

文心一言写代码:代码生成力的探索

在软件开发和人工智能领域,代码大模型的快速发展已经成为推动技术进步的重要力量。字节跳动的豆包大模型团队近日发布了最新的代码评估数据集——FullStack Bench,以及一款名为 Doubao Marscode 的工具。这些创新在全栈编程和多语言编程中提供了新的视野和工具,推动了代码智能领域的进一步发展。
FullStack Bench 是一个用于评估大型语言模型在多种实际代码开发场景中的能力的开源数据集。该数据集覆盖了11种真实编程场景和16种编程语言,包含了3374个问题。这些问题旨在测试模型在真实世界中的代码开发能力,为代码智能领域提供了一个全面的评估工具。

FullStack Bench 的出现填补了目前代码评估基准在多领域多语言覆盖上的空白,使得评估更加全面和真实。它集成了从基础编程到高级编程、数据分析等多种任务类型,通过多语言支持提高了评估的全面性。
为了支持 FullStack Bench 的多语言评估需求,豆包大模型团队开发了 SandboxFusion,一个支持23种编程语言的高效代码沙盒环境。SandboxFusion 允许开发者在不同的应用场景中进行代码测试,确保代码的执行安全性和资源使用的有效控制。
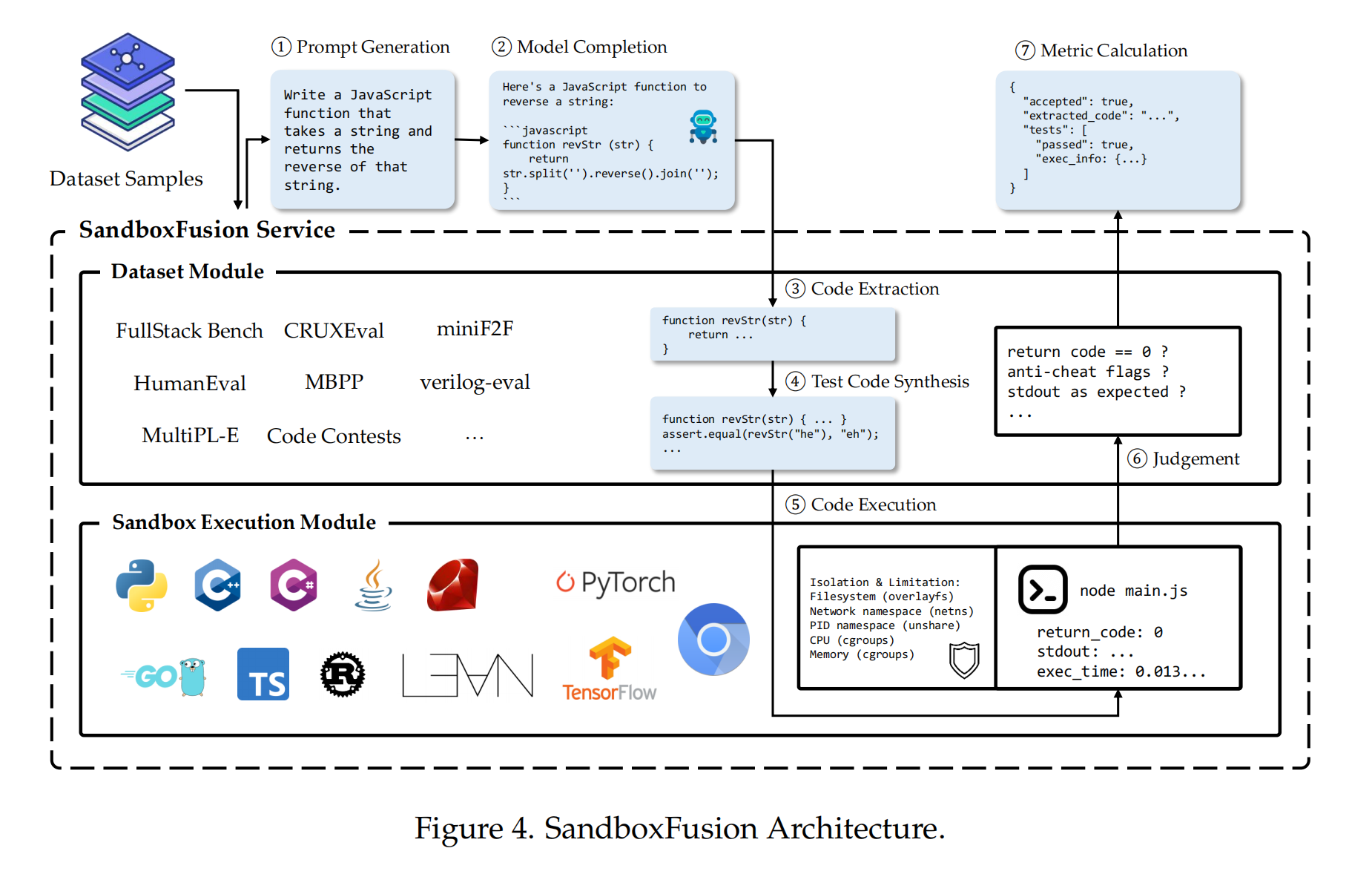
SandboxFusion 的设计目的是为了提供一个标准化的测试环境,开发者可以轻松地在本地服务器上部署并进行测试。同时,它也支持通过 GitHub 进行在线体验,极大地方便了开发者的使用。
字节跳动推出的 Doubao Marscode 是一款具有代码完成功能的工具,通过机器学习算法和自然语言处理技术,该工具能够理解开发者的意图,并提供精准的代码建议。这种功能大大提升了开发者的工作效率,同时减少了代码编写中的错误。

