

中文命名实体识别(Named Entity Recognition, NER)初探

在图像生成技术日益普及的今天,Diffusion Model以其生成高质量相似图像的能力而备受关注。本文将深入探讨Diffusion Model的工作原理、应用实例及其在实际中的实现方法,并结合Stable Diffusion、DALL-E等模型,分析其背后的共同逻辑和技术挑战。
Diffusion Model是一种新兴的图像生成模型,其基本思想是通过逐步去除噪声的过程来生成图像。这种模型的特殊之处在于,它能够在保持图像细节的同时,生成出高质量的图像,广泛应用于图像生成、视频生成等领域。
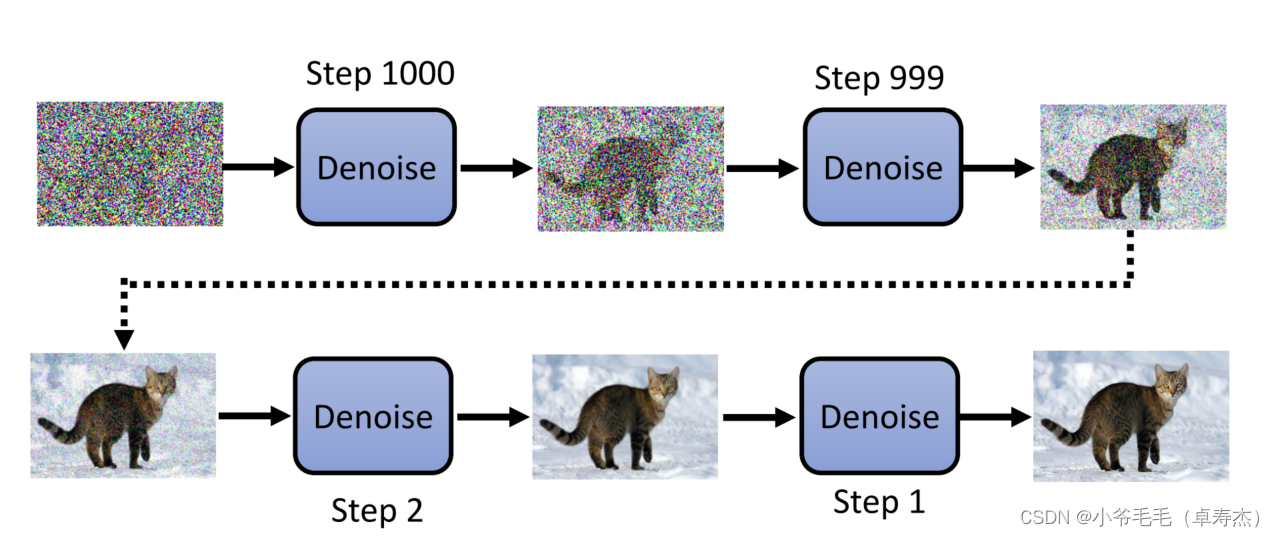
Diffusion Model的生成过程类似于冲洗照片,首先需要一个起始的噪声图像,然后通过多次去噪处理逐步显现出图像细节。每一步去噪都使用相同的Denoise Model,并通过输入当前的Step数让模型判断噪声程度,以便进行更精细的去噪操作。
Denoise Model内部首先会通过一个Noise Predictor模块预测当前图像的噪声,然后对初步去噪的图像进行修正,通过进一步减去噪声达到去噪效果。
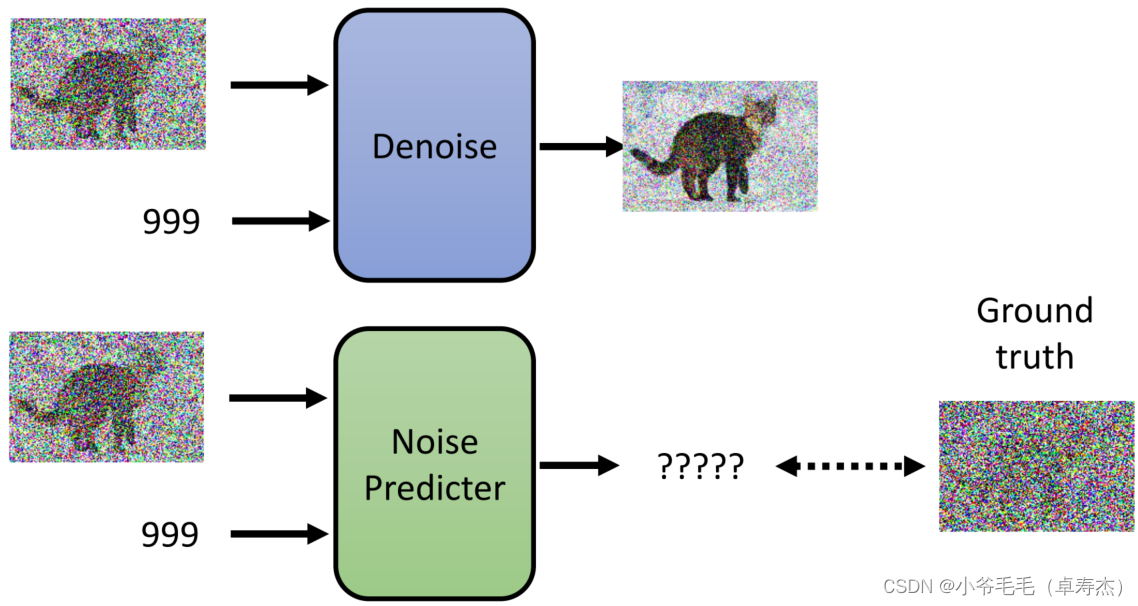
训练Noise Predictor需要利用监督学习方法,需要有Ground truth噪音作为标签。通过模拟扩散过程,随机产生噪音并加到原始图像中,得到一系列加噪后的图像和对应的Ground truth噪音用于训练。
Diffusion Model还可以用于文本生成图像,即Text-to-Image。通过将文本信息输入到Noise Predictor中,模型可以根据文本提示生成相应的图像。
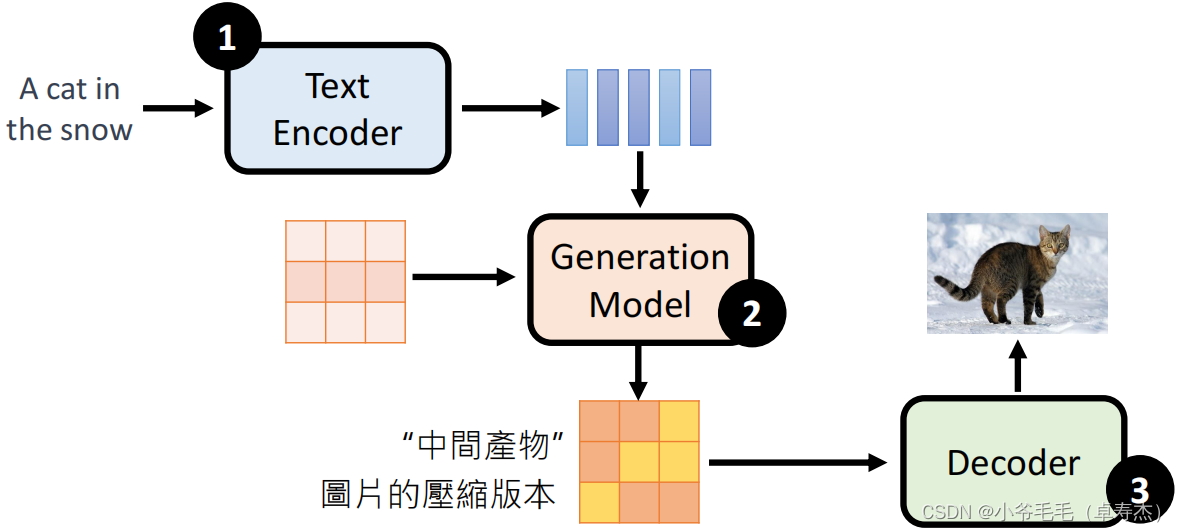
