

Optuna使用详解与案例分析

扩散模型理论是一种基于概率扩散过程的生成模型,近年来在生成图像、文本和其他数据类型方面展现出巨大潜力。通过模拟粒子从高浓度向低浓度移动的过程,扩散模型能够从简单的噪声逐步生成复杂的数据样本。这种模型不仅能够生成高质量的图像,还在文本生成、医疗影像处理等领域提供了新的解决方案。它的核心创新在于利用逆过程生成数据,解决了传统生成模型在稳定性和训练效率上的挑战。
扩散模型的基础来源于物理学中的扩散过程,这是一种自然现象,描述了粒子在介质中从高浓度区域向低浓度区域的移动过程。在机器学习中,扩散模型通过模拟这一过程,将数据通过引入随机噪声逐步转化为噪声分布,然后通过逆过程逐步还原数据。这种方法能够生成高质量的数据样本,具有稳定的训练过程,避免了诸如生成对抗网络(GANs)中的模式崩溃问题。

概率扩散过程的数学基础涉及到随机过程和热力学方程。扩散模型在前向过程中将原始数据逐步转化为噪声,符合标准正态分布,通过一系列计算得出每个时间步长的数据分布。这种过程是通过马尔科夫链实现的,未来状态仅与当前状态有关,而与过去状态无关。在逆向去噪过程中,模型学习条件概率分布,以逐步去除噪声还原数据。
这些数学基础为扩散模型提供了理论支撑,使其能够通过多步骤迭代生成高质量的样本。通过合理设置噪声比例参数和时间步长,扩散模型能够有效地拟合复杂数据分布,应用于图像生成、文本生成等多个领域。
在扩散模型理论的发展过程中,出现了多种不同的扩散模型类型,每种模型在数据生成上都有其独特的机制和优点。以下我们将详细介绍去噪扩散概率模型(DDPM)和分数生成模型(Score-Based Models)。
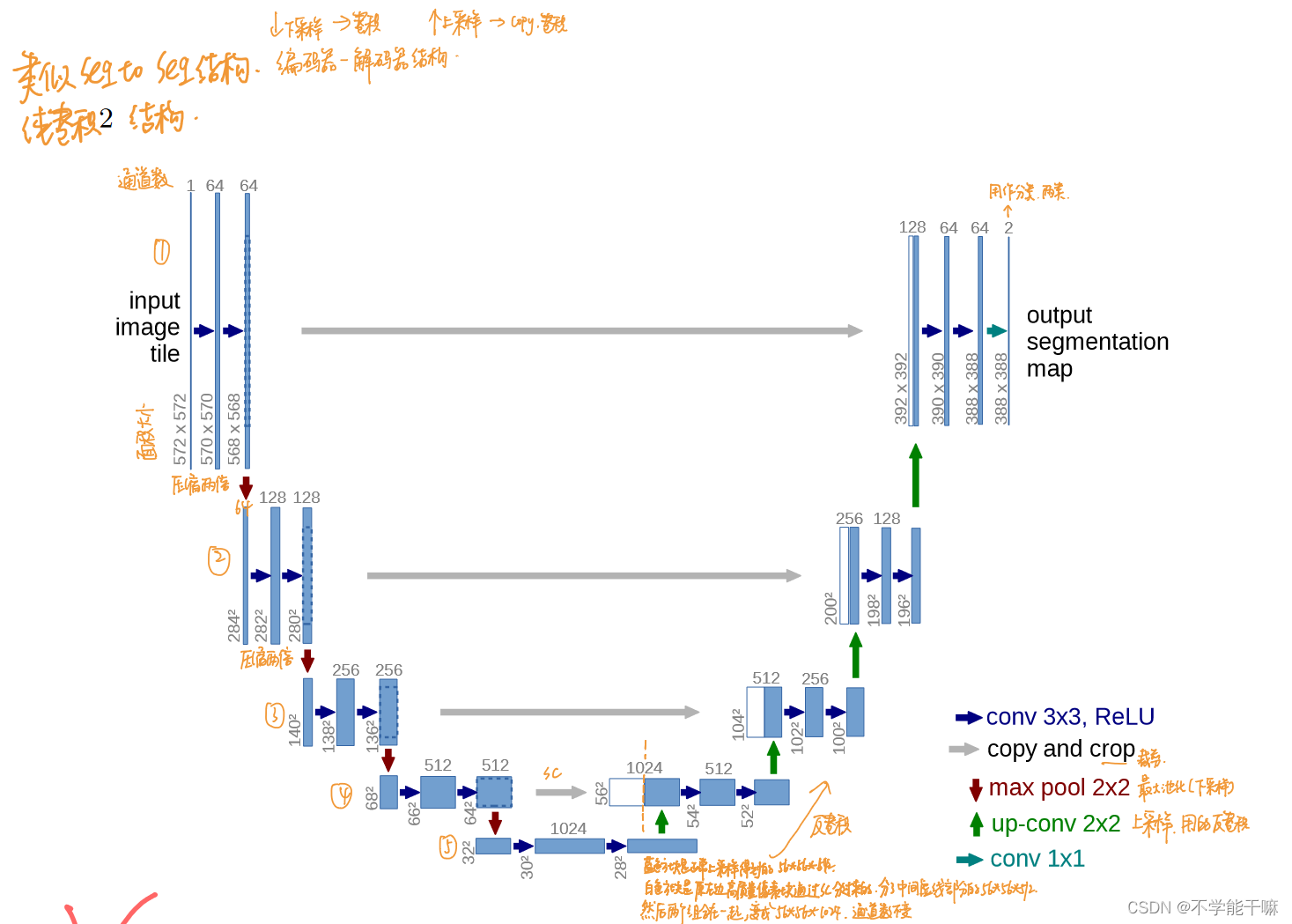
