

Phenaki API 价格:探索最新技术与市场趋势

本文深入探讨了豆包大模型作为API服务的各项能力和价格策略。通过对模型性能、易用性、安全性等多方面的测试和评估,分析豆包API接口在成本效益和功能上的优势。尤其关注豆包API的价格在市场上的竞争力及其参数设置的灵活性,为开发者提供了全面的参考。无论是个人开发者还是企业用户,都能从中了解到豆包API在实际应用中的潜力和限制。
豆包大模型的性能与能力评估首先取决于其参数规模和训练数据集的质量。这些因素直接影响模型的理解和生成能力。豆包使用了丰富的训练数据,涵盖了多种语言和知识领域,从而确保了其在处理复杂任务时的高效性和准确性。
上下文窗口长度是衡量大模型处理长文本能力的关键指标。豆包大模型支持多种上下文窗口设置,从4k到128k,为用户提供灵活的选择,适用于从简单对话到复杂文本处理的各种场景。
豆包系列包括文本模型、语音模型和向量化模型等多种类型,以满足不同行业和应用场景的需求。这些模型在功能上相辅相成,使得豆包可以在文本生成、语音合成、向量检索等方面表现出色。
豆包API提供了多种接入方式,包括直接API Key授权和火山引擎IAM授权,以满足个人开发者和企业用户的不同需求。API的灵活性和易用性使得开发者可以快速集成豆包的强大能力。
豆包提供详尽的API文档和多种语言的SDK支持,包括Python和Java等,确保开发者在接入和使用过程中能够获得完整的技术支持和指导。
豆包API的设计兼容OpenAI的标准,使得开发者可以轻松迁移现有应用,并利用豆包的特色功能进行扩展和优化,进一步提升应用的智能化水平。
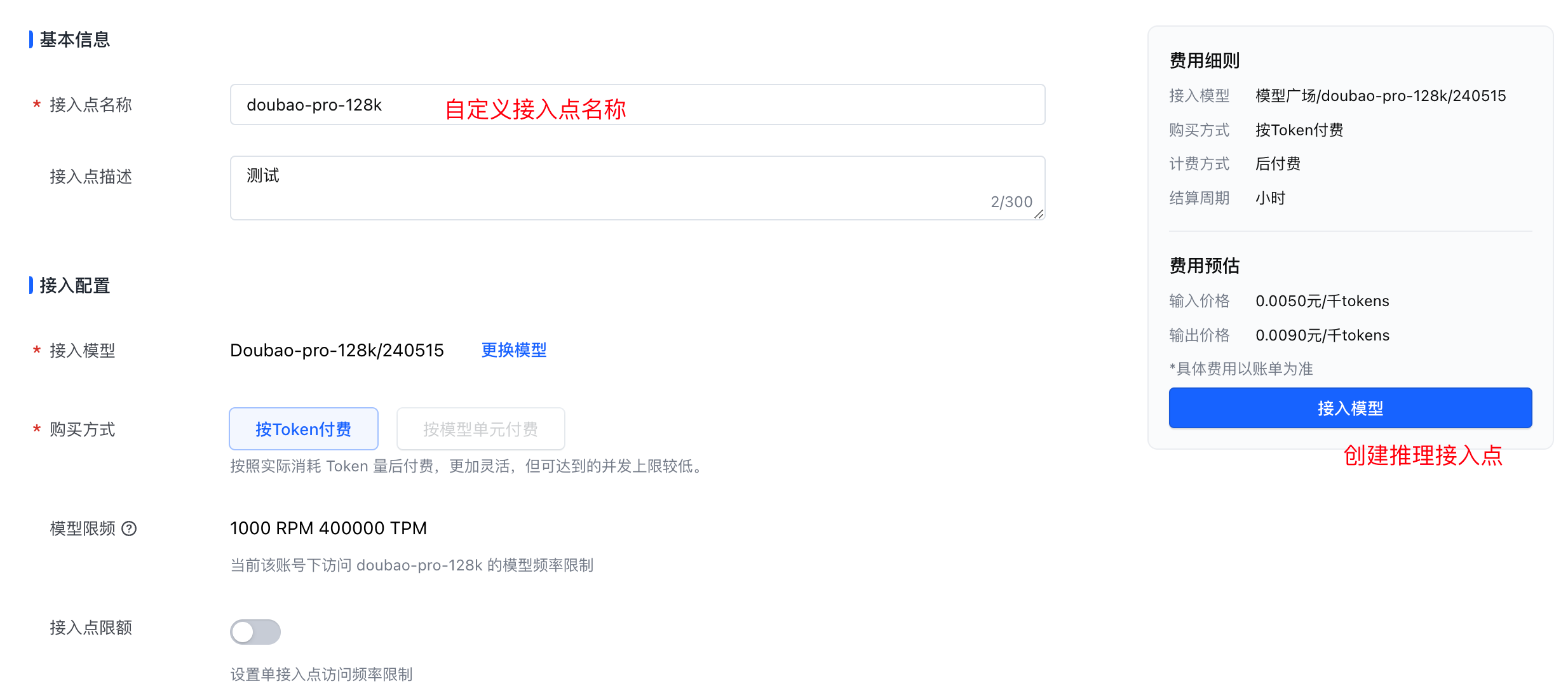
豆包模型的定价策略灵活多样,从最基础的0.3元每百万tokens到最高级别的9元每百万tokens不等,用户可以根据自身需求选择合适的方案,从而在控制成本的同时最大化利用模型能力。
豆包支持预付费和后付费两种模式。预付费用户可享受额外的折扣和服务,适合需要高并发和稳定保障的企业用户;后付费模式则提供了更高的灵活性,适用于大多数开发者。
相较于其他大模型,豆包的成本效益显著,特别是在长上下文和高并发场景下,能够以较低的价格提供优质的服务,是开发AI应用的理想选择。

