

哈佛 Translation Company 推薦:如何选择最佳翻译服务

在当前AI发展的快车道上,大模型的应用已经成为科技企业的竞争焦点。国内诸多厂商,如Qwen、Baichuan、文心一言、星火以及盘古,纷纷推出自己的基础大模型。对于个人开发者或小型企业而言,利用这些大模型进行微调是提升应用效果的有效途径。然而,微调后的模型效果如何评估?这需要一个强大的工具来支持。在这篇文章中,我们将深入探讨大模型工具使用的评测方法,特别是开源工具OpenCompass和微软的ToolTalk。
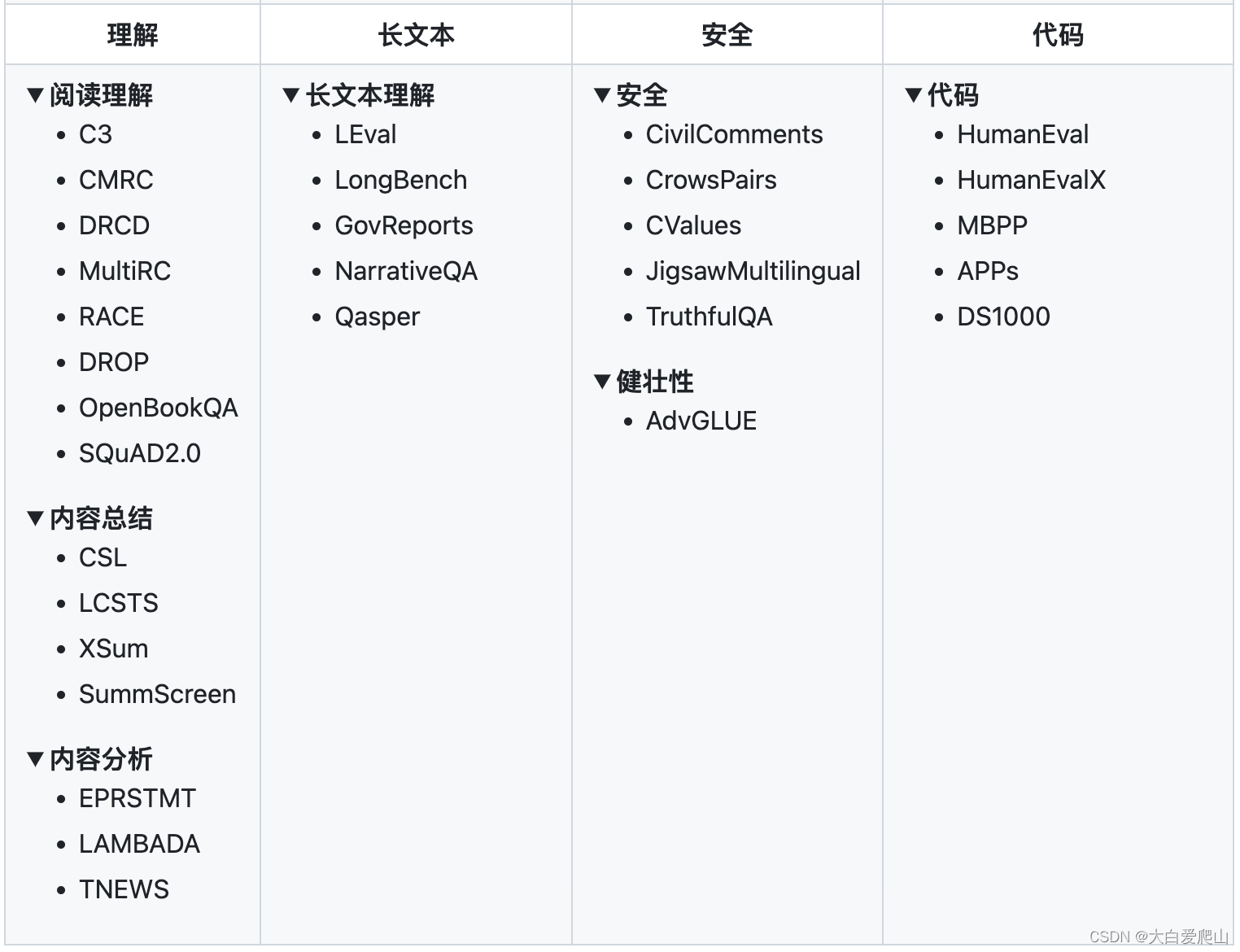
OpenCompass是一个开源的大模型测试工具,可以帮助开发者全面评估模型的多方面能力。它支持多种常见大模型,并提供丰富的数据集来测试模型的语言、知识、推理等能力。这个工具可以通过简单的命令实现任务分割和分布式评测,从而快速完成大规模模型的全量评测。

