

DeepSeek Janus-Pro 应用代码与图片链接实践

Nvidia的eDiff-I是生成性人工智能领域的一项创新,它被描述为“新一代生成性人工智能内容创作工具,能够提供前所未有的文转图功能”。eDiff-I的开发者在他们的论文中指出,当前的图像合成算法通常依赖于文本提示来创建与文本完全对标的信息,而文本调节几乎完全被忽略。这导致人们意识到,与其在整个生成过程中共享模型参数,可能有更好的方法来表示生成过程的这些模型。
Nvidia的研究团队建议训练一个专门用于不同合成阶段的文转图扩散模型集合。eDiff-I的图像合成管道由三个扩散模型组成:一个低分辨率扩散模型,可以合成64 x 64分辨率的样本,以及两个高分辨率扩散模型,可以分别将图像逐步上采样到256 x 256和1024 x 1024分辨率。这些模型首先通过计算其T5 XXL嵌入和文本嵌入来处理输入的文本。eDiff-I的模型架构还利用了从参考图像计算出来的CLIP图像编码。这些图像嵌入作为风格矢量送入级联扩散模型,逐步生成分辨率为1024 x 1024的图像。

这种独特的步骤使eDiff-I对其生成的内容有更强的控制。除了将文本生成图像外,eDiff-I模型还有两个功能——风格转移,允许使用参考图像的风格来控制生成的图案的风格,以及“用文字绘画”,用户可以通过在虚拟画布上绘制分割图来创建图像,这个功能对于用户创建特定场景的图像非常方便。
扩散模型的合成通常是通过一系列迭代去噪过程进行的,这些流程通过随机噪音逐渐生成图像,在整个去噪过程中使用同一个去噪器神经网络。eDiff-I模型采用了另一种独特的去噪方法,该模型在生成过程的不同时期内训练专门用于去噪的去噪器集合。Nvidia将这种新的去噪网络称为“专家级去噪器”,并称这一过程极大地提高了图像生成的质量。
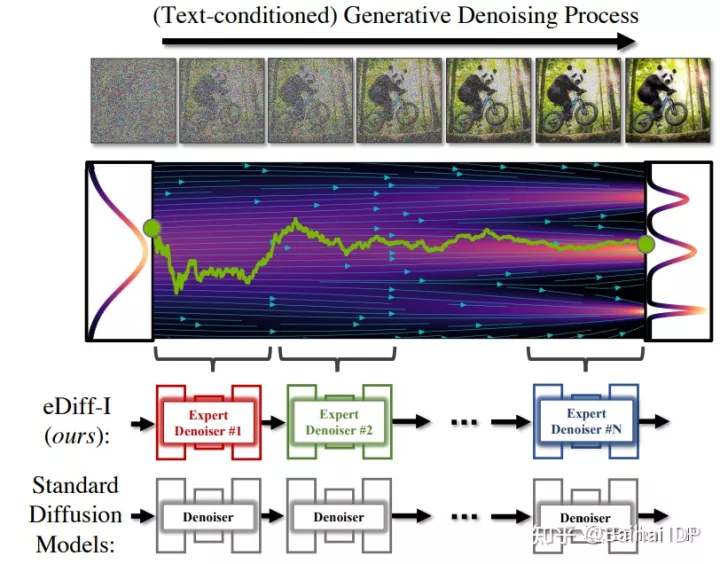
Deepgram的首席执行官Scott Stephenson表示,eDiff-I提出的新方法可以被运用到DALL-E或Stable Diffusion的新版本中,使合成图像在质量和控制能力方面取得重大进步。Stephenson指出,这肯定会增加训练模型的复杂性,但在生产使用过程中并没有明显增加计算的复杂性。能够分割和定义所产生的图像的每个组成部分的样子,可以加速图像创作过程。这种方法能让人和机器更加紧密地合作。
与其他同时期的产品如DALL-E 2和Imagen只使用单一的编码器(如CLIP或T5)不同,eDiff-I的架构在同一模型中使用两个编码器。这样的架构使eDiff-I能够从相同的文本输入中产生大量不同的视觉效果。
CLIP为创建的图像提供了风格化的效果,然而,输出的图像经常遗漏文本信息。而使用T5文本嵌入创建的图像可以根据文本信息产生更好的内容。通过结合它们,eDiff-I产生了集成这两种优点的图像。

开发团队还发现,文本信息的描述性越强,T5的表现就越比CLIP好,而且将两者结合起来会产生更好的合成输出。该模型还在标准数据集(如MS-COCO)上进行了模型评估,表明CLIP+T5的trade-off曲线明显优于单独的任何一种。根据Frechet Inception Distance(FID)——这是一种评估人工智能生成的图像质量的指标,eDiff-I的表现优于DALL-E 2、Make-a-Scene、GLIDE和Stable Diffusion等竞争对手。

Nvidia的研究称,在对简单和详细的文字说明生成的图像进行比较时,DALL-E 2和Stable Diffusion都未能根据文字说明准确合成图像。此外,该研究发现,其他生成模型要么会产生错误的信息,要么忽略了一些属性。同时,eDiff-I可以在大量样本基础上正确地从英文文本中建立特征模型。
当下文转图的扩散模型可能使艺术表达大众化,为用户提供了产生细致和高质量图像的能力,而不需要专门技能。然而,它们也可以被用于进行照片处理,以达到恶意目的或创造欺骗性或有害的内容。
生成模型和AI图像编辑的最新研究进展对图像的真实度和其他方面有着较大的影响。Nvidia表示,可通过自动验证图像真实性和检测伪造的内容来应对此类挑战。
目前大规模文转图生成模型的训练数据集大多未经过滤,可能包含由模型捕获并反映在生成数据中的偏差。因此,需要意识到基础数据中的这种偏差,并通过积极收集更具代表性的数据或使用偏差校正方法来抵消偏差。
Stephenson指出,生成式人工智能图像模型面临着与其他人工智能领域相同的伦理挑战:训练数据的出处和理解它如何被用于模型中,大的图像标注数据集可能包含受版权保护的材料,而且往往无法解释受版权保护的材料是如何(或是否)被应用在最终生成出来的图像的。
reVolt公司的创始人兼首席执行官Kyran McDonnell表示,尽管现在的文转图模型已经做得特别好,但还是缺乏必要的架构来构建正确理解现实所需的先验条件。他说:“有了足够的训练数据和更好的模型,生成的图像将能够近似于现实,但模型还是不会真正理解生成的图像。在这个根本问题得到解决之前,我们仍然会看到这些模型犯一些常识性错误。”
McDonnell认为,下一代文转图的架构,如eDiff-I,将解决目前的许多问题。他还说:“仍然会出现构图错误,但质量将类似于现在生成人脸的GANs,我们会在几个应用领域看到生成式AI的更多应用。根据一个品牌的风格和‘氛围’训练出来的生成模型可以产生无限的创意,企业应用的空间很大,而生成性式AI还没有迎来它的‘辉煌时刻’。”

问:eDiff-I与其他文转图模型有何不同?
问:eDiff-I在图像生成质量上有什么优势?
问:生成式AI在应用中面临哪些挑战?
问:未来的生成式AI发展方向是什么?
问:如何提高生成模型的训练数据质量?