去噪扩散概率模型(DDPM)是扩散模型理论中的开创性工作。其核心思想是通过前向过程逐步向数据添加高斯噪声,使其逐渐趋向于标准正态分布,然后通过逆向去噪过程逐步还原数据。这个过程依赖于学习条件概率分布,使得模型能够高效地生成高质量的数据样本。
这张图片展示了DDPM的工作流程,显示了模型如何通过噪声逐步还原数据到原始状态。DDPM的优点在于其生成质量高且稳定性好,但其计算复杂度较高,需多步迭代。
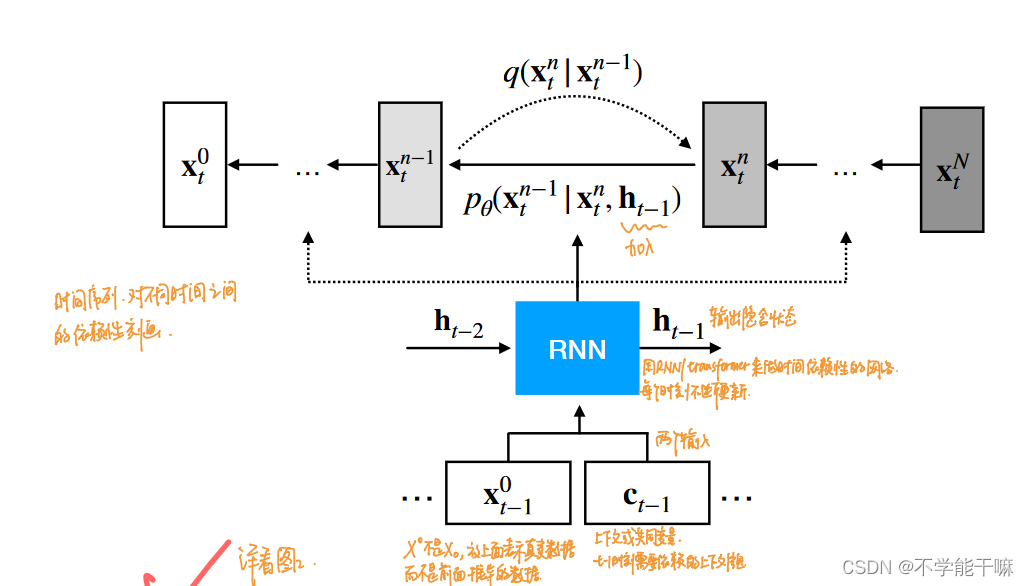
分数生成模型是扩散模型理论中的另一个重要分支,其通过学习数据的分数函数来指导数据的生成。该模型通过求解随机微分方程,结合分数网络来生成数据。

这张图展示了分数生成模型的基本流程。与DDPM不同,分数生成模型通过给数据添加不同量级的噪声进行训练,使得模型能够在各种噪声水平下生成高质量的数据。这一方法不仅提高了生成的多样性,还增强了模型对复杂分布的拟合能力。
在扩散模型的应用中,这两种模型各有其优势和适用场景。DDPM适合需要高保真度生成的任务,而分数生成模型更适合需要灵活控制生成过程的场景。通过对这两种模型的深入理解,可以更好地应用扩散模型理论于实际数据生成任务中。
扩散模型理论在数据生成方面展现了显著的优势,尤其是在生成高质量数据样本的能力上。通过逐步去噪的方法,扩散模型能够生成质量较高且逼真的样本。这种方法的核心在于其稳定的训练过程,相比于生成对抗网络(GANs),扩散模型避免了诸如模式崩溃等常见问题,从而在图像生成、文本生成等多个领域取得了优异的表现。
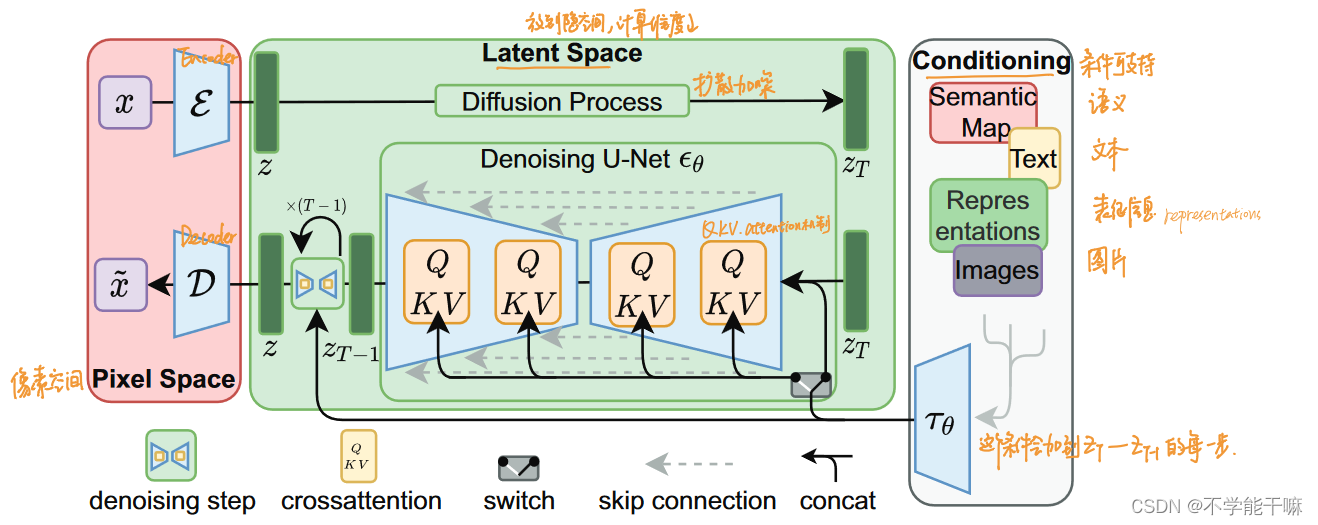
这张图片显示了扩散模型在高分辨率图像合成中的应用,通过在潜在空间对数据进行处理,模型可以实现更灵活的生成能力。
