

豆包 Doubao Image API 价格全面解析

在当前技术快速发展的时代,Grok 作为一款强大的开源模型,提供了本地化知识库的构建能力。本文将深入探讨如何部署 Grok 本地知识库以及其在多种应用场景中的实际价值。
Grok 本地知识库是一个可以在本地环境中部署的大型语言模型,旨在帮助用户管理和使用本地化数据。通过将企业私有数据导入到知识库中,用户可以实现高效的数据管理和复杂任务处理。这种本地化的解决方案不仅提高了数据安全性,还增强了数据处理的灵活性。
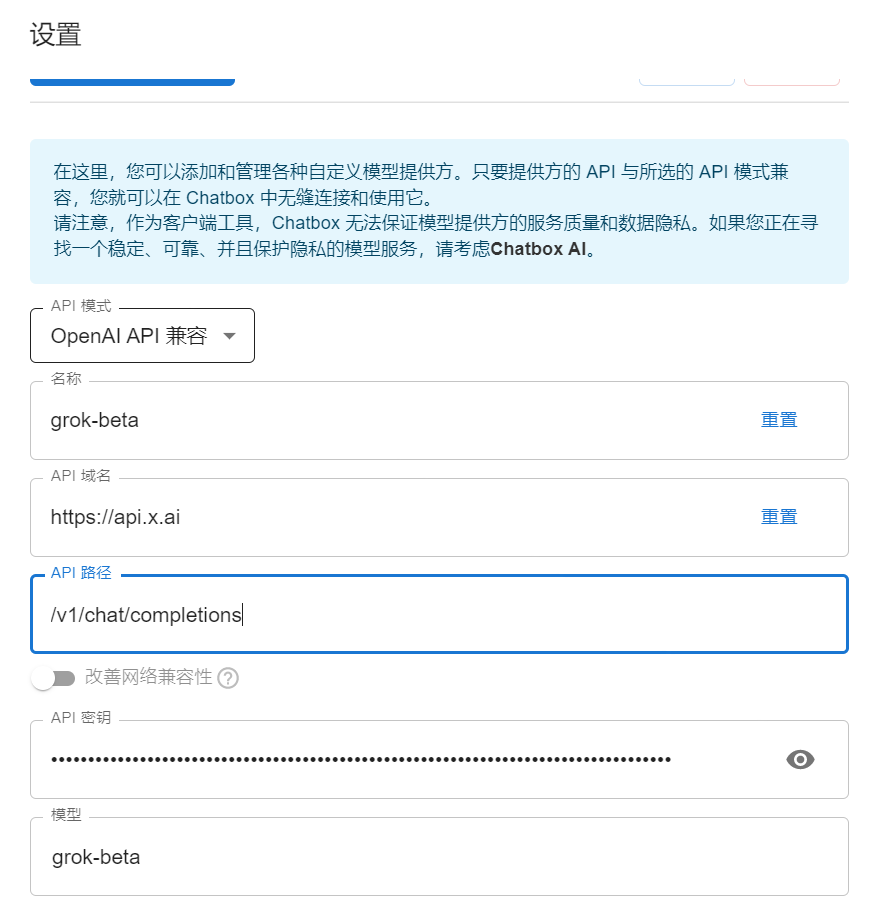
部署 Grok 本地知识库涉及多个步骤,每一步都需要仔细配置,以确保系统的稳定运行。以下是详细的部署指南。
在部署之前,首先需要准备好运行环境,包括必要的硬件和软件资源。Grok 对硬件资源有一定要求,用户需要确保有足够的存储空间和计算能力。
import torch
from transformers import GrokModel, GrokTokenizer
tokenizer = GrokTokenizer.from_pretrained('grok-base')
model = GrokModel.from_pretrained('grok-base')
inputs = tokenizer("Hello, how are you?", return_tensors="pt")
outputs = model(**inputs)
Grok 本地知识库被广泛应用于多个领域,其强大的功能为用户提供了多种解决方案。
企业可以将内部数据导入 Grok 知识库,实现数据的集中管理和高效检索。通过这种方式,企业不仅能够提高数据的利用率,还能确保数据的安全性。
利用 Grok 的自然语言处理能力,可以构建智能客服机器人。这些机器人可以快速响应用户查询,并提供精准的答案,从而提高客户满意度。