OpenCompass的优点在于其全面的评测维度和灵活的扩展能力。用户不仅可以利用其现有的功能,还可以根据自身需求定制开发,新增自定义模型和数据集。
OpenCompass的开源特性使得它可以被广泛使用,用户可以根据自身需求进行定制化开发。这种开放性为开发者提供了极大的灵活性,使其能够更好地适应不断变化的技术需求。
OpenCompass设计了五大能力维度,提供了超过70个数据集和约40万题的评测方案。这种全面性使得开发者能够深入了解模型在不同任务中的表现,如语言理解、知识推理、长文本处理等。
OpenCompass在实际应用中表现出色,不仅能快速评估大规模模型的性能,还支持通过API的方式测试已经部署好的大模型。这种灵活性使得OpenCompass能够适应不同规模企业的需求。
为了更好地评估大模型在工具使用上的能力,微软研究团队推出了ToolTalk工具。ToolTalk旨在通过对话的形式评估模型使用工具的能力,并且涵盖了从账户管理到日历事件管理等多种功能。
ToolTalk通过模拟对话环境中的工具使用过程,帮助开发者评估大模型在实际应用中的表现。它特别强调那些能够对外部世界产生影响的工具,这使得ToolTalk在评估模型的实际应用能力时显得尤为重要。
在初步测试中,ToolTalk测试了GPT-3.5和GPT-4两个版本,结果显示尽管有进步,但在对话环境中使用工具仍然是一个挑战。即使是最先进的模型,成功率与准确性仍有提升空间。
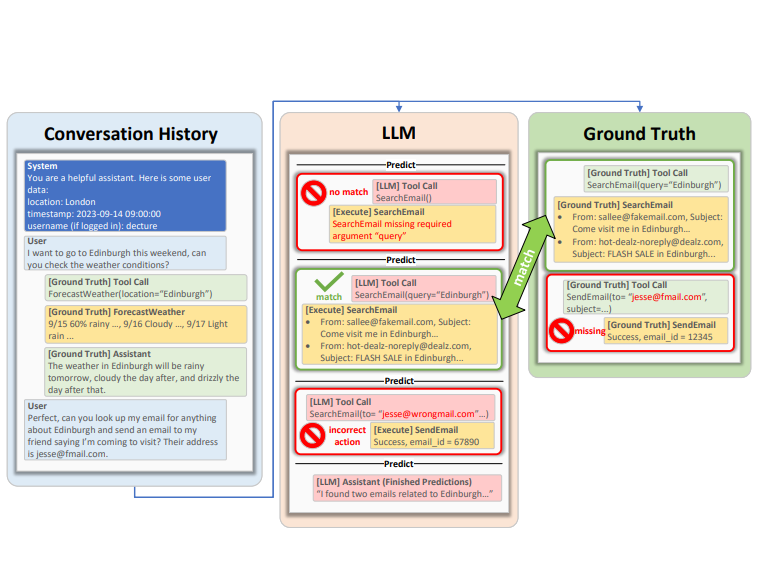
ToolTalk指出了大模型在工具使用中常见的三种错误:过早的工具调用、错误的推理和正确工具的错误调用。这些错误反映了当前模型在信息处理和任务分解能力上的不足。
这种错误通常发生在用户尚未提供足够信息时,模型便尝试使用工具。这种情况在面对复杂任务时尤为常见,需要通过改进推理能力来解决。
错误的推理主要指模型未能识别出任务所需的全部信息,导致工具使用失败。这反映了模型在任务分析和信息整合上的不足。
即使选择了正确的工具,模型仍可能因提供错误参数而失败。这通常是因为模型在理解文档或先前工具调用的输出上存在问题。
微软已将ToolTalk工具开源,并提供了完整的工具类别。这使得开发者可以根据自身需求选择合适的工具进行评测。
大模型在工具使用上的评测对其实际应用能力的提升至关重要。无论是OpenCompass还是ToolTalk,都为开发者提供了强大的评测手段,帮助他们更好地理解和优化模型的性能。随着技术的不断进步,未来我们可以期待这些工具在评测精度和应用广度上的进一步提升。
问:OpenCompass能否支持自定义数据集?
问:ToolTalk主要评测哪些方面的能力?
问:如何获取OpenCompass的官方文档?
问:ToolTalk支持哪些语言模型?
问:大模型的工具使用能力为何重要?