尽管扩散模型理论具备生成高质量数据的能力,但其主要挑战在于计算复杂度和模型优化。扩散模型需要多步迭代过程,这使得计算成本较高,训练时间较长。此外,逆过程的学习需要高效的优化算法,对参数设置相对敏感,增加了模型优化的难度。因此,如何在保证生成质量的同时降低计算复杂度和优化难度,仍然是扩散模型研究中的重要课题。
扩散模型在图像生成与修复领域展现了其强大的能力。通过利用扩散模型理论,这些模型可以生成高质量的图像,并有效地修复受损或降噪的图像。具体来说,扩散模型通过在前向过程中向数据添加噪声,并在逆向过程中逐步去噪,从而生成逼真的图像。这一过程不仅提高了生成的图像质量,还增加了模型的稳定性和鲁棒性。
在实际应用中,去噪扩散概率模型(DDPM)和分数生成模型(Score-Based Models)是两种主要被采用的扩散模型类型。DDPM通过逐步去除噪声来还原数据,而分数生成模型则通过学习数据的分数函数来引导生成过程。这些模型在图像合成、图像修复、超分辨率以及去噪等任务中应用广泛,并且在生成图像的细节和整体质量上取得了显著的进展。
在自然语言处理领域,扩散模型也有着广泛的应用,特别是在文本生成与翻译任务中。通过结合生成式预训练模型,扩散模型能够在文本生成中提供更高的灵活性和控制力。其基本原理是通过扩散模型的逆过程,从噪声中逐步生成符合目标分布的文本数据。
扩散模型可以通过调整生成过程中的条件设置来实现文本生成的可控性。例如,在文本翻译任务中,扩散模型可以通过引入语言对之间的翻译条件,从而生成更准确和自然的翻译结果。这种方法不仅可以用于文本生成和翻译,还可以扩展到其他文本处理任务,如文本补全、文本润色等。通过将扩散模型与现有的自然语言处理技术相结合,可以显著提高文本生成的效果和效率。