这些模型都使用了Text Encoder、Generation Model和Decoder三个模块。首先通过Text Encoder将文本编码为表征向量,然后通过Generation Model生成图像表征向量,最后通过Decoder将其解码为图像。
Stable Diffusion是一个开源的Diffusion Model,支持多模态输入,使用Denoising U-Net和交叉注意力机制来生成图像。它还使用预训练的通用VAE来处理输入图像。
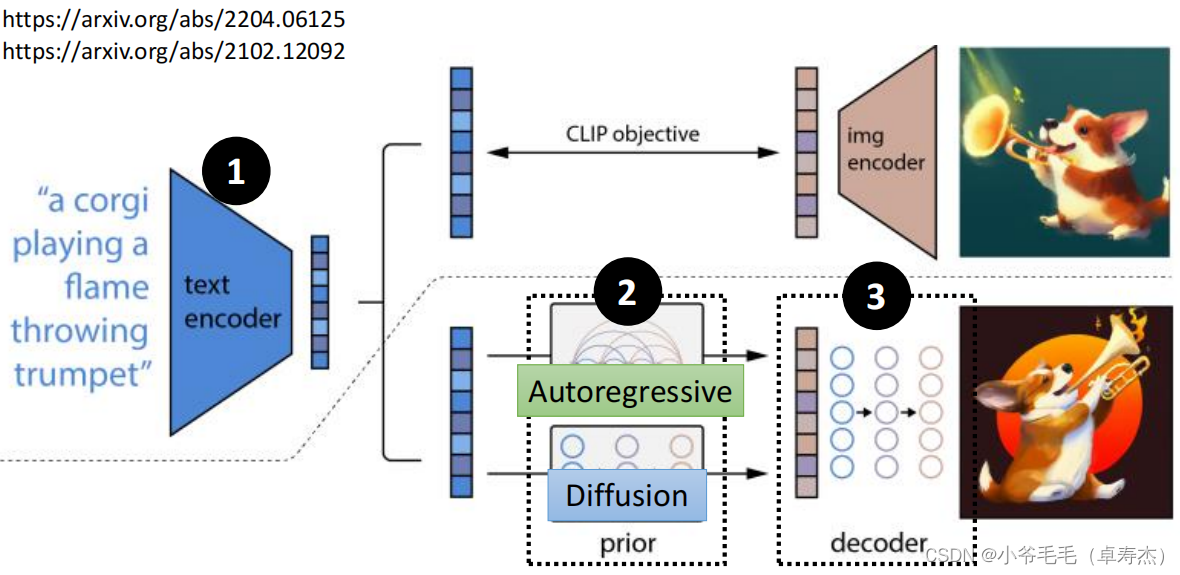
DALL-E利用CLIP方法实现文本与图像的对齐,通过Autoregressive模型或Diffusion生成图像表征向量,最后通过解码器生成最终图像。
Imagen采用T5模型作为文本编码器,并使用U-Net结构的Text-to-Image Diffusion Model,通过Efficient U-Net优化来减少显存占用和提高推理速度。
在生成特定领域图像时,Dreambooth和LoRA是两种有效的方法。Dreambooth通过利用类别的先验保护损失,生成多样的实例,而LoRA则通过优化低秩分解矩阵来微调神经网络。
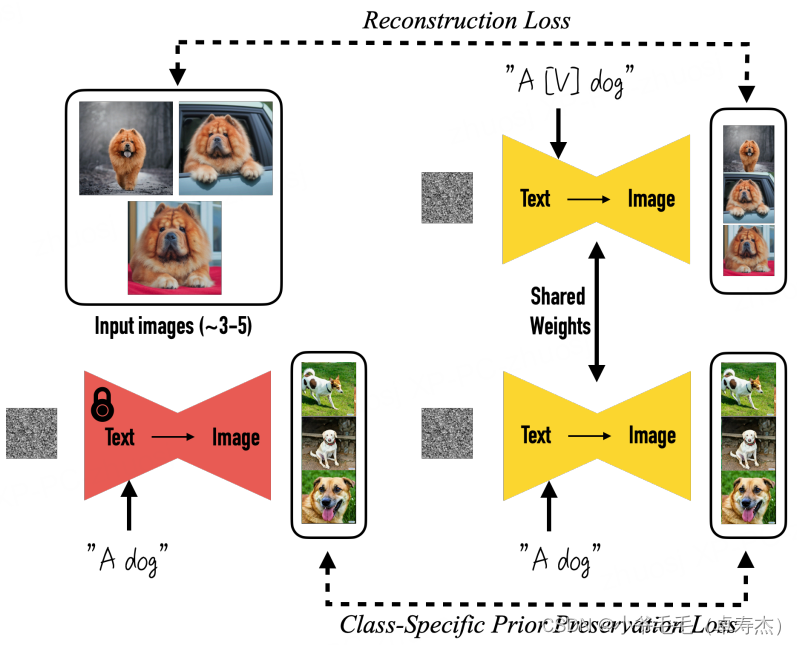
Dreambooth在微调模型时同时输入特定对象的名称和类别的文本提示,并应用类别的先验保护损失,以保持生成图像的多样性。
LoRA通过仅优化低秩矩阵,使得训练更加高效,并且可以在不影响推理延迟的情况下部署。这种方法与现有的模型训练方法兼容,适合小规模的概念学习。
通过Dreambooth和LoRA微调Stable Diffusion模型,可以生成出小鹏P7汽车的图像。在经过微调的模型中,我们可以看到该模型能够一定程度上学习到小鹏P7汽车的外观特征。

