

文心一言写代码:代码生成力的探索

RAG(Retrieval Augmented Generation,检索增强生成)是利用外部数据进行自然语言处理任务的一种强大方法。RAG 系统在处理用户提出的问题时,通过检索相关数据并使用这些数据作为上下文,生成更准确的回答。GLM-4 模型在 RAG 系统中扮演了核心角色,它提供了强大的语义理解能力,用于处理复杂的自然语言输入。
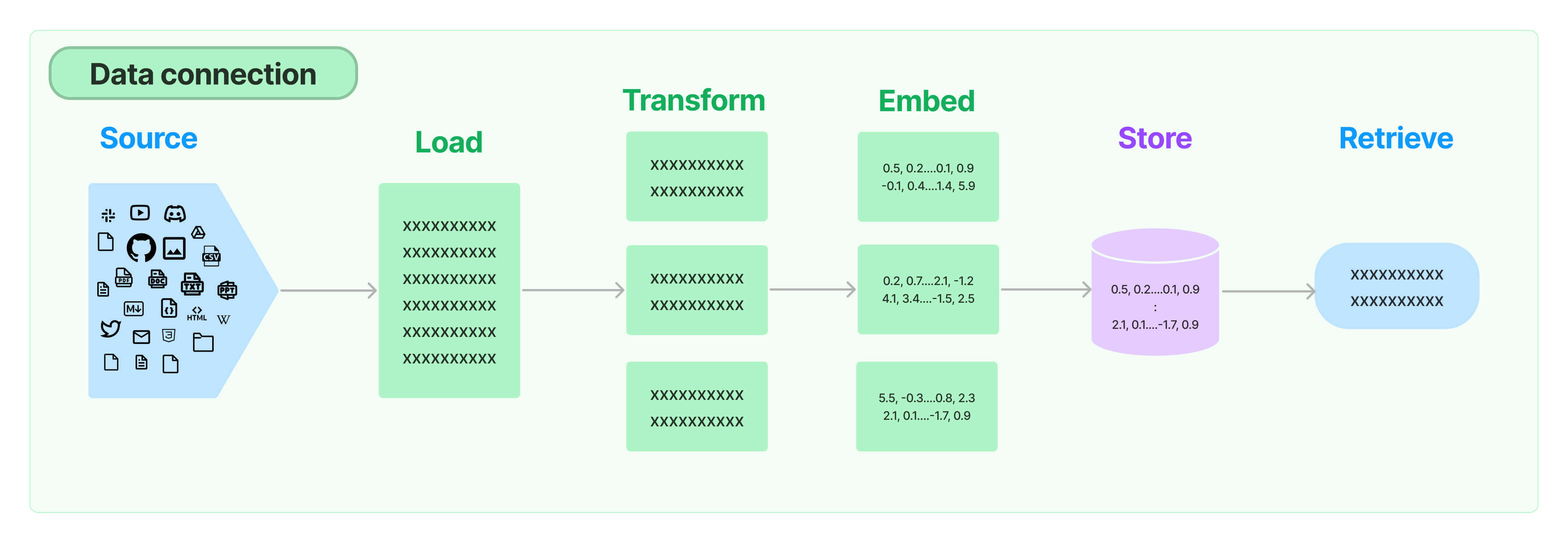
文档加载器是 RAG 系统中的重要组件。它负责从各种格式的文档中提取数据。LangChain 提供了超过 100 种不同的文档加载器,支持 CSV、HTML、PDF、DOC 等格式。这些加载器能够快速解析文档内容,使得 RAG 系统可以高效地获取所需信息。
from langchain_community.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path='ordersample.csv')
data = loader.load()通过上述代码,我们可以轻松加载 CSV 文件中的数据。这些数据随后可以用于进一步的处理和分析。
在处理长文档时,需要将其分割为较小的块,以便更好地适应语言模型的上下文窗口。LangChain 提供了多种文本分割器,例如递归分割器、HTML 分割器和 Markdown 分割器等。使用这些分割器可以确保文本块具有适当的大小和结构。
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=200, add_start_index=True
)
all_splits = text_splitter.split_documents(data)通过上面的代码,我们可以将文档分割为多个块,以便在后续步骤中进行处理。
嵌入模型是将文本转换为数值向量的工具,使得计算机可以更好地理解和处理自然语言。GLM-4 支持多种嵌入模型,这些模型能够捕捉文本的语义特征,并用于相似度计算和信息检索。
LangChain 提供了超过 25 种嵌入模型的集成,可以根据需要选择合适的模型。例如,使用 Hugging Face 提供的嵌入模型可以实现高效的文本向量化。
向量数据库用于存储和检索嵌入向量。LangChain 与多种向量数据库集成,包括 Milvus 和 FAISS。使用向量数据库可以快速检索与查询相似的文档片段,从而提高 RAG 系统的响应速度和准确性。
from langchain_community.vectorstores import FAISS
vector = FAISS.from_documents(all_splits, bgeEmbeddings)通过将分割后的文档向量化并存储在向量数据库中,RAG 系统可以更高效地进行数据检索。
在开发 RAG 系统时,首先需要创建 GLM4 模型对象。该模型提供了强大的自然语言处理能力,是 RAG 系统的核心组件。
ZHIPUAI_API_KEY = "..."
llm = ChatZhipuAI(
temperature=0.1,
api_key=ZHIPUAI_API_KEY,
model_name="glm-4",
)接下来,使用文档加载器加载用户特定领域的数据,如 ordersample.csv 文件。此数据将用于回答用户的特定问题。
使用文本分割器对加载的文档进行分割,以适应模型的上下文窗口限制。分割后的文本块可以更好地与模型交互。
使用嵌入模型对分割后的文档进行向量化,然后存储在向量数据库中。这样可以在需要时快速检索相关信息。
通过向量库进行检索,找到与用户查询最相关的文档片段。然后将这些片段传递给 GLM4 模型,生成更准确的回答。
使用检索链将向量库检索和 GLM4 模型结合,根据用户的问题生成相应的答案。通过这种方式,RAG 系统能够高效地处理复杂的自然语言查询。
RAG 系统结合了文档检索和生成技术,能够提供更精准的自然语言处理能力。通过使用 GLM-4 和相关工具,开发者可以构建强大的智能问答系统。在实际应用中,语料的结构化和向量化处理是至关重要的,能够显著提高系统的性能和准确性。
问:RAG 系统的主要优势是什么?
问:如何选择合适的嵌入模型?
问:向量数据库在 RAG 系统中有哪些应用?






