

API是什么?深入解析API及其应用

在文本生成领域,使用Hugging Face的Transformers库进行文本生成是一种常见的方法。在这个过程中,model.generate函数提供了多种灵活的参数设置,使我们能够控制生成文本的方式和质量。本文将详细介绍如何使用model.generate及其相关参数,以实现高效的文本生成。
model.generate函数支持多种生成方法,包括贪婪搜索、束搜索和采样等。这些方法各有优缺点,适用于不同的场景和需求。下面我们将逐一介绍这些方法的工作原理。
贪婪搜索是一种简单直接的生成方法。在每个时间步中,它选择概率最高的词作为下一个输出。这种方法的优点是速度快,同时也能确保选择的词是当前最优的。然而,贪婪搜索可能会忽略一些低概率但在后续步骤中可能更优的词。
束搜索通过在每个时间步中选择多个(称为束)最有可能的词,从而在一定程度上克服了贪婪搜索的局限性。虽然束搜索能找到更好的解,但它可能会生成重复的词。通过设置参数如num_beams和early_stopping等,我们可以微调束搜索的行为。
采样方法通过在概率分布中随机选择词汇,使生成结果更加多样化。常用的采样方法包括Top-k和Top-p采样。这些方法通过参数如temperature、top_k和top_p进行控制。
Top-k采样方法在每个时间步中仅考虑前k个最有可能的词,从而限制候选词的数量。这种方法可以避免生成低概率的无意义词。
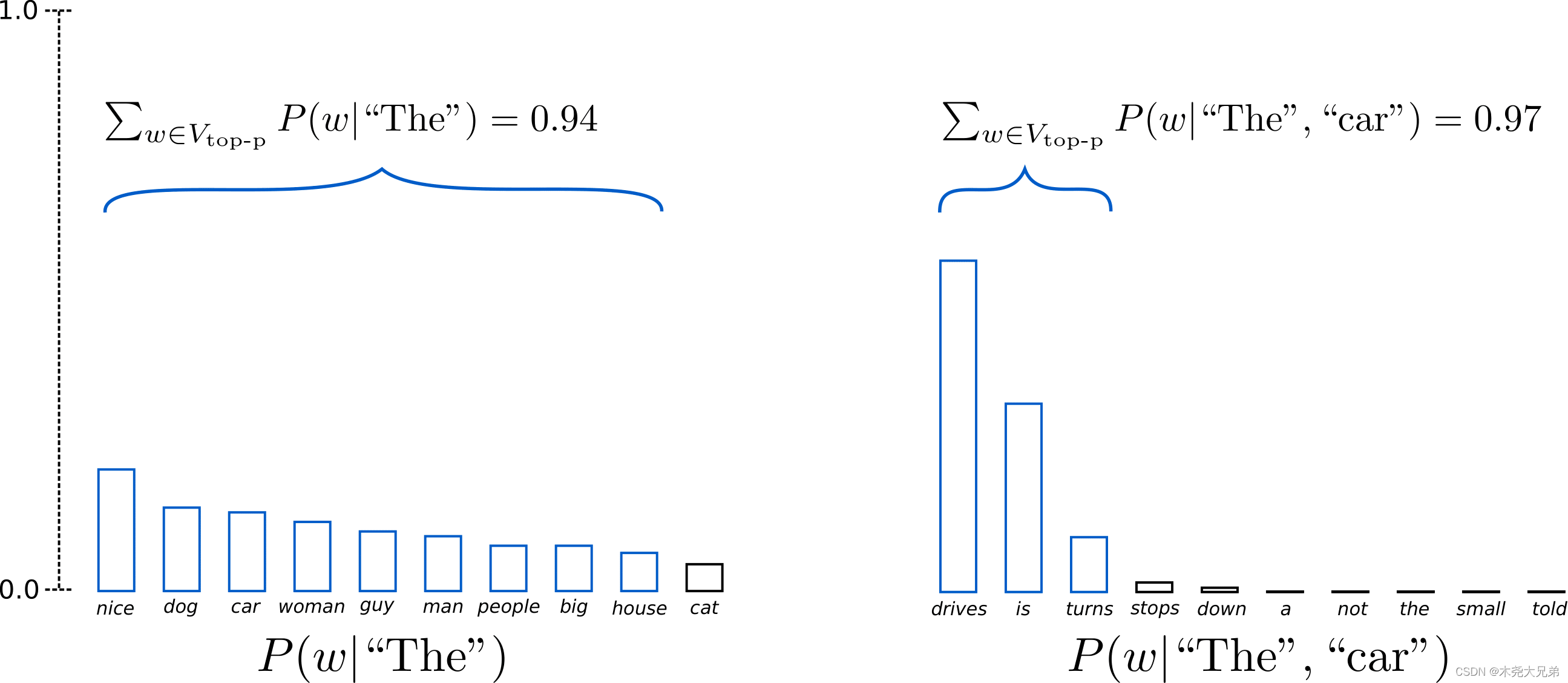
Top-p采样(也称为核采样)通过累积概率,动态调整候选词的数量。当下一个单词的概率不确定时,Top-p采样会增加候选词的数量,反之亦然。
model.generate函数提供了多种参数来控制生成过程。以下是一些关键参数的解释:
inputs参数是一个张量,代表生成的初始提示。对于仅解码器的模型,输入应为input_ids;而对于编码-解码模型,输入可以更加多样化。
max_length和min_length参数控制生成序列的长度。通过调整这些参数,我们可以限制生成文本的最大和最小长度。
do_sample参数决定是否启用采样方法。如果设置为True,则使用采样方法,否则使用贪婪搜索。
num_beams参数用于控制束搜索中的束数量。设置为1表示不进行束搜索。
temperature参数影响采样的随机性。较低的值(小于1)会使模型更倾向于选择高概率词,而较高的值会增加生成的多样性。
top_k和top_p参数用于控制Top-k和Top-p采样的行为。通过调节这些参数,我们可以灵活地影响生成结果的多样性和质量。
通过对model.generate的参数进行合理配置,我们可以产生不同风格和长度的文本。生成的输出可以是一个张量或ModelOutput对象,具体取决于配置。
在不同的应用场景中,我们可以根据需求选择合适的生成策略。例如,在需要生成固定长度文本的场景下,束搜索可能是更好的选择。而在对话或故事生成等开放式生成任务中,采样方法则可能更为适用。
model.generate函数?model.generate是Hugging Face Transformers库中的一个重要函数,用于通过指定的生成策略生成文本。
选择生成策略应根据具体的生成需求和场景。例如,束搜索适合生成固定长度的文本,而采样方法更适合开放式生成任务。
可以通过调节temperature、top_k和top_p等参数来控制生成文本的多样性。这些参数影响生成过程中候选词的选择。
可以通过设置no_repeat_ngram_size参数来限制重复词的生成,从而避免文本中出现重复。
model.generate的输出有什么形式?model.generate的输出可以是一个序列张量,也可以是ModelOutput对象,这取决于配置中的返回选项。
通过本文的介绍,希望能帮助您更好地理解和使用model.generate函数,实现高效的文本生成。