使用开源的Stable Diffusion模型,通过LoRA进行微调,能够生成出与宝可梦相关的卡通形象。这种方法展示了LoRA在生成特定概念图像中的有效性。
以下是使用Python实现Diffusion Model的示例代码:
from diffusers import StableDiffusionPipeline
import torch
pipe = StableDiffusionPipeline.from_pretrained("IDEA-CCNL/Taiyi-Stable-Diffusion-1B-Anime-Chinese-v0.1", torch_dtype=torch.float16)
model_path = "souljoy/sd-pokemon-model-lora-zh"
pipe.unet.load_attn_procs(model_path)
pipe.to("cuda")
pipe.safety_checker = lambda images, clip_input: (images, False)
prompt = "粉色的蝴蝶,小精灵,卡通"
image = pipe(prompt, num_inference_steps=50, guidance_scale=7.5).images[0]
image答:Diffusion Model通过逐步去噪生成图像,而GANs通过生成器与判别器的对抗训练生成图像。Diffusion Model更擅长生成细节丰富的图像。
答:可以通过优化模型结构、减少计算复杂度以及使用高效的硬件设备来提高生成效率。
答:LoRA可以与prefix-tuning等其他方法结合,通过优化低秩矩阵实现不同任务的快速切换,适用于多任务学习场景。
通过对Diffusion Model的深入探讨和实际应用示例,我们可以看到其在图像生成领域的巨大潜力。随着技术的不断发展,Diffusion Model将在更多的应用场景中发挥重要作用。