Doubao Marscode 的兼容性和可扩展性使得它可以与多种编程语言和开发环境集成,满足不同开发者的需求。字节跳动还计划持续优化和升级该工具,以应对市场和技术的变化。
在 FullStack Bench 的评测中,豆包大模型团队对20余款代码大模型和语言大模型进行了测试。结果显示,闭源模型在解决复杂问题上通常优于开源模型,但开源模型在特定领域也展现了强大的竞争力。
跨领域的评测显示,数学编程领域的差异最大,OpenAI o1-preview 表现最佳。这表明,模型的训练需要涵盖更广泛的语料库以提高其在不同领域的表现。
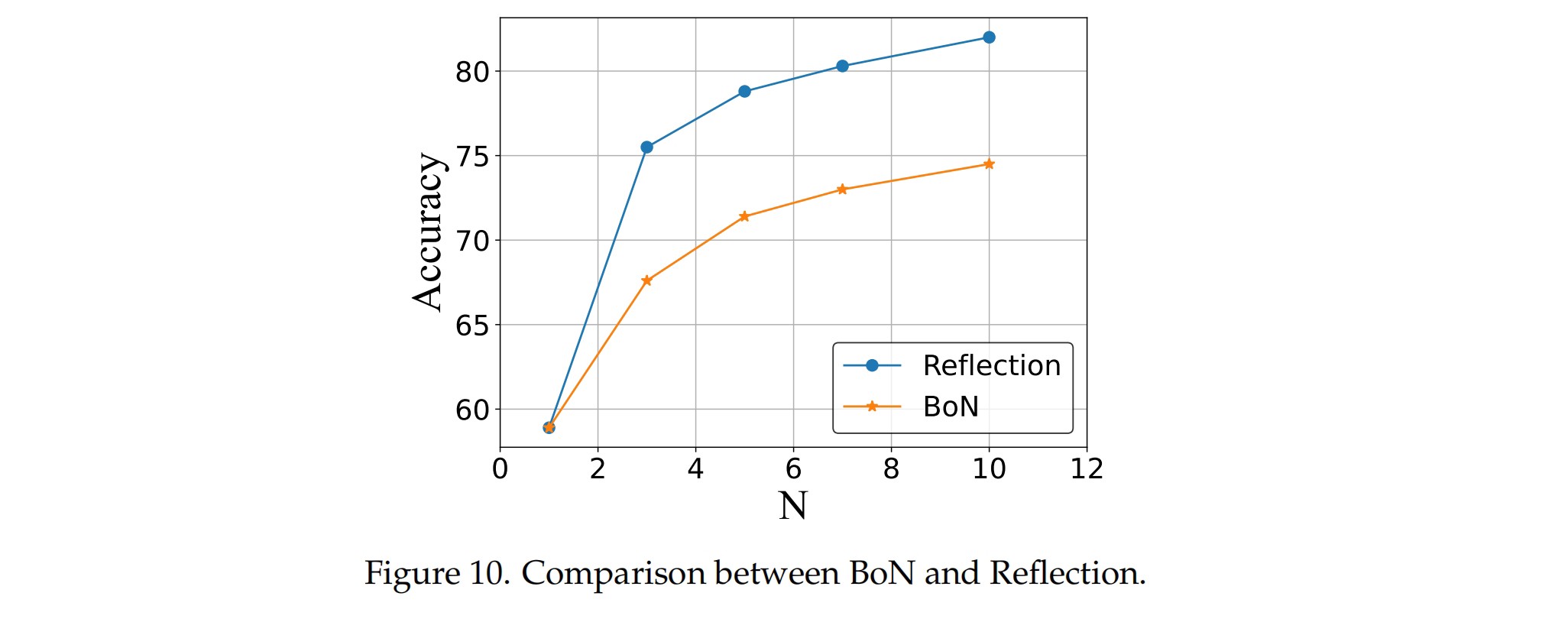
使用 SandboxFusion 进行代码反馈可以显著提升模型的表现。通过“Reflection”策略,开发者可以利用 SandboxFusion 的反馈来反复优化模型输出,提高代码精确度。这一过程展示了 SandboxFusion 在帮助模型提升解决问题的能力方面的有效性。
豆包大模型团队的这些新工具和数据集不仅推动了代码大模型的发展,也为解决大模型领域的复杂问题提供了新的思路。在未来,Doubao Marscode 以及 FullStack Bench 和 SandboxFusion 的结合有望在更多领域应用,为开发者提供更强大的支持。
答:FullStack Bench 通过涵盖多种编程语言和真实场景的问题集,测试大模型在实际代码开发中的表现能力。
答:SandboxFusion 提供了一个支持多语言的安全执行环境,允许开发者高效进行代码测试和评估。
答:通过机器学习和自然语言处理技术,Doubao Marscode 提供代码建议和自动完成功能,减少开发者的工作量并提高代码质量。
答:开源模型在解决复杂问题上通常不如闭源模型,但在特定领域表现优异,需要更广泛的训练数据以提高综合表现。
答:利用 SandboxFusion 提供的反馈机制,通过反复调整和优化模型的输出,可以提升模型在实际问题中的解决能力。