Grok 能够自动生成高质量的内容,如文章、报告和文案。这对于需要大量内容创作的行业来说,极大地提高了工作效率。
为了确保 Grok 本地知识库在实际应用中的高效运行,用户需要对其进行优化。
通过优化数据索引结构,可以显著提高数据检索速度。推荐使用向量索引技术,以加速复杂查询的处理。
调整模型参数以适应特定的应用场景,从而提高模型的响应速度和准确性。例如,可以通过微调模型来增强其在特定领域的表现。
利用 GPU 加速计算,可以大幅提高模型的处理速度。尤其是在处理大规模数据时,GPU 能够有效降低计算时间。
随着技术的不断进步,Grok 本地知识库也在不断更新和优化。未来,Grok 将进一步增强其处理能力和扩展性,以满足更多应用场景的需求。
未来的 Grok 版本将支持多模态数据处理,能够同时处理文本、图像和语音数据,从而提供更全面的解决方案。
在数据安全方面,Grok 将引入更多的安全机制,确保用户数据的隐私和安全。
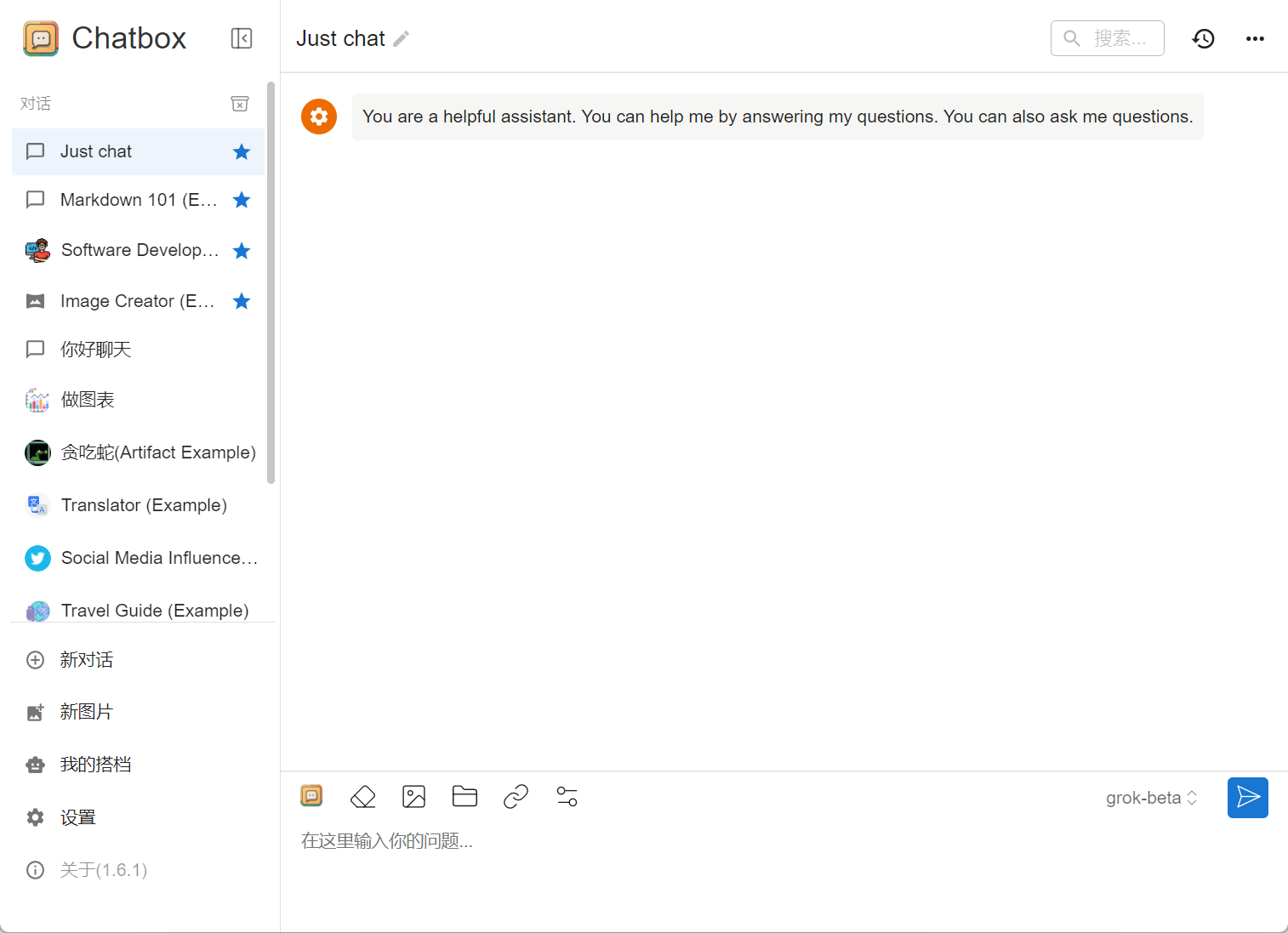
问:Grok 本地知识库对硬件有什么要求?
问:如何确保 Grok 知识库的数据安全?
问:Grok 支持哪些应用场景?
问:如何优化 Grok 的性能?
问:未来 Grok 的发展方向是什么?
通过本篇文章,希望您对 Grok 本地知识库有了更深入的了解,并能在实际应用中充分发挥其潜力。





