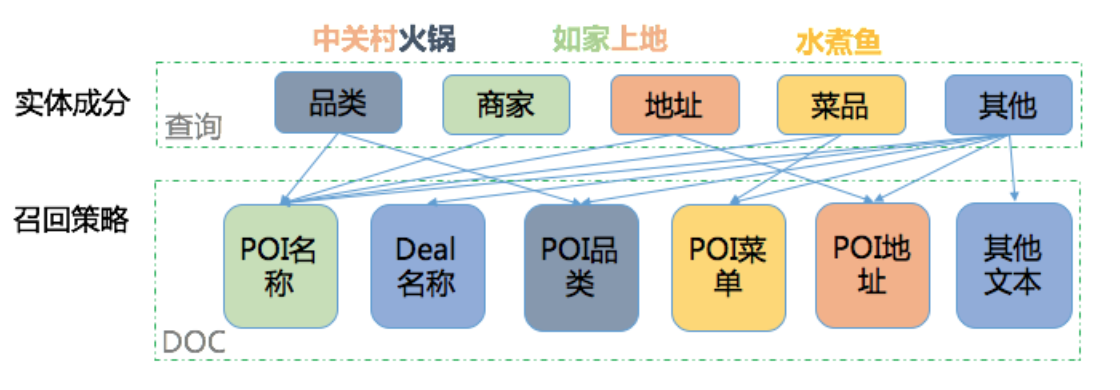
在搜索场景下,NER是深度查询理解(DQU)的底层基础信号,主要应用于搜索召回、用户意图识别、实体链接等环节。NER信号的质量直接影响到用户的搜索体验,是NLP中一项非常基础的任务。
在O2O搜索中,商家POI的描述包括商家名称、地址、品类等多个文本域。若对所有文本域进行全文检索,可能会产生误召回。通过NER技术进行结构化召回,只在商家名相关文本域检索,从而提高召回的准确性。例如,对于“海底捞”这样的查询,NER可以确保仅召回与海底捞品牌相关的商家,避免误召回。
市场上有多种NER工具可供使用,以下是一些常用工具的简介:
HanLP是由大快搜索主导的开源NLP工具包,支持命名实体识别,并提供了丰富的API接口。
pip install pyhanlp
HanLP提供了高效的中文分词功能,支持对文本进行分词处理。

可以通过API调用HanLP的各种功能,如关键词提取、自动摘要、依存句法分析等。
from pyhanlp import *
print(HanLP.segment('你好,欢迎在Python中调用HanLP的API'))
for term in HanLP.segment('下雨天地面积水'):
print('{}t{}'.format(term.word, term.nature))
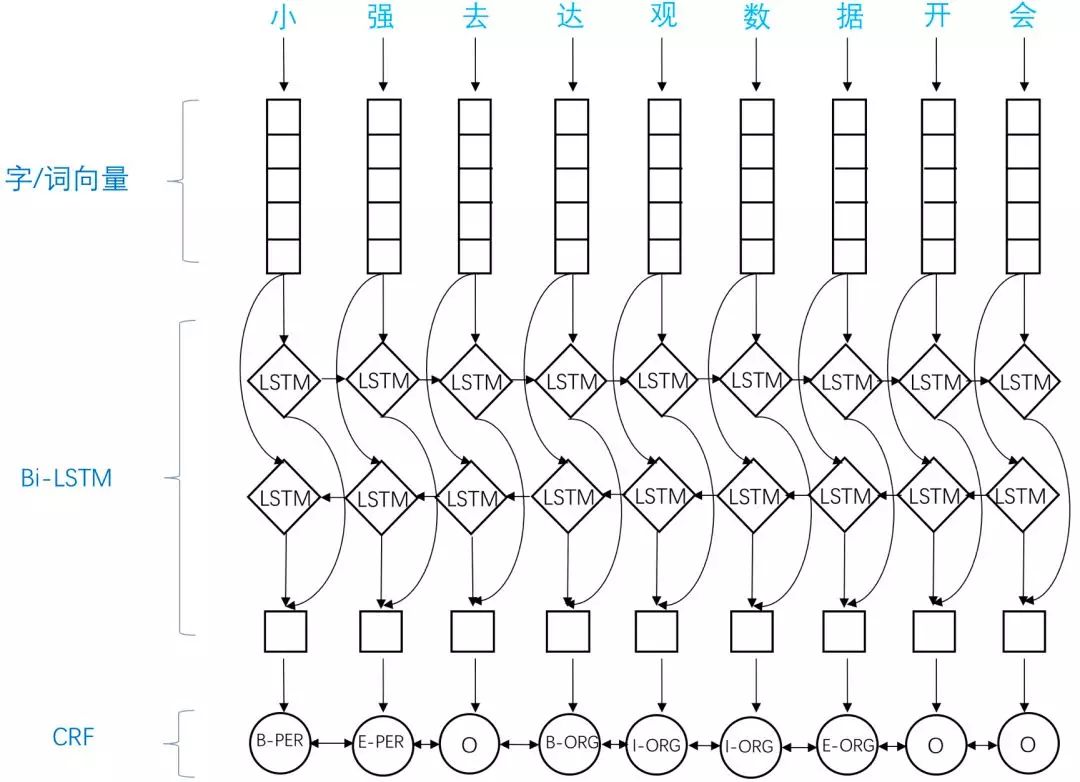
近年来,随着硬件计算能力的发展以及词的分布式表示(word embedding)的提出,神经网络可以有效处理许多NLP任务。BiLSTM-CRF模型是目前基于深度学习的NER方法中的最主流模型。
BiLSTM-CRF模型主要由Embedding层、双向LSTM层以及CRF层构成,实现了端到端的NER任务处理。
以下是一个简单的命名实体识别模型示例:
from tensorflow.keras.layers import *
from tensorflow.keras.models import *
model = Sequential()
model.add(Embedding(16000, 256, input_length=80))
model.add(Bidirectional(LSTM(128, return_sequences=True), merge_mode="concat"))
model.add(Dense(128, activation='relu'))
model.add(Dense(9, activation='softmax'))NER技术在不断发展,但仍面临一些挑战:
命名实体识别(NER)是一种自然语言处理技术,旨在从文本中识别和标注具有特定意义的实体,如人名、地名、机构名等。
NER常用的标注方式包括BIOES和IOB等。这些标注方式用于标识实体的开始、中间、结束等位置。
NER广泛应用于信息提取、问答系统、机器翻译和搜索引擎等领域,是NLP的重要基础技术。
NER面临的主要挑战包括实体数量的不断增加、构词的灵活性以及类别的模糊性等。
常用的NER工具包括HanLP、Stanford NER、NLTK等,这些工具提供了丰富的API和功能支持。