豆包严格遵守数据隐私保护原则,默认情况下不会将用户数据用于模型训练,除非用户明确同意,这为用户的数据安全提供了坚实的保障。
豆包的使用需符合相关法律法规,用户在使用过程中应确保不违反国家法律和平台规定,火山引擎也会对使用行为进行审查,确保合规性。
豆包模型具备自动化内容审核能力,能够有效过滤不当内容,确保生成内容的安全性和合法性,为用户提供可靠的使用体验。
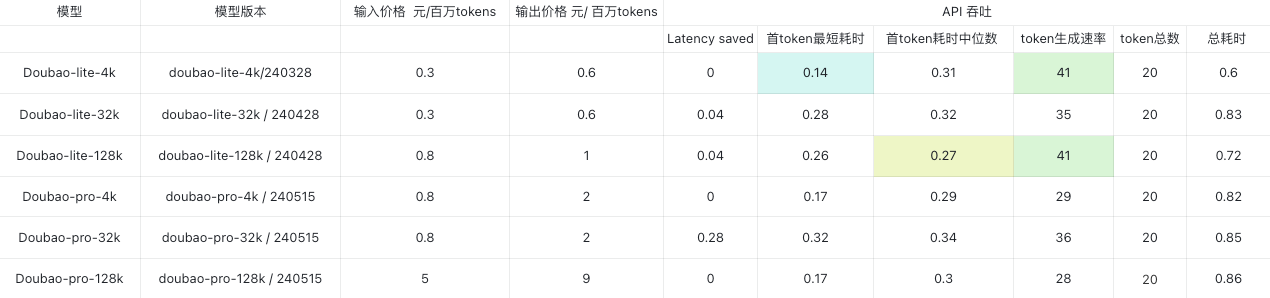
豆包API在高并发场景下表现优异,其高吞吐量使得在多用户同时请求时仍能保持快速响应,提升了用户体验和应用的实用性。
豆包API的响应时间极短,特别是在首token的响应速度上表现突出,能够在200毫秒内完成响应,适合对实时性要求高的应用场景。
在大规模测试中,豆包API展现了极高的稳定性,即便在峰值负载下,仍能保持服务的连贯性和可靠性,确保用户的持续高效使用。
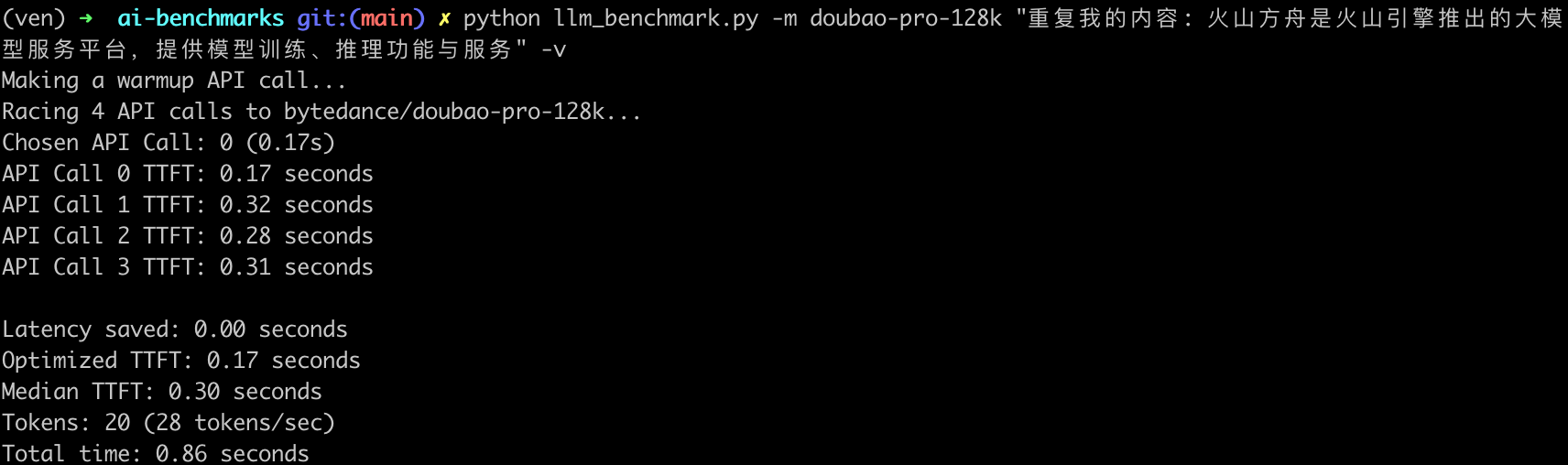
豆包的长上下文能力测试采用了“大海捞针”实验法,通过在长文档中插入随机信息并要求模型检索,以评估其在长文本处理上的性能表现。
测试结果表明,豆包在100K上下文窗口内能够有效检索信息,表现出色。虽然在更长的上下文中性能略有下降,但整体表现仍然优于许多同类产品。
尽管测试结果令人满意,但在极端长文本条件下,模型的准确性仍有提升空间。通过优化模型结构和训练数据,豆包的长文本处理能力将更进一步。
豆包的服务协议对内容合规、安全使用等方面作出了详细规定,用户在使用过程中需遵守相关法律法规,并承担相应责任,确保服务的合法合规性。
豆包服务不会在未授权情况下使用用户数据进行模型训练,用户数据的安全性得到了充分保障,只有在用户明确同意的情况下,才会被用于改进模型。
豆包的SLA条款确保了服务的高可用性和可靠性,尽管无法保证100%的无故障运行,但火山引擎承诺尽最大努力提供优质服务,并在必要时进行快速响应和处理。






